DBA专栏
01-MySQL基础入门
02-MySQL基础入门-部署与管理体系
03-MySQL-基础入门-用户与权限
04-MySQL基础入门-索引
相信可能就有无限可能
-
+
首页
04-MySQL基础入门-索引
## 1.索引是什么 ### 1.0.数据结构与树 - 基本概念 ```sql #数据结构: 互相存储一到多种关系的数据集合和关系组成 #分类: 数组,栈,链表,队列,树,图,堆,散列表 #树-->树状图 由n(n>=1)个有限结点组成一个具有层次关系的集合。一种非线性存储结构,存储的是具有“一对多”关系的数据元素的集合。 #术语 节点深度:对任意节点x,x节点的深度表示为根节点到x节点的路径长度。所以根节点深度为0,第二层节点深度为1,以此类推 节点高度:对任意节点x,叶子节点到x节点的路径长度就是节点x的高度 树的深度:一棵树中节点的最大深度就是树的深度,也称为高度 父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点 子节点:一个节点含有的子树的根节点称为该节点的子节点 节点的层次:从根节点开始,根节点为第一层,根的子节点为第二层,以此类推 兄弟节点:拥有共同父节点的节点互称为兄弟节点 度:节点的子树数目就是节点的度 叶子节点:度为零的节点就是叶子节点 森林:m颗互不相交的树构成的集合就是森林 ``` - 树的种类 ```sql 1.无序树 - 树的任意节点的子节点没有顺序关系。 2.有序树 - 树的任意节点的子节点有顺序关系。 3.二叉树 - 树的任意节点至多包含两棵子树。 - 二叉树遍历:从二叉树的根结点出发,按照某种次序依次访问二叉树中的所有结点,使得每个结点被访问一次,且仅被访问一次。 4.AVL树:平衡二叉查找树,增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。 5.红黑树: - 每个节点都带有颜色属性的二叉查找树,颜色或红色或黑色。 性质1. 节点是红色或黑色。 性质2. 根节点是黑色。 性质3. 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的 红色节点) 性质4. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。 使用场景: 红黑树多用于搜索,插入,删除操作多的情况下 红黑树应用比较广泛: 1. 广泛用在C++的STL中。map和set都是用红黑树实现的。 2. 著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块。 3.epoll在内核中的实现,用红黑树管理事件块 4.nginx中,用红黑树管理timer等 6.B树 一棵m阶B树(balanced tree of order m)是一棵平衡的m路搜索树。它或者是空树,或者是满足下列性质的树: 1、根结点至少有两个子女; 2、每个非根节点所包含的关键字个数 j 满足:m/2 - 1 <= j <= m - 1; 3、除根结点以外的所有结点(不包括叶子结点)的度数正好是关键字总数加1,故内部子树个数 k 满足:m/2 <= k <= m ; 4、所有的叶子结点都位于同一层。 7.B+树 ##定义 B+树是B树的一种变形形式,B+树上的叶子结点存储关键字以及相应记录的地址,叶子结点以上各层作为索引使用。一棵m阶的B+树定义如下: (1)每个结点至多有m个子女; (2)除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女; (3)有k个子女的结点必有k个关键字。 ##重要特性 链表指针(重要特性):B+树的查找与B树不同,当索引部分某个结点的关键字与所查的关键字相等时,并不停止查找,应继续沿着这个关键字左边的指针向下,一直查到该关键字所在的叶子结点为止。 ##特点 更适合文件索引系统 ##原因 增删文件(节点)时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存 储,这样可很好提高增删效率 ##使用场景: 连续的数据能够进行较快的定位和访问,减少查找时间,减少IO操作。他广泛用于文件系统及数据库中,如: Windows:HPFS 文件系统 Mac:HFS,HFS+ 文件系统 Linux:ResiserFS,XFS,Ext3FS,JFS 文件系统 数据库:ORACLE,MYSQL,SQLSERVER 等中 B树:有序数组+平衡多叉树 B+树:有序数组链表+平衡多叉树 ##B*树 B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针; ``` ### 1.1.索引简介 #### 1.1.0.基础概念补充 1.磁盘相关 ```sql 系统从磁盘读取数据到内存以磁盘块(block)为基本单位,一个磁盘块中数据会一次性读取出来(不是需要什么取什么) #什么是磁盘块(block) 1.操作系统与磁盘交流最小单位(磁盘块),软件概念。扇区是对硬盘而言,硬件概念。 2.磁盘读写最小单位扇区(物理区域,512byte或4K) -->磁盘块(block)=扇区x2^n(是连接操作系统与扇区的桥梁).软件概念 3.如何查看磁盘块 shell>df >tune2fs -l /dev/vda1|grep Block Block count: 11796219 Block size: 4096 #一般为4096字节.8个扇区组成 Blocks per group: 32768 InnoDB存储引擎有页(Page)的概念,页是磁盘管理的最小单位.InnoDB默认16KB,参数innodb_page_size控制 mysql> show variables like 'innodb_page_size'; ``` 2.InnoDB表结构 (1)InnoDB逻辑存储结构 MySQL表中的所有数据被存储在一个空间内,称之为表空间(.ibd文件),表空间内部又可以分为段(segment)、区(extent)、页(page)、行(row),逻辑结构如下图: 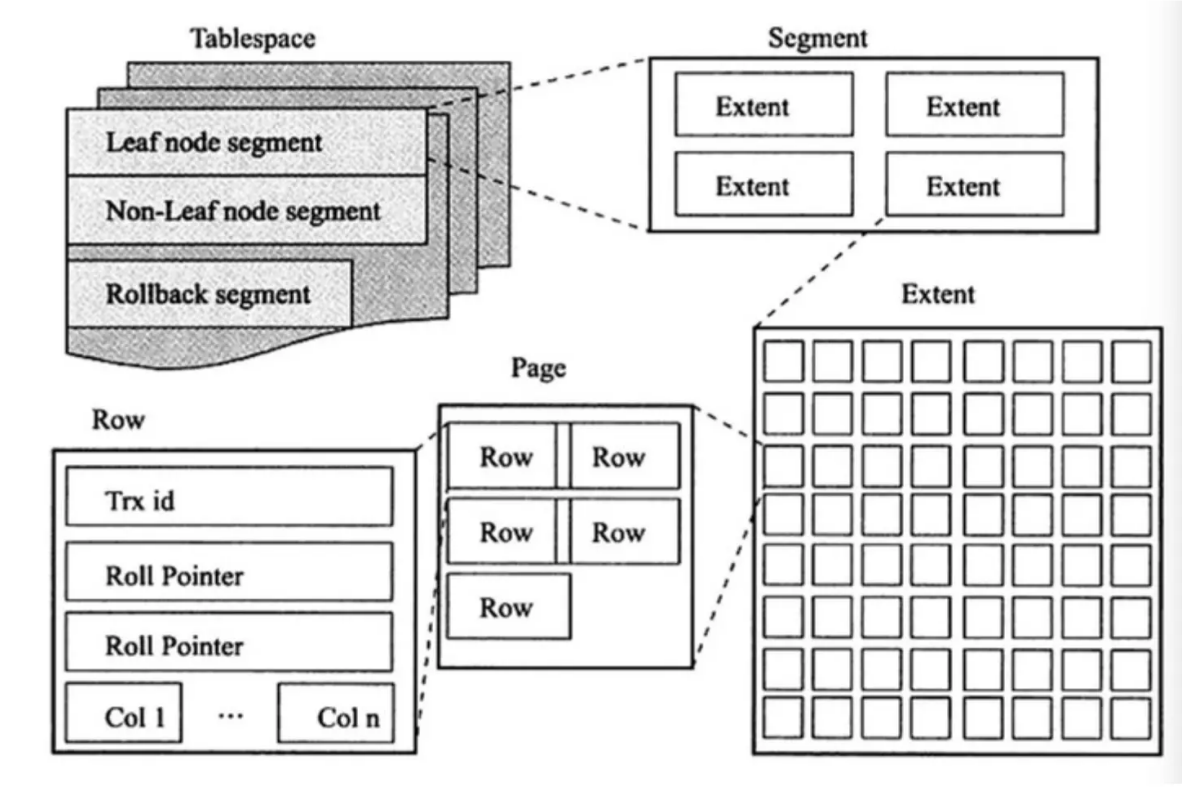 ```sql - 段(segment):表空间由不同的段组成 1.数据段:B+树 索引及数据 叶子节点 2.索引段:非叶子节点 3.回滚段:存储undo日志,事务失败回滚和未提交之前的数据.(下一节) - 区(extent) 1.连续的页组成(默认一页16K),每个区固定大小1MB。默认不压缩,一个区64个连续的页 - 页(page) 1.InnoDB存储引擎的最小管理单位,默认16KB 2.页类型:数据页,undo页,系统页... - 行(row) 1.对应表中行记录 2.每页存储最多行记录规定 16KB/2-200 = 7992行 (每个记录最少2字节,每个页预留200字节,硬性规定) 3.每个页最少存储2行,虚拟记录,限定记录边界,最大虚拟记录和最小虚拟记录 ``` #### 1.1.1.索引用处和索引种类? 索引: - 帮助MySQL高效获取数据的数据结构 - 存储在文件系统 - 文件存储格式与存储引擎有关 - 索引文件结构 - hash:无序,适合等值查询.范围用不了.(Mysql-AHI,Memory存储引擎) - 二叉树与红黑树:树深度过深造成IO次数变多,读取效率不行 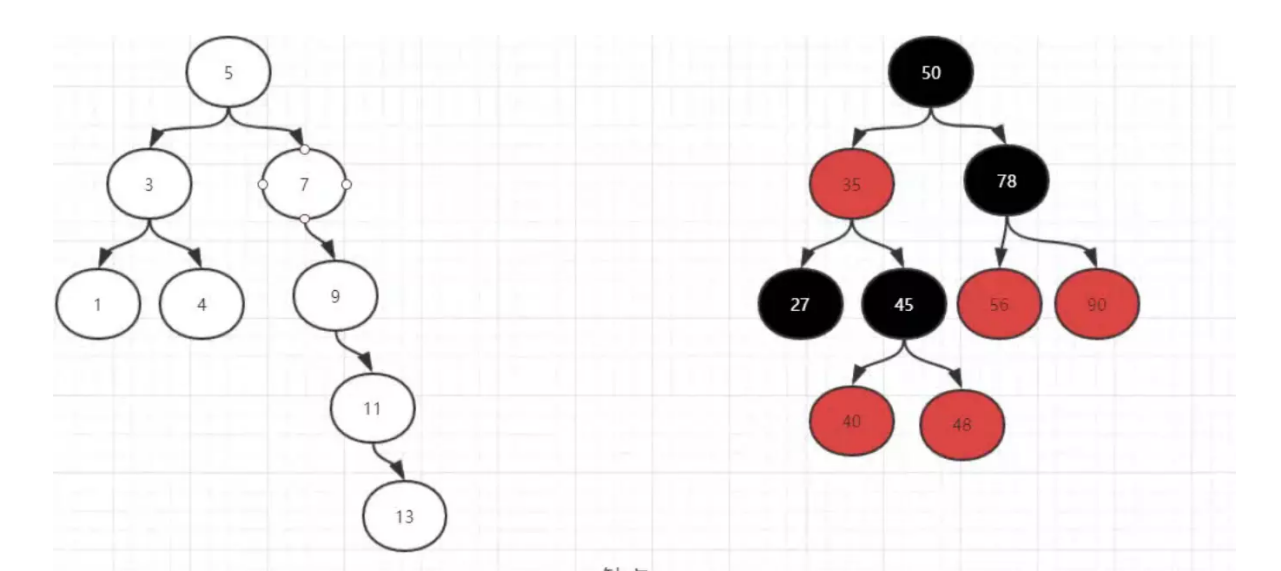 - B树 ```sql #说明 (1)不是二叉搜索,而是m叉搜索 (2)叶子节点,根节点,非叶子节点:都存储数据 (3)每个节点占用一个磁盘块,一个节点两个关键字和三个指针,指针指向磁盘块地址(一般为4K)。 p1指针小于16,p2 16-34,p3 大于34 (4)完美利用局部性原理,适合做索引. #知识补充-局部性原理 逻辑: (1)内存IO(2-12GB/S,延时30-100ns)>磁盘IO(50MB->2GB/S,延时10us-1ms) (2)磁盘预读: 数据库磁盘读取不是按需,而是按页,一次读取一页数据,未来数据在此页中,避免未来磁盘IO。(通过一页是4K,MySQL中默认一页是16K) (3)局部性原理:软件设计尽量遵循"数据读取集中"与"使用相邻数据",磁盘预读能充分利用IO #查找关键字过程 1.根节点找到磁盘块1,读入内存,[IO操作一次] 2.比较关键字29,找到磁盘块指针p2 3.根据p2指针-->磁盘块3,读入内存 [IO第二次] 4.找到p2指针 5.比较P2指针-->磁盘块8--》读入内存 [IO第三次] 6.8找到关键字29 #缺点 1.每个节点都有key和data,页存储空间有限,data大-->每个节点key数量小 2.查询不稳定,可能一次,没可能多次,数据量极大,查询深度深,IO次数多,影响性能 ``` 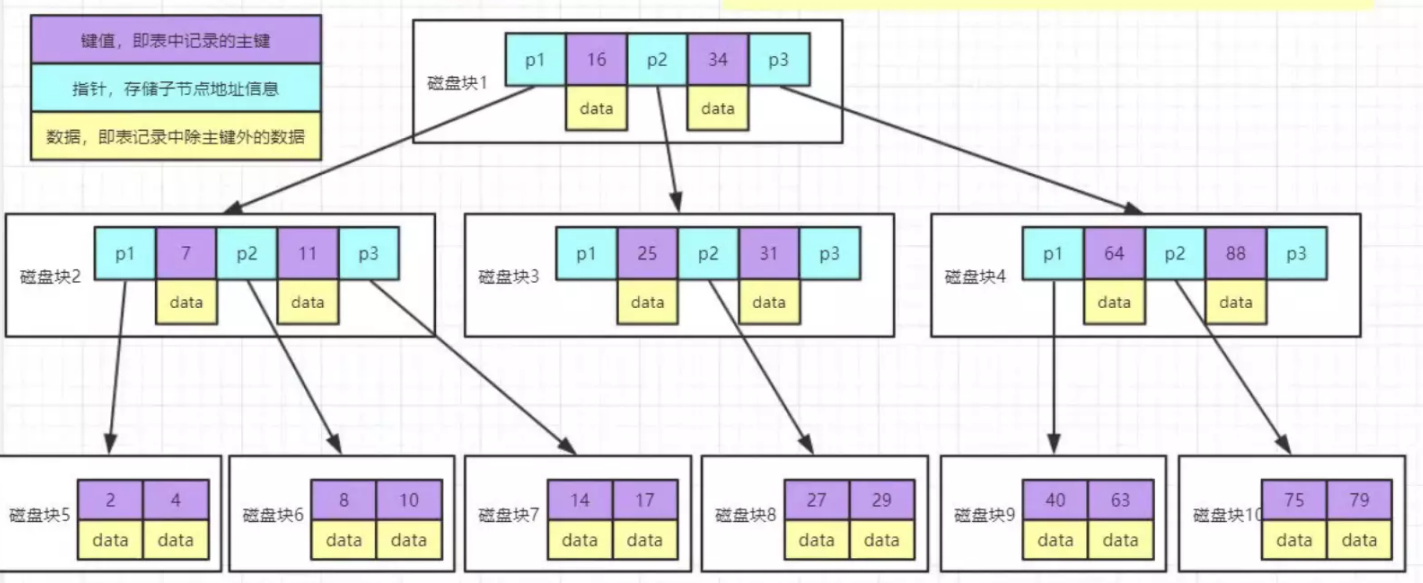 #### 1.1.2.InnoDB索引数据结构 B+树 - B+树 ```sql 在B树上做了一些优化,如下: 1.非叶子节点存储key,叶子节点存储key和数据 2.叶子节点两两链表连接(符合磁盘预读特性),顺序查询性能更高.不需要中序遍历. 3.所有数据存储在叶子节点中 这样设计带来比B树的优势特性 1.范围查找:定位min和max后,中间叶子节点,就是结果集,不用在中序回溯 2.叶子节点记录行数据,适合大数据量磁盘存储.非叶子节点存储记录PK,用于查询加速,适合内存存储。 3.非叶子节点仅存储key,相同内存,B+树存储更多索引,降低树的高度 假设每个磁盘块存储4个键值与指针信息,则B+Tree结构下图所示 ``` 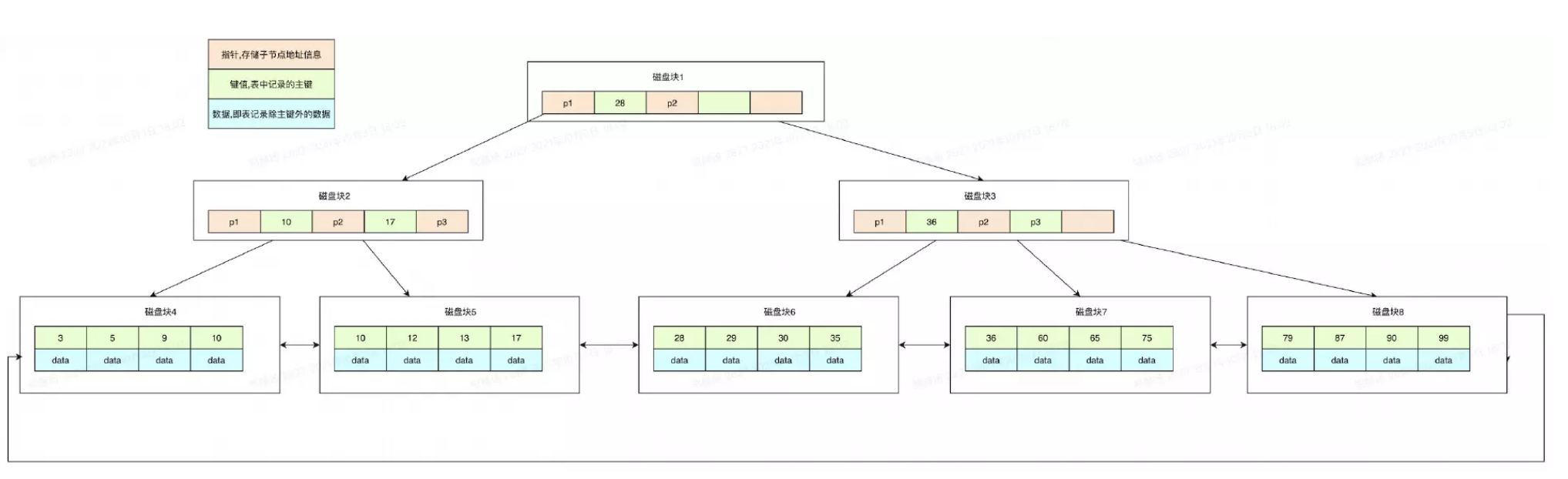 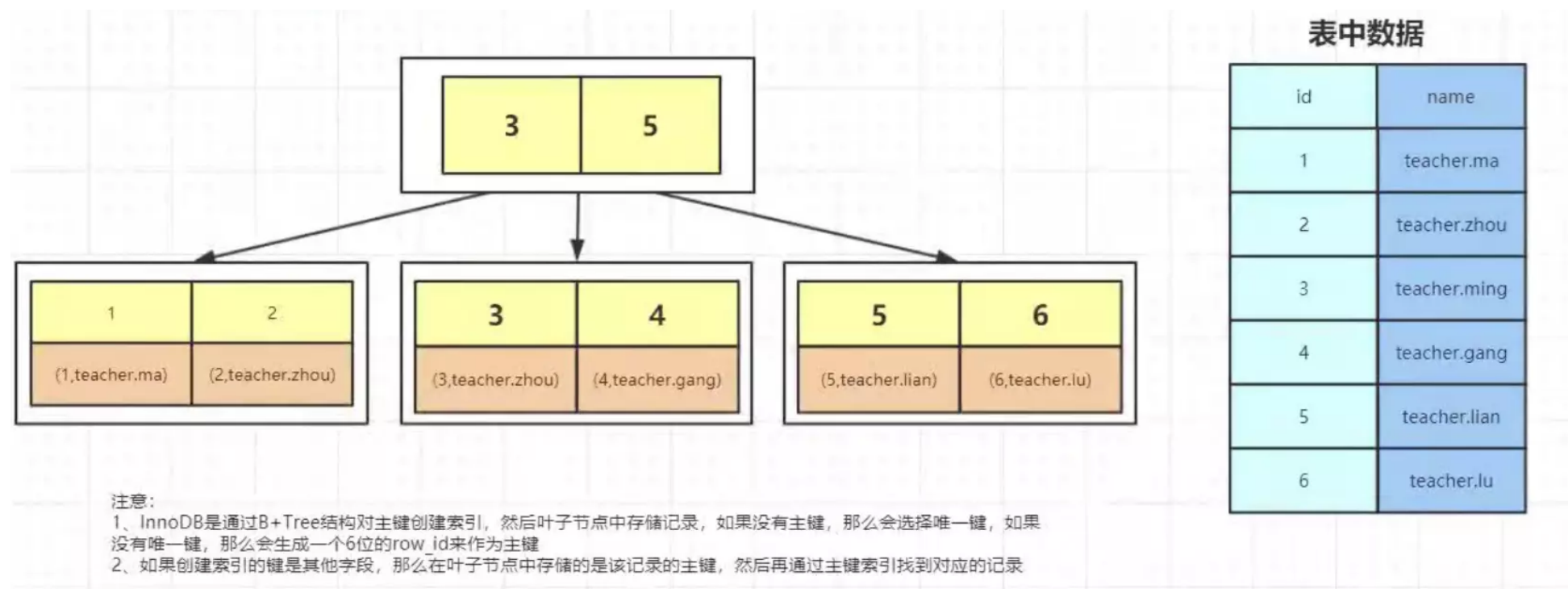 ```sql #InnoDB中的B+树索引 1.主键索引记录的是整行数据. 2.3-4次IO基本满足(一个磁盘块1000key,第一层1000,第二层1001,第三层1002,四层B+树几百亿数据)。InnoDB设计根节点常住内存,也就是查找某一行键值记录1-3次磁盘IO. 3.没有主键-->唯一键(不推荐)-->6位row_id作为主键(不推荐) 4.MySQL读取B+数索引数据:查找到数据行所在的页,通过数据库把也读入到内存,在内存中查找数据. #补充知识-为什么MySQL一般一页是16K 以聚簇索引为例: - 非叶子节点:主键+指针(假设主键ID为bigint,长度为8Byte,指针在Innodb源码为6B,一共14B),一页存储16K/14=1170(主键+指针) - 叶子节点:假设一行数据大小1K,一页存16K数据(一个叶子节点). 高度为2的B+树存储数据:1170*16=18720 高度为3的B+树存储数据:1170**1170*16=21902400(千万数据级别) 高度为4的B+树存储数据:1170**1170*1170*16=25625808000(百亿数据级别) 业务一行数据500B,存储的数据量级大概3层B+树大概在4KW左右,高于这个值也就是3次磁盘IO+一次内存节点(IO)(如果是二级索引就是6次IO),称为大表,4层的B+树。 ``` #### 1.1.3.InnoDB中索引分类 - 从存储类型分类 ```sql 聚簇索引(主键索引): 1.InooDB存储引擎表就是索引组织表:表中数据按照PK逻辑上顺序存放,物理并不连续. (叶子节点双向链表连接,页中记录也是双向链表维护)(物理存储是文件系统决定,大文件采用分层路由,小文件直接存放) 2.按照表的PK构建一颗B+树,非叶子节点存放指针和PK,叶子节点存放整条row记录。 3.聚簇索引定义了数据逻辑顺序,对范围查询优化特别快,那些数据页需要扫描. 辅助索引(二级索引) 1.手动创建,作为辅助查询条件(业务常用) 2.非主键索引存放的是键值(column)和主键ID(data),通过主键找到对应记录 3.回表:通过非聚簇索引查找记录要先找到主键,然后通过主键再到聚簇索引中找到对应的记录 行,这个过程被称为回表。(多增加查找完整一次树的IO,比如3次辅助索引树+3次聚簇索引树) ``` - 从功能分类 ```sql 1.主键索引:Primary key,唯一,非空非null,建议数字自增(有的业务会用uuid)。 (1)如果表设置主键(ID列),根据ID列生产聚簇索引 (2)如果没有设置主键,自动选择第一个唯一键列作为聚簇索引 (3)自动生成6字节的row_id 作为聚簇索引 2.唯一索引:索引列只能出现一次,value唯一. 3.普通索引:基本索引类型,没有唯一性限制。 4.全文索引:索引类型FULLTEXT(基本索引)-ES或者MongoDB 5.组合索引:多个索引列组成一个索引 6.覆盖索引:又称三星索引,select column与索引列完全对应 ``` - 优点 ```sql 1.减少了服务器需要扫描的数据量 2.帮助服务器避免排序和临时表 3.随机IO变成顺序IO ``` - 缺点 ```sql 1.提高查询速度,降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。索引文件也要更新 2.建立索引占用磁盘空间(大表多个组合索引),生产不超过8个索引. 3.数据列过滤因子过小(比如 1,0),索引没有什么效果 4.小表全表扫描更高效 ``` - 例子:一个包含了用户姓名和年龄的的数据表,假设主键是用户ID,聚簇索引的结构为(橙色的代表id,绿色是指向子节点的指针) ```sql 叶子节点中,为了突出记录,把(id, name, age)实际上是连在一起的,它们是构成一条记录的整体 ``` 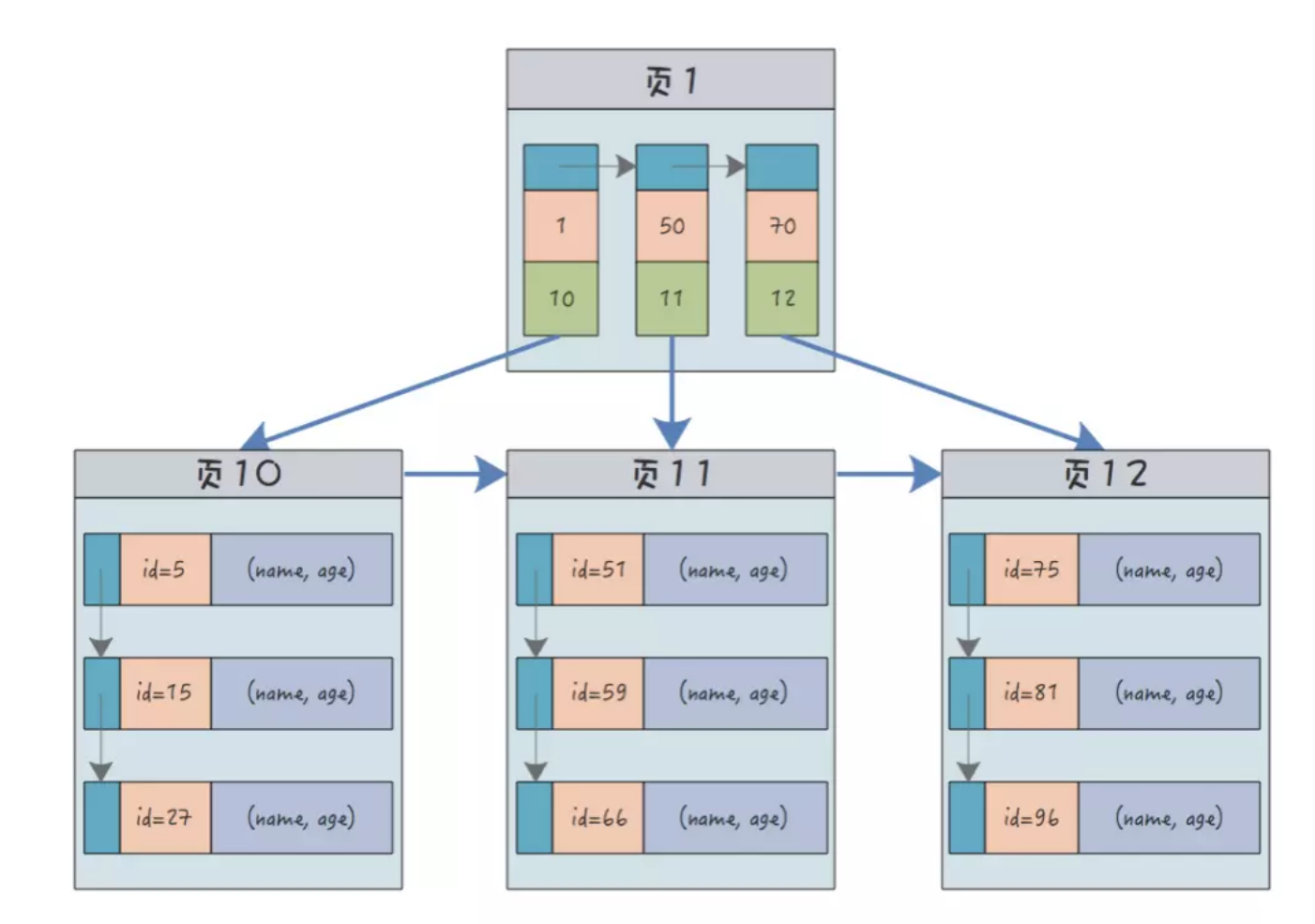 ```sql - 而一个非聚簇索引(以age为索引)的结构是: - 它的叶子节点中,不包含整个记录的完整信息,除了age字段本身以外,只包含当前记录的主键id。如果想要获取整行记录数据还需要再通过id号到聚簇索引中回表查询。 - 覆盖索引解决问题 select name,age from userinfo where age = 10 ; - 建立索引 (name,age) # id name age index age primary key id select name,age from userinfo where age = 10; ``` 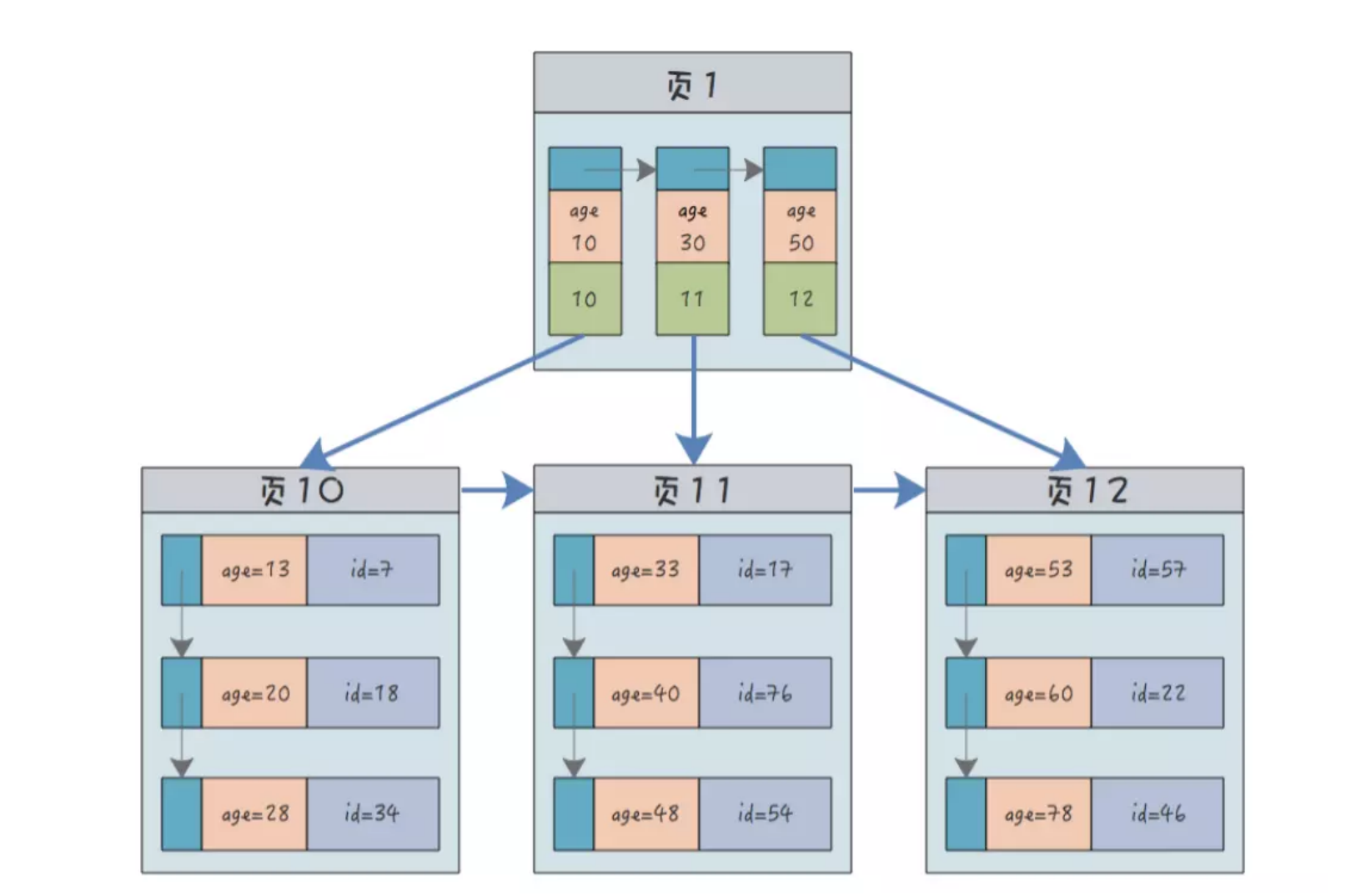 ### 1.2 索引使用 - 准备测试环境 MySQL8.0 单机 1c1G即可 ```sql set global log_bin_trust_function_creators =on; #设置参数 开启binlog,创建自定义函数可能会有安全隐患 开启这个参数 set SESSION log_bin_trust_function_creators =on; #或者在配置文件my.cnf中配置 [mysqld] log_bin_trust_function_creators=1 mysql> show variables like '%log_bin_trust_function_creators%'; +---------------------------------+-------+ | Variable_name | Value | +---------------------------------+-------+ | log_bin_trust_function_creators | ON | +---------------------------------+-------+ 1 row in set (0.00 sec) #总结:请注意,动态设置只对当前会话有效,服务器重启后会恢复到配置文件中的设置。要永久更改这个值,你应该编辑配置文件。 #生产中建议关闭。 create database school; #创建数据库 use school; #创建表 CREATE TABLE `app_user` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT '' COMMENT '昵称', `email` varchar(50) DEFAULT NULL COMMENT '邮箱', `phone` bigint DEFAULT NULL COMMENT '手机号', `gender` tinyint DEFAULT NULL COMMENT '性别 0-男, 1-女', `password` varchar(100) NOT NULL COMMENT '密码', `age` tinyint NOT NULL COMMENT '年龄', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, `update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `id_app_user_name` (`name`), KEY `idx_name_phone_password` (`name`,`phone`,`password`) ) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8mb3 COMMENT='app'; #创建自定义函数 需要一行行复制 DELIMITER $$ CREATE FUNCTION mock_data() RETURNS INT BEGIN DECLARE num INT DEFAULT 1000000; DECLARE i INT DEFAULT 0; WHILE i < num DO INSERT INTO `school`.`app_user`(`name`,`email`,`phone`,`gender`,`password`,`age`)VALUES (CONCAT('用户',i), '123456@qq.com', CONCAT('18', FLOOR(RAND()*((999999999-100000000)+100000000))), FLOOR(RAND()*2), UUID(), FLOOR(RAND()*100)); SET i = i+1; END WHILE; RETURN i; END $$ #调⽤函数 select mock_data(); #校验数据 select count(*) from app_user; ``` - 创建用户 ```sql create user damin@'%' identified by '123456'; grant all privileges on *.* to 'damin'@'%' WITH GRANT OPTION; ``` - mysqlslap自带压测 ```sql mysqlslap --defaults-file=/data/mysql3306/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='school' --query="SELECT * FROM app_user WHERE name='用户9999';" engine=innodb --number-of-queries=2000 -udamin -p123456 -h127.0.0.1 -verbose --concurrency=100 : 模拟同时100会话连接 --create-schema='school' : 操作的库是谁 --query="SELECT * FROM app_user WHERE name='用户9999';" :做了什么操作 --number-of-queries=2000 : 一共做了多少次查询 ``` - 不使用索引压测 ```sql # 压测 mysqlslap --defaults-file=/data/mysql3306/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='school' --query="SELECT * FROM app_user WHERE name='用户9999';" engine=innodb --number-of-queries=2000 -udamin -p123456 -h127.0.0.1 -verbose # 查看会话 SHOW PROCESSLIST; ```  ```sql SELECT * FROM `app_user` WHERE `name`='用户9999'; EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户9999'; ``` 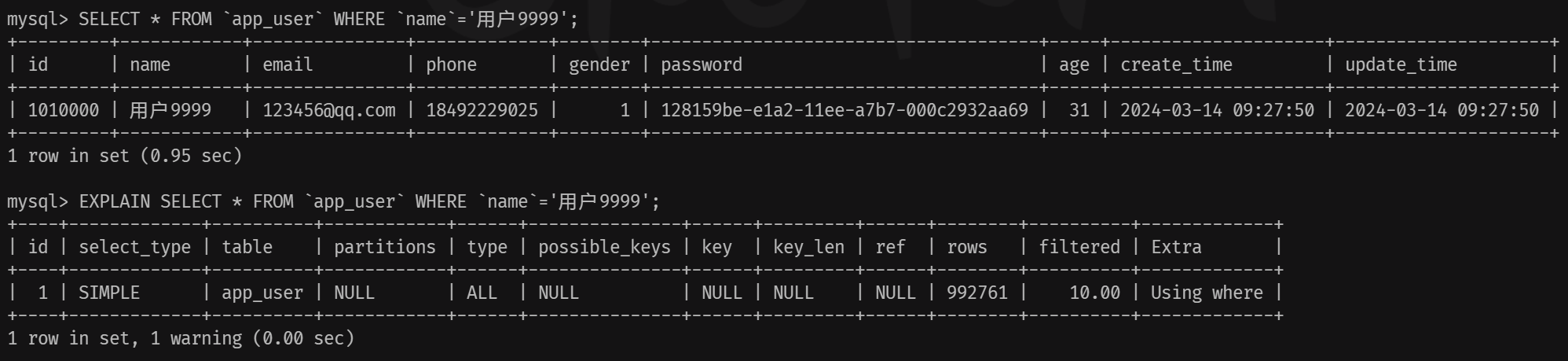 - 添加普通索引测试 ```sql #添加一个普通二级索引 CREATE INDEX id_app_user_name ON app_user(`name`); EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户9999'; #再次压测 mysqlslap --defaults-file=/data/mysql3306/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='school' --query="SELECT * FROM app_user WHERE name='用户9999';" engine=innodb --number-of-queries=2000 -udamin -p123456 -h127.0.0.1 -verbose ``` 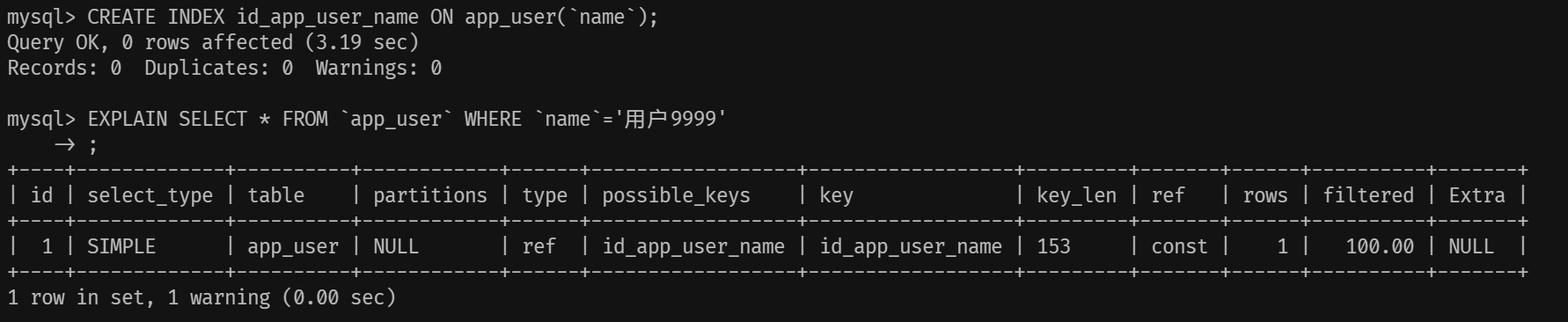  - 添加联合索引测试 ```sql #复合索引,作用:解决多个where条件走索引 alter table app_user add index idx_name_phone_password(name,phone,password); #或 CREATE INDEX idx_name_phone_password ON app_user(`name`,`phone`,`password`); #应用场景(也是覆盖) select name,phone,password from app_user where name='用户0' and phone=18399466985 and password='f93758ef-0d93-11ec-99bf-fa2020131854'; ``` - 前缀索引 ```sql #较少索引树高度,取前5位数字作为索引 alter table app_user add index idx_phone(phone(5)); ``` - 删除索引 ```sql alter table app_user drop index idx_phone; ``` ```sql mysql> show create table app_user\G *************************** 1. row *************************** Table: app_user Create Table: CREATE TABLE `app_user` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT '' COMMENT '昵称', `email` varchar(50) DEFAULT NULL COMMENT '邮箱', `phone` bigint DEFAULT NULL COMMENT '手机号', `gender` tinyint DEFAULT NULL COMMENT '性别 0-男, 1-女', `password` varchar(100) NOT NULL COMMENT '密码', `age` tinyint NOT NULL COMMENT '年龄', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, `update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `id_app_user_name` (`name`), KEY `idx_name_phone_password` (`name`,`phone`,`password`) ) ENGINE=InnoDB AUTO_INCREMENT=2000001 DEFAULT CHARSET=utf8mb3 COMMENT='app' 1 row in set (0.01 sec) mysql> drop index id_app_user_name on app_user; Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> drop index idx_name_phone_password on app_user; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 ``` ### 1.3.执行计划 #### 1.3.1.介绍与使用方法 - 可以得到什么 ```sql 1 查询执行计划(QEP) - 表的加载顺序 - sql 的查询类型 - 可能用到哪些索引,实际上用到哪些索引 - 读取的行数 - 表之间的引用 - 每张表有多少行被优化器查询 ``` - 使用方法 ```sql explain SQL (SELECT DELETE UPDATE) mysql> explain select name,phone,password from app_user where name>'用 户0' and phone>1 limit 500,10\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: app_user partitions: NULL type: range possible_keys: id_app_user_name,idx_name_phone_password key: idx_name_phone_password key_len: 153 ref: NULL rows: 496563 filtered: 33.33 Extra: Using where; Using index 1 row in set, 1 warning (0.01 sec) #加强版 mysql> explain format=json select name,phone,password from app_user where name>'用 户0' and phone>1 limit 500,10\G *************************** 1. row *************************** EXPLAIN: { "query_block": { "select_id": 1, "cost_info": { "query_cost": "126849.41" }, "table": { "table_name": "app_user", "access_type": "range", "possible_keys": [ "id_app_user_name", "idx_name_phone_password" ], "key": "idx_name_phone_password", "used_key_parts": [ "name" ], "key_length": "153", "rows_examined_per_scan": 496563, "rows_produced_per_join": 165504, "filtered": "33.33", "using_index": true, "cost_info": { "read_cost": "110298.97", "eval_cost": "16550.44", "prefix_cost": "126849.41", "data_read_per_join": "101M" }, "used_columns": [ "name", "phone", "password" ], "attached_condition": "((`school`.`app_user`.`name` > '用 户0') and (`school`.`app_user`.`phone` > 1))" } } } 1 row in set, 1 warning (0.00 sec) ``` **EXPLAIN列的解释:** 1.ID ```sql 含义:select查询的序列号,查询中执行select子句或操作表的顺序 - id相同:执行顺序从上至下 , - id不同:有子查询或者派生表(id大先执行) join 举例: CREATE TABLE `discuss` ( `discuss_id` int NOT NULL AUTO_INCREMENT COMMENT '评论唯一id', `discuss_body` varchar(255) NOT NULL COMMENT '评论内容', `discuss_time` datetime NOT NULL COMMENT '评论时间', `user_id` int NOT NULL COMMENT '用户id', `blog_id` int NOT NULL COMMENT '博文id', PRIMARY KEY (`discuss_id`) ) ENGINE=InnoDB AUTO_INCREMENT=61 DEFAULT CHARSET=utf8mb3 explain select discuss_body from discuss where blog_id = ( select blog_id from blog where user_id = ( select user_id from user where user_name = 'admin')); ``` 2.select_type: ```sql select_type:查询类型,比如普通查询,联合查询,子查询 SIMPLE:简单的select查询,不包含子查询或者UNION PRIMARY:子查询的最外层查询 SUBQUERY:在SELECT或WHERE列表中包含了子查询 DERIVED: 衍生表把结果放在临时表中 UNION:UNION后的第二个SQL UNION RESULT:从UNION表获取结果的SELECT ``` 3.table ```sql table:当前执行的表 ``` 4.type ```sql type:查询类型,性能排序 system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL system:表只有一行记录 const:索引一次找到,主键和unique 索引 eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。 ref:辅助索引等值访问 range:索引范围扫描 index:全索引扫描 all: full table scan ``` 5.possible_keys ```sql possible_keys 和 key:可能使用索引和真正使用的索引 ``` 6.key_len ```sql key_len:索引使用字节数 ``` 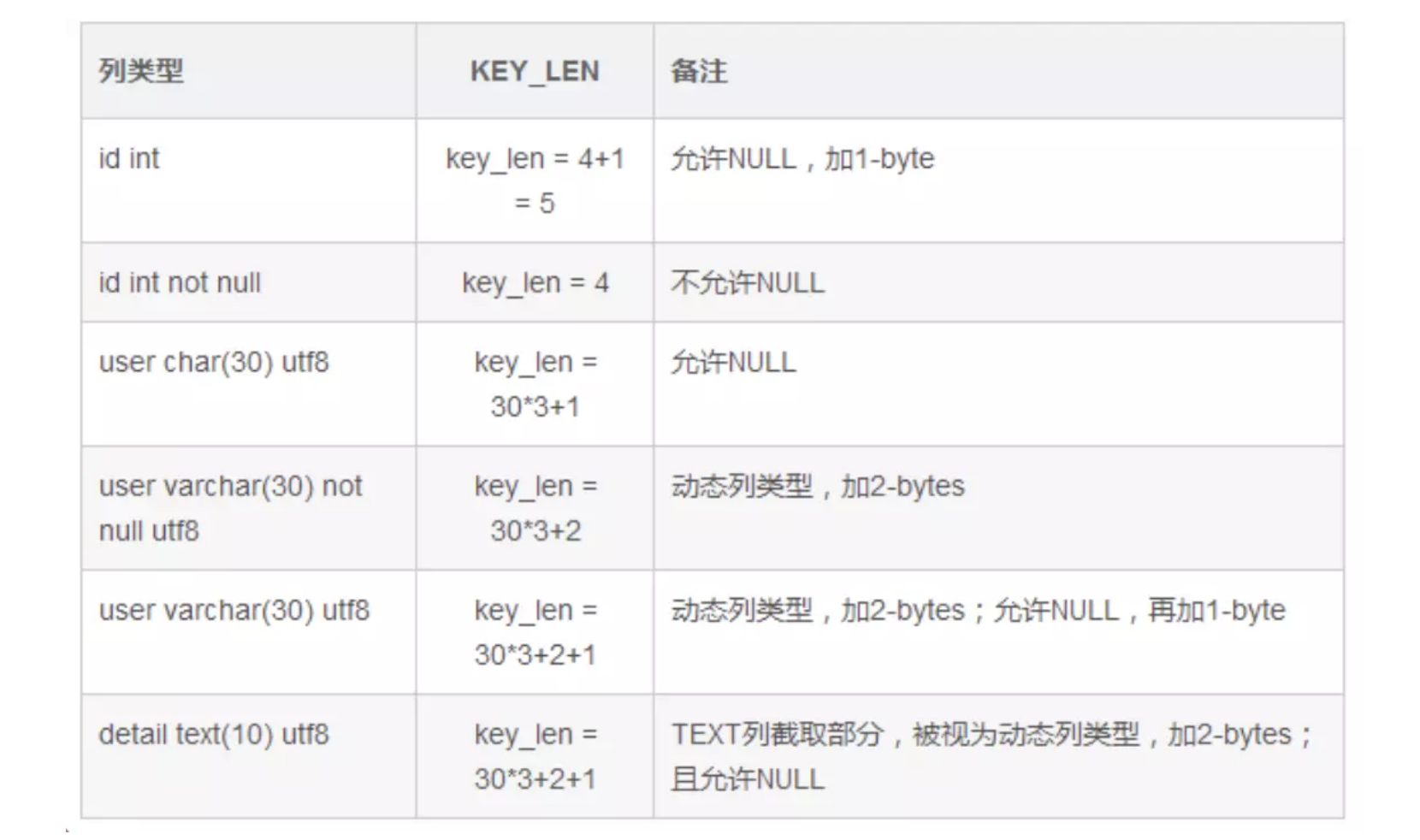 7.ref ```sql ref: 显示索引的哪一列被使用了 select * from t1,t2 where t1.col1 = t2.col1(t1.col1为索引列) ; ``` 8.其余 ```sql 8.rows:大致估计读取行数 9.filtered:满足条件记录/扫描记录的百分比 10.extra:MYSQL如何解析查询的额外信息 ``` #### 1.3.2.type信息详解 - system ```sql mysql> explain select * from mysql.proxies_priv; 表示:系统表,少量数据,往往不需要进行磁盘IO ``` - const:单表操作的时候,查询使用了主键或者唯一索引 ```sql mysql> explain select * from app_user where id=1000001; +----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | app_user | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL | +----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) 表示:通过索引一次就匹配到,用于primary 或者unique索引,常量连接。 user_id是 primary ``` - eq_ref ```sql 多表关联查询:,主键和唯一索引作为关联条件。如下图的sql,对于user表(外循环)的每一行,user_role表(内循环)只有一行满足join条件,只要查找到这行记录,就会跳出内循环,继续外循环的下一轮查询 一句话:对于前表的每一行(row),后表只有一行被扫描 (1)join查询 (2)命中主键或者命中非空唯一索引 (3)等值连接 ### create table user_role like user; explain select u.user_name from user u,user_role ur where u.user_id = ur.user_id; ``` - ref ```sql 含义:使用索引但值不唯一(没用主键和唯一索引), 不需要全表扫描.eq_ref降级为了ref, 此时对于前表的每一行(row),后表可能有多于一行的数据被扫描。 条件:ref扫描,可能出现在join或单表普通索引里,每一次匹配可能有多行数据返回,比eq_ref要慢。 ### mysql> explain select user_id from user where user_name='admin'; #ref_or_null:类似 ref,会额外搜索包含NULL值的行。 ``` - index_merge ```sql (1)索引合并,对多个索引分别进行条件扫描, (2)结果进行合并 #mysql5.0之后出现的功能 mysql> explain select id,name from app_user where id=1 or name='用户0'; mysql> explain select id,name from app_user where id=1 or name='用户0'; +----+-------------+----------+------------+-------------+--------------------------------------------------+--------------------------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+-------------+--------------------------------------------------+--------------------------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | app_user | NULL | index_merge | PRIMARY,id_app_user_name,idx_name_phone_password | PRIMARY,id_app_user_name | 8,153 | NULL | 2 | 100.00 | Using union(PRIMARY,id_app_user_name); Using where | +----+-------------+----------+------------+-------------+--------------------------------------------------+--------------------------+---------+------+------+----------+----------------------------------------------------+ 1 row in set, 1 warning (0.00 sec) ``` - range ```sql 含义:基于Index数据上的范围扫描,扫描特定范围内的值,between、and、'>'、'<'、in和or都是范围索引扫描。 explain select * from user where user_id>0; ``` - index ```sql 含义:需要扫描索引上的全部数据 mysql> explain select user_name from user ; ``` - all ```sql full table scan 生产禁止 #案例 业务说小表5W(config),500条以下生产可以 all select a from config_table where a in ('xx','xx','xx'); 业务上线--->注册中心-->1000多个服务-->mysql实例重启(buffer_pool清空) -->线上服务报失联-->业务找到DBA-->连接数打满-->全都是select语句 -->从库加了idx_a索引-->(MHA)主从切换-->故障解决 ``` **总结** ```sql (1)explain结果中的type字段,表示(广义)连接类型,它描述了找到所需数据使用的扫描方式; (2)常见的扫描类型有: system>const>eq_ref>ref>range>index>ALL 扫描速度由快到慢; (3)各类扫描类型的要点是: system最快:不进行磁盘IO const:PK或者unique上的等值查询 eq_ref:PK或者unique上的join查询,等值匹配,对于前表的每一行(row),后表只有一行命中 ref:非唯一索引,等值匹配,可能有多行命中 range:索引上的范围扫描 index:索引上的全集扫描 ALL最慢:全表扫描(full table scan) (4)建立正确的索引(index),非常重要,解决80%性能故障; (5)使用explain了解并优化执行计划,非常重要; ``` #### 1.3.3.extra 额外的Mysql查询优化器执行信息 ```sql #建立测试表 CREATE TABLE `t_order` ( `id` int NOT NULL AUTO_INCREMENT, `user_id` int DEFAULT NULL, `order_id` int DEFAULT NULL, `order_status` tinyint DEFAULT NULL, `create_date` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_userid_order_id_createdate` (`user_id`,`order_id`,`create_date`) ) ENGINE=InnoDB AUTO_INCREMENT=99 DEFAULT CHARSET=utf8; CREATE TABLE `t_orderdetail` ( `id` int NOT NULL AUTO_INCREMENT, `order_id` int DEFAULT NULL, `product_name` varchar(100) DEFAULT NULL, `cnt` int DEFAULT NULL, `create_date` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_orderid_productname` (`order_id`,`product_name`) ) ENGINE=InnoDB AUTO_INCREMENT=152 DEFAULT CHARSET=utf8; ``` ```sql #1.useing where 查询索引列未覆盖 mysql>explain select order_id,order_status from t_order where order_id=1\G mysql> explain select * from app_user where phone>123456; mysql>explain select * from app_user where gender='男'; #2.useing index 覆盖索引 mysql> explain select user_id,order_id from t_order where user_id=1\G #3.Using where&Using index 索引覆盖,但是无法通过索引找到数据,通过索引扫描 ##(`user_id`,`order_id`,`create_date`) 索引不符合最左匹配原则 mysql> explain select user_id,order_id,create_date from t_order where order_id=1\G ##where 条件索引前导列一个范围 mysql> explain select user_id,order_id,create_date from t_order where user_id>1\G #4.NULL:select 列未覆盖,用到索引,需要回表 mysql> explain select user_id,order_id,order_status from t_order where user_id=1\G #5.using index condition 索引下推(index condition pushdown,ICP),先使用where条件过滤索引,过滤完索引后 找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。 explain select user_id, order_id, order_status from t_order where user_id > 1 and user_id < 5\G; set optimizer_switch='index_condition_pushdown=off'; set optimizer_switch='index_condition_pushdown=on'; ``` - 不使用索引下推 `set optimizer_switch='index_condition_pushdown=off'` 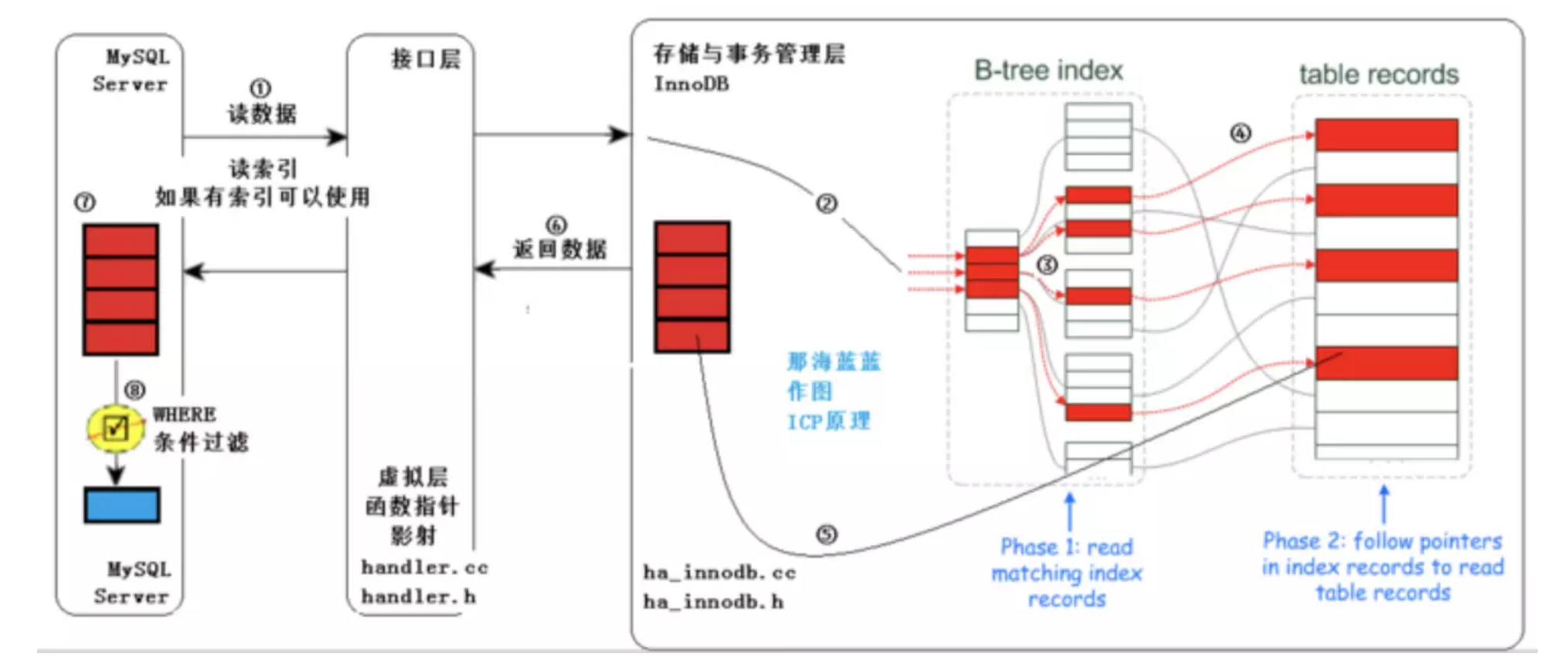 - 使用索引下推 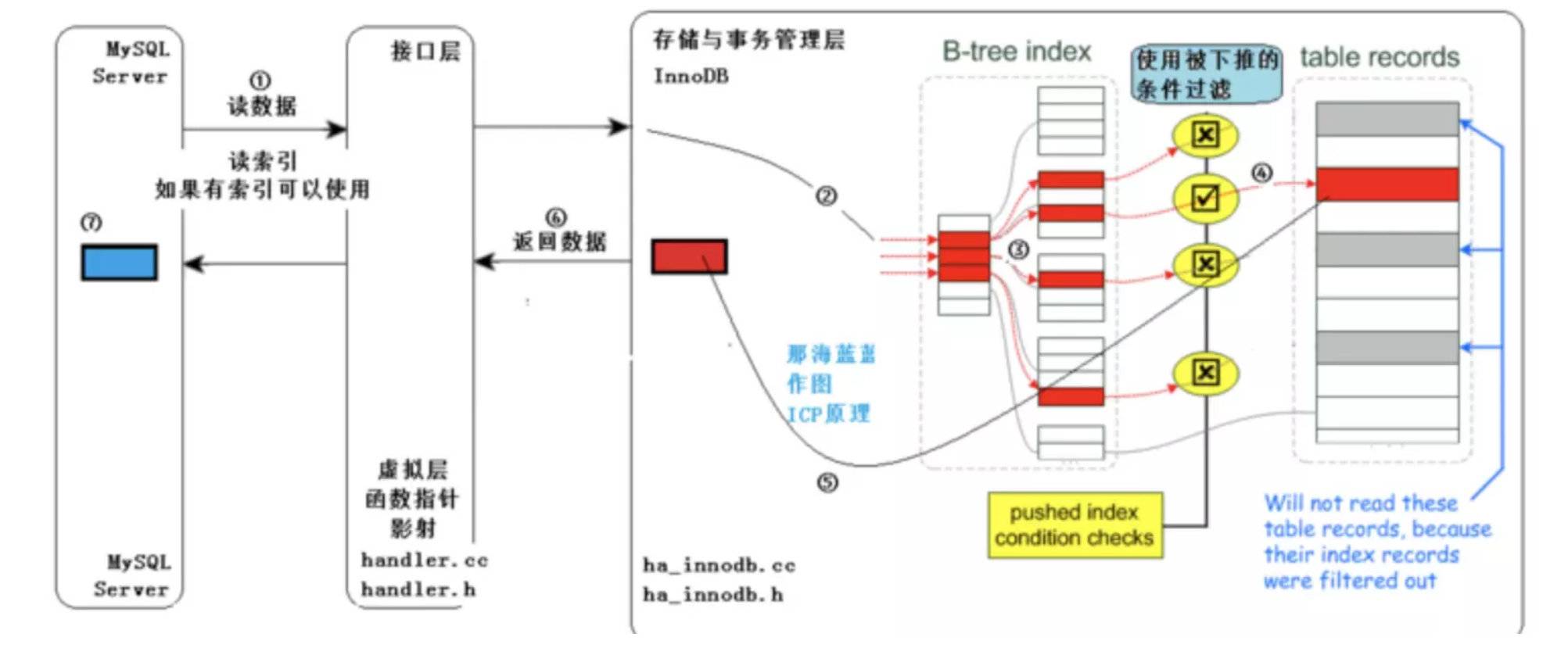 **总结** ```sql using index :使用覆盖索引的时候就会出现 using where:在查找使用索引的情况下,需要回表去查询所需的数据 using index condition:查找使用了索引,但是需要回表查询数据 using index & using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据 **using index condition:索引下推,对索引进行where条件过滤,找到符合索引条件的行.** ``` ```sql #6.using temporary 使用了临时表保存中间结果,常见于 order by column和 group by 中。 #7.usering filesort 文件排序。表示无法利用索引完成排序操作,以下情况会导致filesort: - order by 的字段不是索引字段 - select 查询字段不全是索引字段 - select 查询字段都是索引字段,但是 order by 字段和索引字段的顺序不一致 mysql> explain select * from t_order order by order_id; Block Nested Loop,需要进行嵌套循环计算。 两表join,关联字段未建立索引. #join buffer介绍 暴力表连接时候的重要优化手段.a*b - 不使用: 笛卡尔积,a的每个值,b都要一次全表扫描 - 使用:a的值加载进 joinbuffer,1*b 次 ``` #### 1.3.2.联合索引 1.条件 ```sql 联合索引应用要满足最左原则 (1)建立联合索引时,过滤因子高的列作为最左列。 (2)使用联合索引时,查询条件中,必须包含最左列,才有可能应用到联合索引。 (3)`idx_name_phone_password` (`name`,`phone`,`password`) 相当于3个索引(name),(name,phone),(name,phone,password) 走索引: select * from app_user where name=? select * from app_user where name=? and phone=? select * from app_user where name=? and phone=? and password=? 不走索引: select * from app_user where phone=? select * from app_user where password=? select * from app_user where phone=? and password=? 联合索引最佳使用场景 explain select name,phone,password from app_user where name='' and phone='' and password > ``` 2.覆盖索引场景应用 ```sql 1.全表count查询优化 explain select count(name) from app_user; 2.场景2:列查询回表优化 explain select name,phone,password from app_user where name='用户0' and phone=2147483647 and password='f93758ef-0d93-11ec-99bf-fa2020131854'; 3.分页查询 explain select name,phone,password from app_user where name='用户0' and phone>1 order by name limit 500,100; explain select name,phone,password from app_user where name>'用户0' and phone>1 limit 500,10; ``` ### 1.4.explain应用场景 - 数据库突然hang住,连接数打满 ```sql #分析正在执行的大SQL 1.select COMMAND,SUBSTRING_INDEX(host,':',1) as ip , count(*),INFO from information_schema.processlist group by ip; 2.explain SQL 3.看索引,看代价,看量级-->联系业务进行处理 explain format=json select user_id, order_id, order_status from t_order where user_id > 1 and user_id < 5\G ``` - 日常分析 ```sql 1.分析slowlog 2.找出慢SQL 3.分析执行计划explain 4.优化 ``` ### 1.5.Mysql8.0 索引新特性 #### 1.5.1.不可见索引(INVISIBLE INDEX) ```sql 介绍: 1.INVISIBLE INDEX,不可见索引或者叫隐藏索引. 2.不可见是指对优化器不可见,查询的时候优化器不会作为备选.其实InnoDB仍然维护 3.操作更改的是metadata,开销非常小. 使用场景: 1.有索引idx1,idx2,idx3.通过数据字典检索,通过数据字典检索idx3没有用过,是否判断索引直接删除呢? 删除后有业务使用怎么办,这个时候用开销较小的隐藏索引 2.业务一个月用一次的SQL,使用隐藏索引 3.测试 mysql> alter table app_user add index idx_phone(phone); mysql> alter table app_user alter index idx_phone invisible; mysql> alter table app_user alter index idx_name_phone_password invisible; mysql> explain select count(*) from app_user where phone=123; #测试报错 mysql> explain select count(*) from app_user force index(idx_phone) where phone=123; #开启优化器使用隐藏索引 mysql> set @@optimizer_switch = 'use_invisible_indexes=on'; #再次执行可以使用索引 mysql> explain select count(*) from app_user force index(idx_phone) where phone=123; #不可见索引变回可见索引 ALTER TABLE app_user ALTER INDEX idx_name_phone_password VISIBLE; ``` #### 1.5.2.倒序索引 ```sql #MySQL5.7之前对索引建立只允许asc正向存储,所有索引都是按升序创建的。当语法本身被解析 时,元数据不会被保留,比如以下查询 mysql> explain select name,phone from app_user order by name asc, phone asc limit 10 ; mysql> explain select name,phone from app_user order by name asc, phone desc limit 10 ; #Using index; Using filesort 出现filesort要用外部文件排序 ##排序过程 #Mysql8.0 ##建立倒序索引 alter table app_user add index idx_name_phone(name asc,phone desc); ##再次执行explain语句 mysql> explain select name,phone from app_user order by name asc, phone desc limit 10 ; Backward index scan; #出现反向扫描,与索引的顺序相反,因此需要反向扫描 ``` ## 2.索引应用规范与优化 ### 2.1.索引建立原则 原则: ```sql (1) 必须要有主键,最好数字自增列。 (2) where条件,order by,group by,join ,distinct 的条件加索引 (3) 联合索引最左原则。 (4) 列值长度较长的索引列,建议使用前缀索引. (5) 不常用索引进行清理 (6) 业务流量高,索引添加和删除,要在低峰期使用,pt-osc(inception)或gh-osc(go-inception) (7) 在执行ALTER操作之前,确定实例没有大事务未提交(防止一系列的元数据锁) (8) 减少索引树的高度:尽量用varchar变成节省空间和每列行大小 (9) 频繁进行数据操作的表,不要建立太多的索引; (10)删除无用的索引,避免对执行计划造成负面影响 #不推荐使用索引的情况 (1)数据唯一性差(比如性别),尽量不要用索引 (2)频繁更新的字段不建议用索引(每次update索引的值也要update),会造成很多碎片,同时增加实例负担,增加了随机IO次数 ``` 问题?为什么PK推荐数字自增? - 使用自增id的内部结构 ```sql 自增主键的值是顺序的.页面达到最大填充因子(默认页的15/16).留出1/16的空间留作以后的修改 (1)下一条记录写到新的value,主键页按照顺序方式填满记录,提升页的最大填充率,不会有页的浪费 (2)新插入的行一定是原有最大数据的下一行,mysql定位和寻址很快,不会为计算新行的位置做出额外的消耗 (3)减少页分裂和碎片的产生 ``` - 使用uuid的聚簇索引内部结构 ```sql uuid的自增id无规律,innodb无法做到顺序插入,需要寻找合适位置分配新的空间,数据无顺序导致数据分布散乱,导致以下问题: (1)数据已经从内存落地到磁盘或从缓冲中移除:innodb插入前要从磁盘读取目标页到内存中,增加随机IO (2)写入乱序,innodb的索引树频繁做页分裂操作,为新行分配空间,页分裂导致移动大量数据,一次插入至少修改三个页以上 (3)频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片 (4)有机会需要做一次OPTIMEIZE TABLE来重建表并优化页的填充,带来时间消耗。 ``` 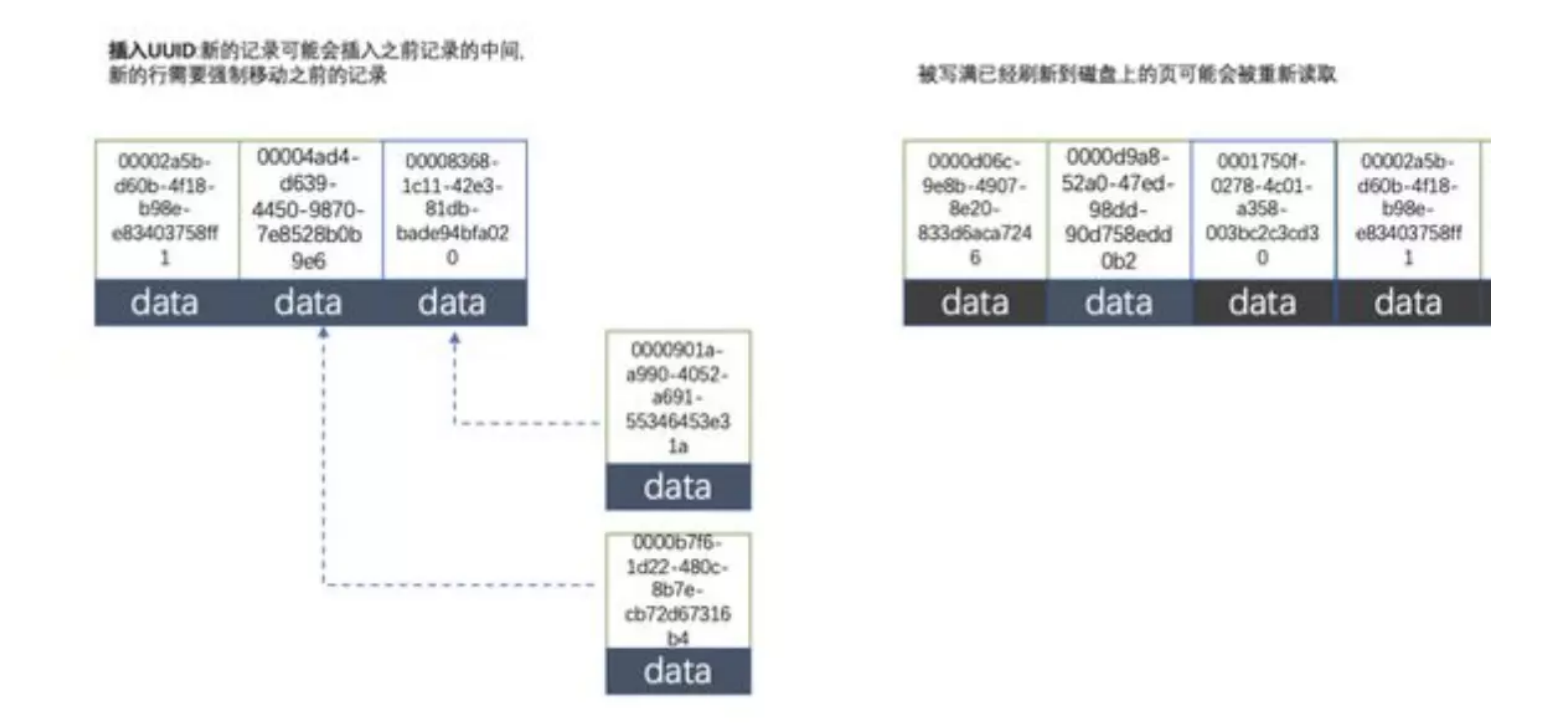 ### 2.2.不走索引的情况 ```sql 1.条件中有or且有谓词没有索引,需要每个列都加索引 explain select name,gender from app_user where name='用户37374' or age = 2; 2.like查询 %开头 explain select name,gender from app_user where name like '%sd'; 3.多列索引,不是使用的第一部分,不符合最左匹配原则 explain select name,gender from app_user where phone=2147483647; 4.隐式转换(一定要提醒业务开发),比如type是字符串但是没用引号 explain select name,gender from app_user where name=37374; 5.where子句有数学运算和函数运算 explain select name,gender from app_user where name+1='用户37374' ; explain select name,gender from app_user where length(name)=95 ; 6.mysql判断全表扫描比索引快,不使用索引(比如数据量级极少的表) 7.<> ,not in 不走索引(辅助索引) ``` ```sql | app_user | CREATE TABLE `app_user` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT '' COMMENT '昵称', `email` varchar(50) DEFAULT NULL COMMENT '邮箱', `phone` int DEFAULT NULL COMMENT '手机号', `gender` tinyint DEFAULT NULL COMMENT '性别 0-男, 1-女', `password` varchar(100) NOT NULL COMMENT '密码', `age` tinyint NOT NULL COMMENT '年龄', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, `update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `id_app_user_name` (`name`), KEY `idx_name_phone_password` (`name`,`phone`,`password`) ``` 如何查看未使用的索引 mysql5.7 以上可以使用 ```sql SELECT OBJECT_SCHEMA, OBJECT_NAME, INDEX_NAME FROM performance_schema.table_io_waits_summary_by_index_usage WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA not in ('mysql','performance_schema') ORDER BY OBJECT_SCHEMA,OBJECT_NAME; mysql> SELECT OBJECT_SCHEMA, OBJECT_NAME, INDEX_NAME FROM performance_schema.table_io_waits_summary_by_index_usage WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA not in ('mysql','performance_schema') ORDER BY OBJECT_SCHEMA,OBJECT_NAME; +---------------+-------------+-------------------------+ | OBJECT_SCHEMA | OBJECT_NAME | INDEX_NAME | +---------------+-------------+-------------------------+ | school | app_user | PRIMARY | | school | app_user | id_app_user_name | | school | app_user | idx_name_phone_password | +---------------+-------------+-------------------------+ 3 rows in set (0.10 sec) ``` ### 2.3.索引优化器算法 > https://dev.mysql.com/doc/refman/5.6/en/bnl-bka-optimization.html 万事找官网 #### 2.3.1.AHI-自适应hash索引 ```sql AHI:将查询频繁的条件和索引树结果做一个hash映射,无需搜索B+tree,直接通过hash定位查询数据。 1.DBA不能干预,innodb_adaptive_hash_index参数控制是否开启 2.等值查询非常快(大并发量级大约30-40%),范围查找没有优化. 3.副作用(5.7.34之前有):MySQL8.0.23版本已经修复 删除大表,Buffer pool比较大的时候(超过32G),会有短暂hang住的情况,造成业务抖动 原因:删除表会把该表在BP内存都淘汰掉,释放空间(数据页,索引页,AHI),扫描BP中的 flush_list时间较长,造成波动. #额外知识点: 查询频繁如何计算: n_fields hash_analysis,n_hash_potential,last_hash_succ的信息结构 当一次查询成功后,累加hash_analysis属性,记录查询成功次数,当hash_analysis超过 17次时候且select字段值唯一,MySQL对此构建AHI.即hash_analysis>=17 and n_hash_potential=100. last_hash_succ是mysql发现场景不适合建立AHI,直接设置false #优化参数 set global innodb_adaptive_hash_index_parts=16; #默认值是8,可以打散AHI锁粒 度,hashtable变多 ``` #### 2.3.2.Change-Buffer - 左边内存,右边磁盘。  ```sql 原理:DML操作二级索引,判断数据页是否在buffer pool中,不在加载到change buffer操作, 然后以一定频率对数据和辅助索引数据页进行merge 作用:多次操作合并一次,减少IO。提升DML性能 1.特殊的缓存结构,用于缓存不在buffer pool里面的二级索引 2.支持inser,update,delete(DML) 3.Change Buffer什么时候会merge - 二级索引被读取到buffer pool时候:执行select语句检查是否在change buffer, 在则merge到索引页 - 二级索引页 no space left:InnoDB内部监测二级索引页是否有可用空间(至少1/32页), 没有则强制执行merge操作 - 后台线程:Master Thread定时merge:核心后台线程,讲缓冲池数据异步刷新到磁盘,保证 数据一致性 疑问1?为什么只能针对非聚集非唯一索引 1.主键索引或者唯一索引,需要判断数据是否唯一,去索引页加载数据判断而不能仅操作缓存. ``` #### 2.3.3.ICP(前面) #### 2.3.4.MRR: Multi-Range Read Optimization ```sql 概念:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能 作用:查询二级索引时,先对查询到的结果按照主键进行排序,再去聚簇索引进行回表 ``` 三个问题: (1)为什么要把随机读转化为顺序读? (2)怎么转化的? (3)为什么顺序读就能提升读取性能? ```sql #执行一个范围查询 explain select * from stu where age between 10 and 20; ``` sql执行-去磁盘读取数据(假设数据不再buufer pool) - 红色是查询过程 - 蓝色是磁盘路线 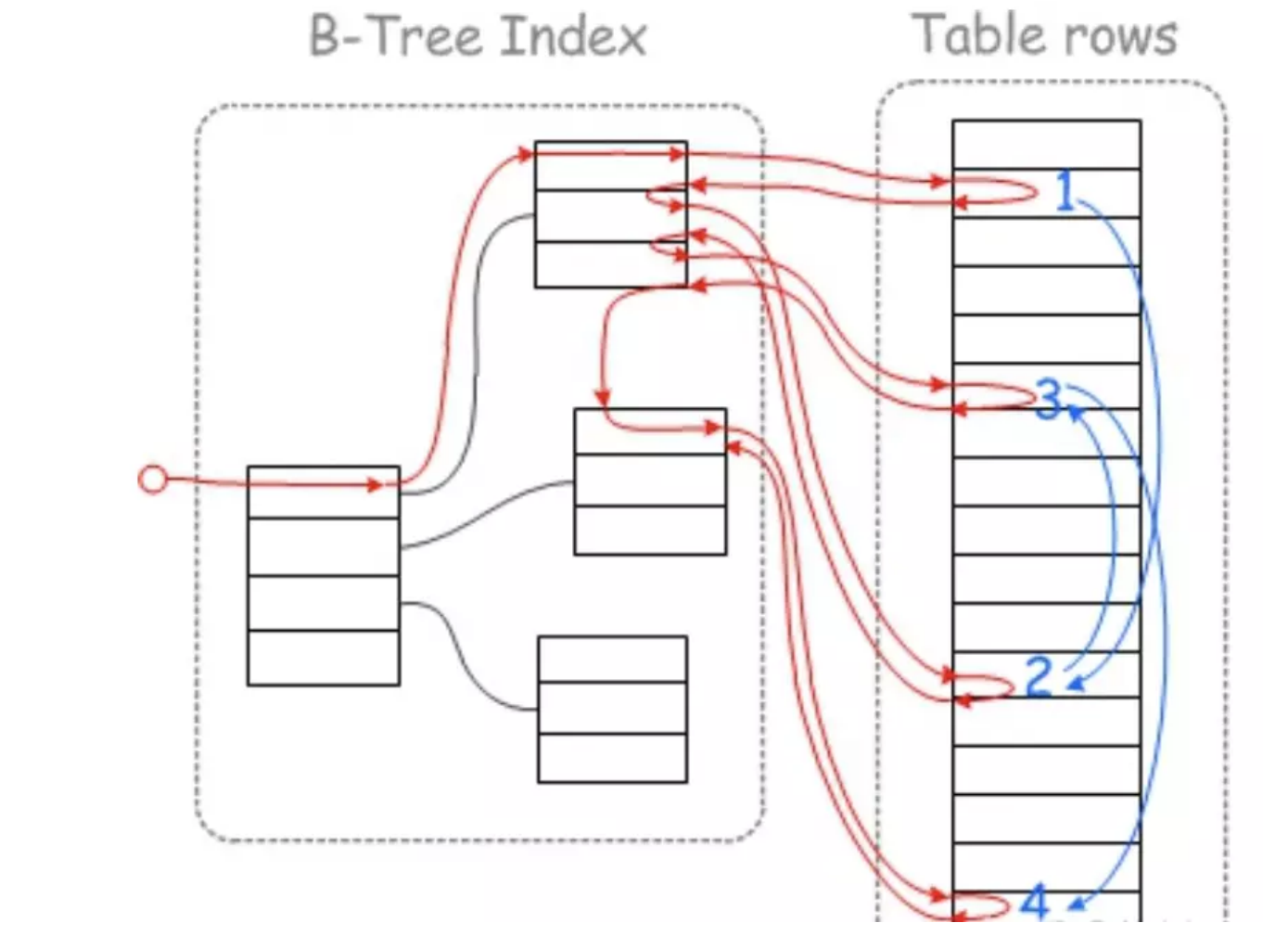 转化为顺序访问 ```sql set optimizer_switch='mrr=on'; explain select * from stu where age between 10 and 20; #Extra 里多了一个「Using MRR」 ``` 查询过程 ```sql #步骤 - 优化器将二级索引查询到的记录放到一块缓冲区中 - 如果二级索引扫描到文件的末尾或者缓冲区已满,则使用快速排序对缓冲区中的内容按照主键进行排序 - 用户线程调用MRR接口取cluster index,然后根据cluster index 取行数据 - 当根据缓冲区中的 cluster index取完数据,则继续调用过程 2) 3),直至扫描结束 对InnoDB,按照聚簇索引键值排好序,在顺序读取聚簇索引。 好处: 1.磁盘和刺头不需要回来做机械运动 2.利用磁盘预读 3.在一次查询中,每一页的数据只从磁盘读取一次.(如果读取1页,在读2,3,4,再次读取1页 可能被缓存剔除了,顺序读则一次读取1234页). #相关参数 mrr: on/off #开关 mrr_cost_based: on/off #优化器是否基于MRR成本(cost-based choice),决定SQL使用 read_rnd_buffer_size #给rowid排序的内存大小 如果读取1行数据,没必要MRR,建议设置为on ``` 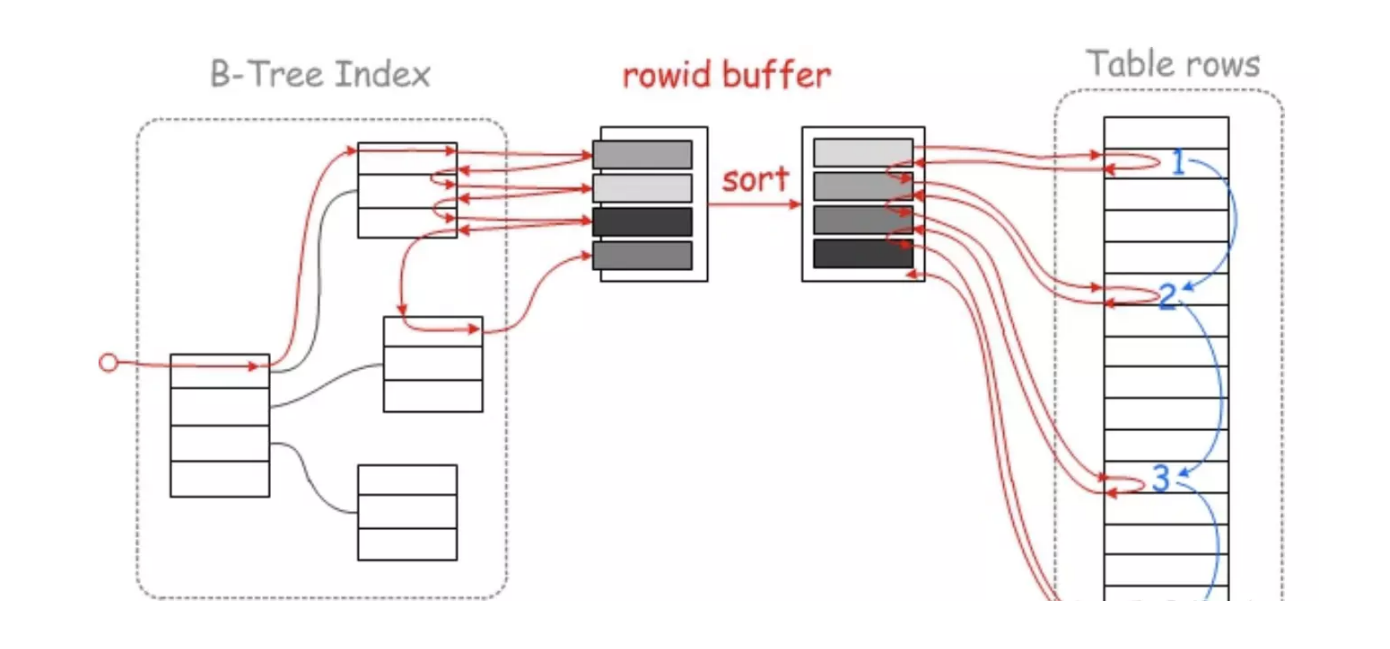 ```sql #总结 MRR,则是把索引减少磁盘 IO 的作用,进一步放大。本质使用空间换时间的算法.对基于索引的查询做的一个的优化,优化的优化了。 ``` #### 2.3.5.Simple Nested-Loop Join(简单的嵌套循环连接) ```sql 定义:嵌套循环连接算法双层的for循环,外表数据逐个与内表数据比较 例如:select * from user tb1 left join level tb2 on tb1.id=tb2.user_id 伪代码类似于: for (user表的行 ur:user 表{ for (level表的行 lr:level表) { if(ur.id = lr.id)\\返回成功匹配的数据 } } 特点:简单粗暴,双层循环比较数据,如果有2个表每个1W条数据. 1W*1W=1亿. 再此基础后优化出现后面两种join优化算法 ``` 匹配过程如下图 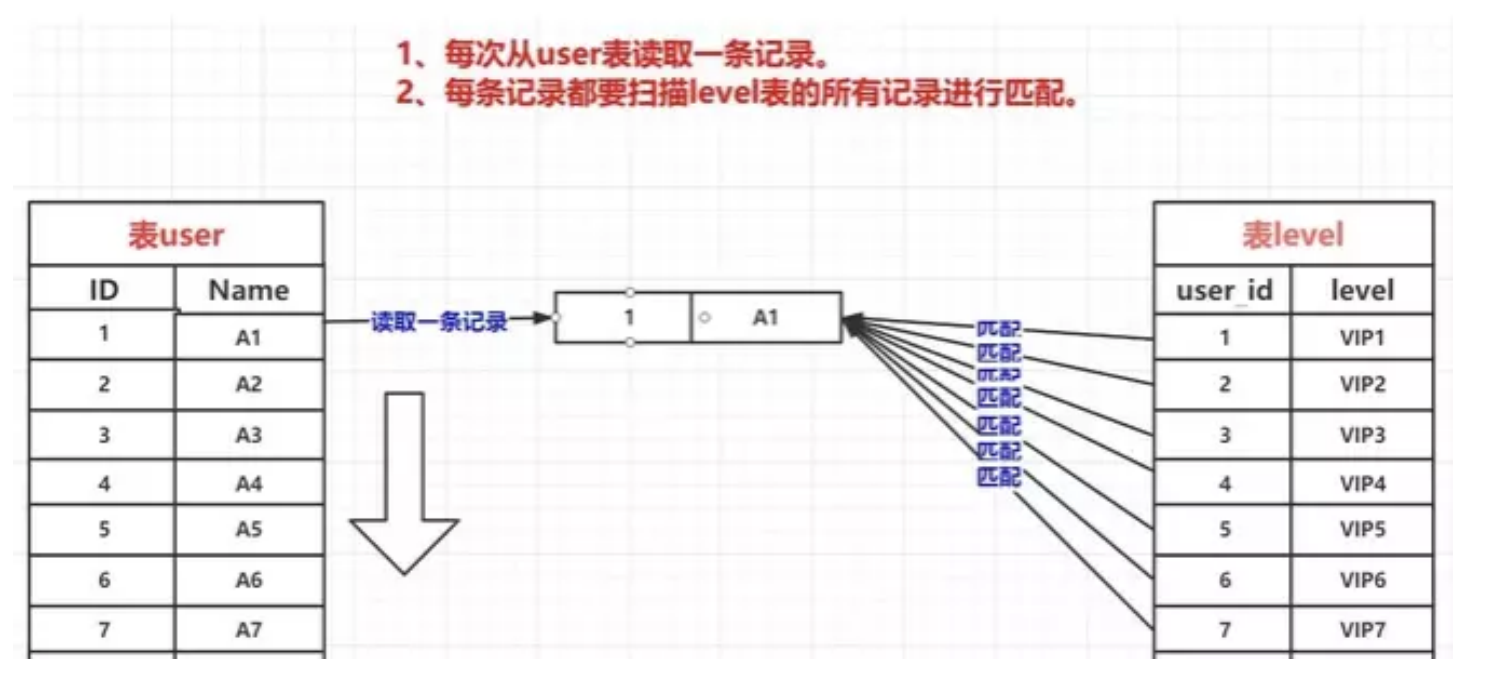 #### 2.3.6.Index Nested-Loop Join(索引嵌套循环连接) ```sql 优化思路: 1.减少内层表数据匹配次数,通过外表条件直接与内层表索引匹配,避免笛卡尔积. 2.匹配次数变为: 外表行数*内表索引树高度(一般为2 or 3),极大提升join性能 例子: select * from user tb1 left join level tb2 on tb1.id=tb2.user_id 使用提前: 匹配字段必须**建立索引**,这里指id和user_id ``` 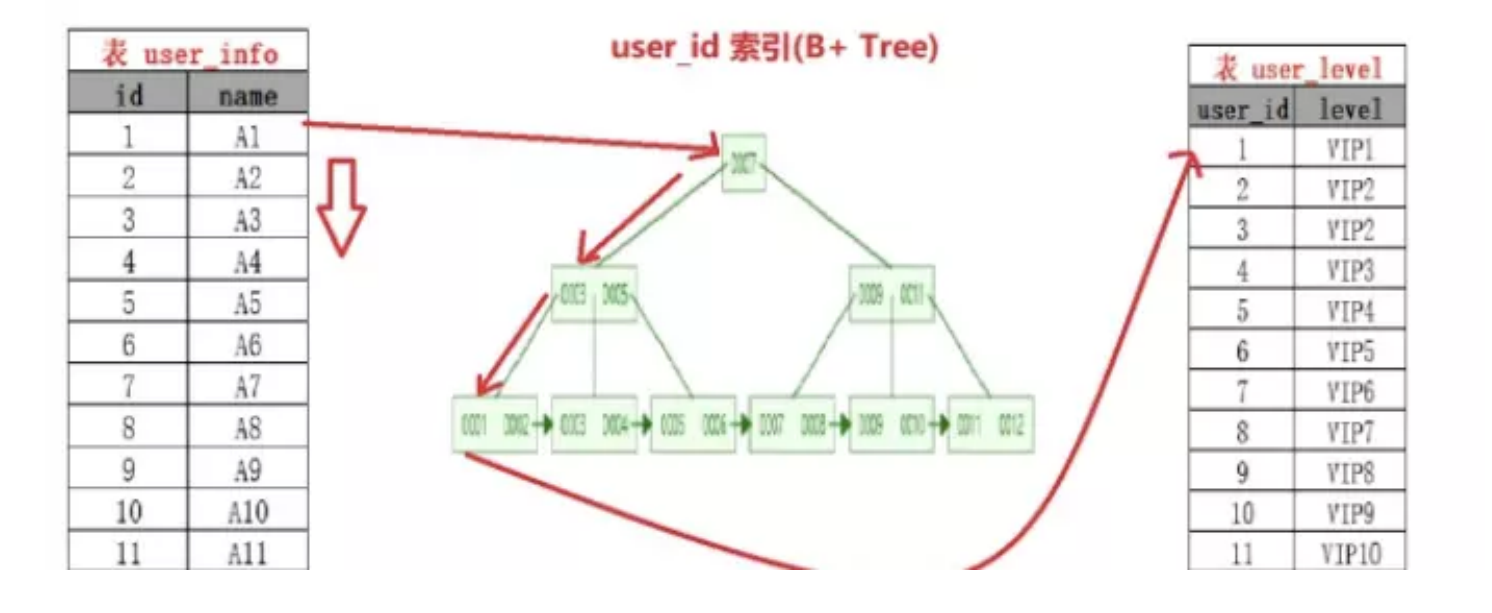 #### 2.3.7.Block Nested-Loop Join(缓存块嵌套循环连接) ```sql 优化思路: 1.减少外层表IO次数,一次性缓存外表多条数据,减少内表扫描次数. 2.无法使用index Nested-Loop Join,默认使用此算法 如何使用: 1.开启优化器管理配置的optimizer_switch的设置block_nested_loop为on 2.默认开启:Show variables like 'optimizer_switc%'; 3.设置join buffer大小,join_buffer_size 影响Block缓存条数 ``` 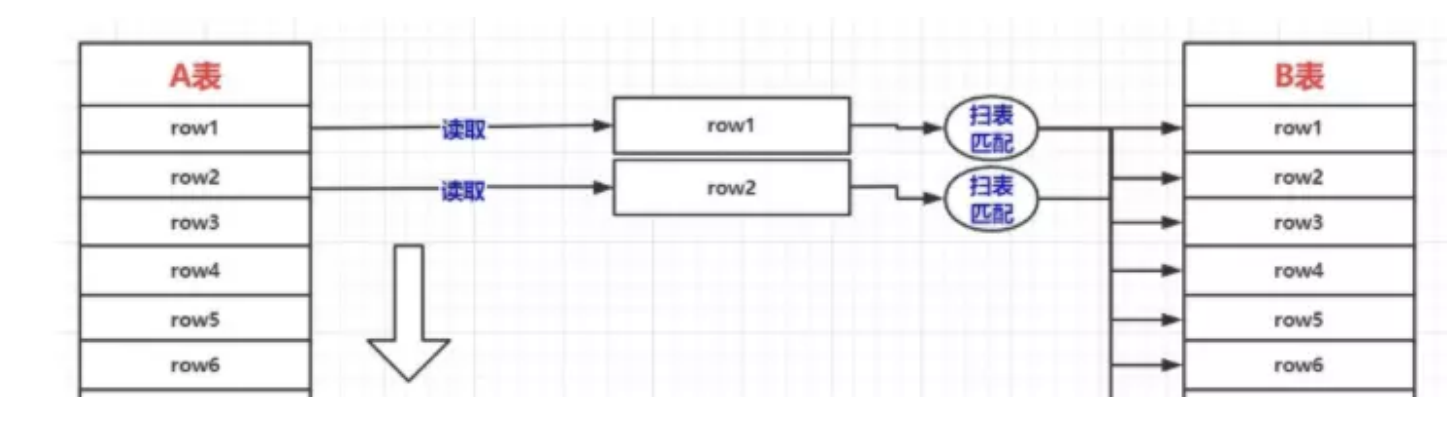 block优化图解 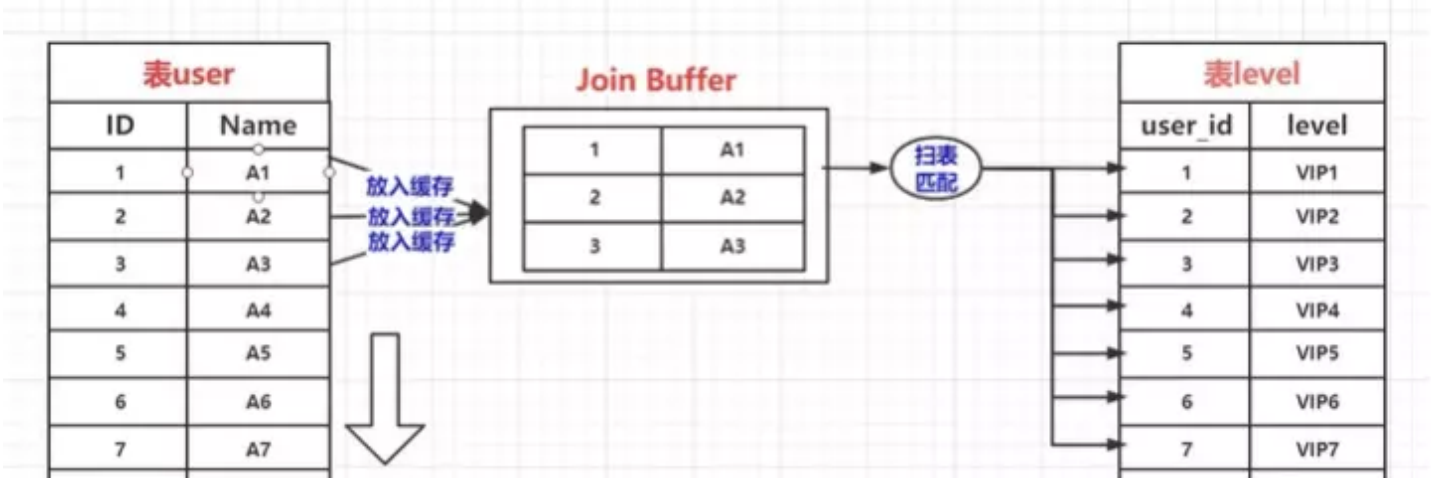 #### 2.3.8.Batched Key Access (BKA) ```sql 作用:提高表join性能,当被join表能使用索引-->先排序--->在检索被join的表, 没有索引使用BNL 使用范围:inner join, outer join, semi-join operations(半连接), including nested outer joins(嵌套外连接) 策略:如果被join表没索引.使用 BNL策略 原理步骤: 1.多表join,访问第二个join表,使用join buffer保存操作产生符合条件的数据 2.BKA算法构建Key访问被连接表,批量使用MRR API提交keys到存储引擎查找 3.MRR获取行反馈给BKA 4.BKA返回给被join表# BNL与BKA区别 1.BNL比BKA出现的早,BKA直到5.6才出现,而BNL5.1里面就存在。 2.BNL主要用于当被join的表上无索引 3.BKA主要是指在被join表上有索引可以利用,对这些行按照索引字段进行排序,因此减少了 随机IO。 相关参数 使用BKA先打开MRR SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on'; ``` #### 2.3.9.Join算法总结 ```sql 1.都是在Simple算法基础上优化, 2.INLJ对join循环匹配次数,BNLJ对IO次数 两个角度优化 3.INLJ通过索引机制,减少内层表循环,BNLJ 缓存外表多条数据批量匹配减少外层表IO次数和 内表扫表次数 4.表连接查询优化思路 - 小结果集驱动大结果集(减少内层表读取的次数) - 匹配条件增加索引(减少内层表循环次数) - 增大join buffer size大小,同时约束业务join的取值数据量级(一次缓存数据多) - Join Buffer会缓存所有参与查询的列而不是只有Join的列。 - 减少不必要字段查询(join buffer缓存数据多) ``` ## 3. 扩展 =========================== ### 3.1 EXPLAIN 结果中每个字段意思 ```sql EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户9999'; ```  当你对一条 SQL 查询使用 `EXPLAIN` 关键字时,MySQL 会为你提供关于查询执行计划的详细信息。这些信息可以帮助你理解 MySQL 是如何执行查询的,包括如何使用索引,以及表的连接顺序等。 下面是 `EXPLAIN` 语句输出的每个字段的含义: 1. `id`:查询中 SELECT 语句的标识符。如果查询中没有子查询或联合查询,则只有一个 SELECT,其 `id` 为 1。如果存在子查询或联合查询,则 `id` 会递增以区分不同的 SELECT。 2. `select_type`:表示 SELECT 的类型,常见的值有: - `SIMPLE`:不包含子查询或联合查询的简单查询。 - `PRIMARY`:最外层的 SELECT。 - `UNION`:联合查询中的第二个或后面的 SELECT 语句。 - `DEPENDENT UNION`:联合查询中的第二个或后面的 SELECT 语句,取决于外部查询。 - `SUBQUERY`:子查询中的第一个 SELECT。 - `DEPENDENT SUBQUERY`:子查询中的第一个 SELECT,取决于外部查询。 3. `table`:查询涉及的表名。 4. `partitions`:查询将访问的分区。 5. `type`:联接类型,从最好到最差的类型依次是: - `system`:表仅有一行(系统表)。 - `const`:表最多有一个匹配行,基于主键或唯一索引。 - `eq_ref`:对于每个从前面的表中检索的行,从该表中基于主键或唯一索引只检索一行。 - `ref`:对于每个从前面的表中检索的行,从该表中基于普通索引只检索几行。 - `fulltext`:使用全文索引。 - `ref_or_null`:与 `ref` 类似,但包括对 NULL 的查询。 - `index_merge`:使用索引合并优化。 - `unique_subquery`:在 IN 子查询中,子查询返回不重复的集合。 - `index_subquery`:在 IN 子查询中,子查询返回可重复的集合。 - `range`:只检索给定范围的行,基于索引。 - `index`:全索引扫描。 - `ALL`:全表扫描。 6. `possible_keys`:查询可能使用的索引。 7. `key`:实际使用的索引。 8. `key_len`:用于查询的索引部分的长度。越短越好。 9. `ref`:列与索引比较的列或常量。 10. `rows`:估计为了找到所需的行而需要读取的行数。 11. `filtered`:按表条件过滤的行的百分比。 12. `Extra`:额外的信息,例如: - `Using index`:使用覆盖索引。 - `Using where`:使用 WHERE 子句来过滤结果。 - `Using temporary`:需要使用临时表来存储结果。 - `Using filesort`:需要额外排序操作,不能使用索引排序。 理解这些字段的含义可以帮助你优化查询性能,例如通过添加索引或重构查询来减少查询的复杂性和资源消耗。 ### 3.2 执行计划跑偏 - 重新收集信息 ```sql mysql> alter table app_user ENGINE=InnoDB; Query OK, 0 rows affected (8.95 sec) Records: 0 Duplicates: 0 Warnings: 0 ``` - force index(idx_name_phone_password) 强制指定索引 ```sql mysql> explain select name,phone,password from app_user where name='用户0' and phone=18399466985 and password='f93758ef-0d93-11ec-99bf-fa2020131854'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: app_user partitions: NULL type: ref possible_keys: id_app_user_name,idx_name_phone_password key: id_app_user_name key_len: 153 ref: const rows: 1 filtered: 5.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) mysql> explain select name,phone,password from app_user force index(idx_name_phone_password) where name='用户0' and phone=18399466985 and password='f93758ef-0 d93-11ec-99bf-fa2020131854'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: app_user partitions: NULL type: ref possible_keys: idx_name_phone_password key: idx_name_phone_password key_len: 464 ref: const,const,const rows: 1 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.00 sec) ``` - 对表做DDL操作触发统计信息 **扩展知识点在线DDL** [MySQL 8.0 Online DDL和pt-osc、gh-ost深度对比分析 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/115277009) ### 3.3 explain应用场景 - 数据库突然hang住,连接数打满 ```sql #分析正在执行的大SQL # sql_mode=only_full_group_by 需要关闭这个 set global sql_mode=''; set SESSION sql_mode=''; 1.select COMMAND,SUBSTRING_INDEX(host,':',1) as ip , count(*), INFO from information_schema.processlist group by ip; 2.explain SQL 3.看索引,看代价,看量级-->联系业务进行处理 explain format=json select user_id, order_id, order_status from t_order where user_id > 1 and user_id < 5\G ``` 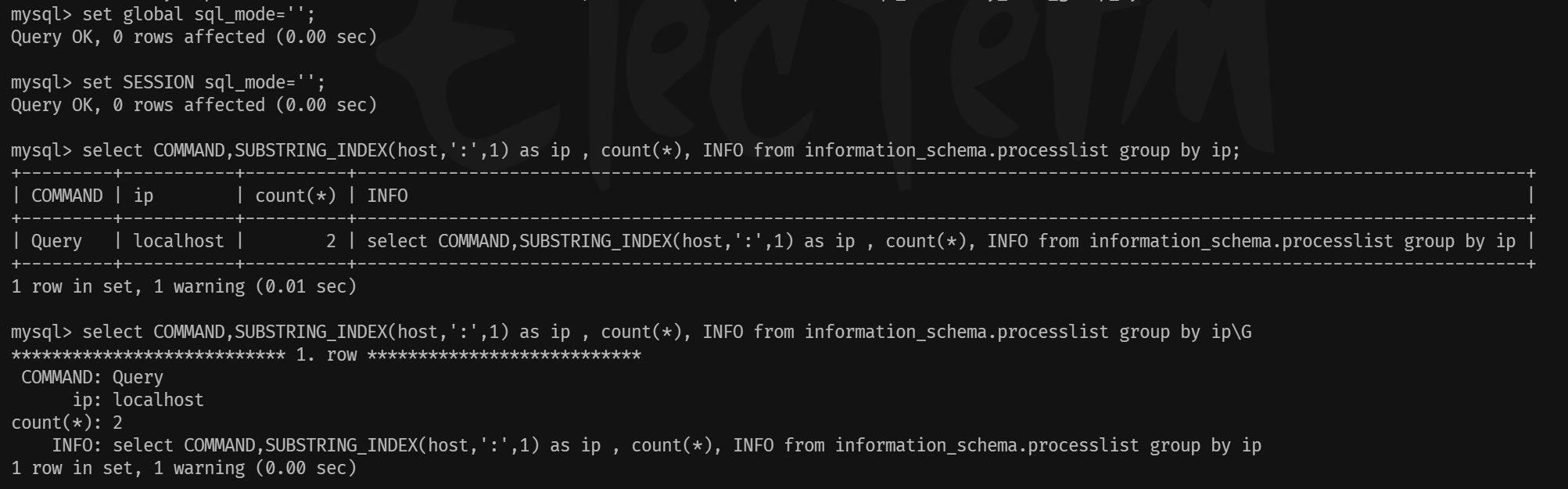 - 日常分析 ```sql 1.分析slowlog 2.找出慢SQL 3.分析执行计划explain 4.优化 ``` ### 3.4 查看未使用的索引 mysql5.7 以上可以使用 ```sql SELECT OBJECT_SCHEMA, OBJECT_NAME, INDEX_NAME FROM performance_schema.table_io_waits_summary_by_index_usage WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA not in ('mysql','performance_schema') ORDER BY OBJECT_SCHEMA,OBJECT_NAME; mysql> SELECT OBJECT_SCHEMA, OBJECT_NAME, INDEX_NAME FROM performance_schema.table_io_waits_summary_by_index_usage WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA not in ('mysql','performance_schema') ORDER BY OBJECT_SCHEMA,OBJECT_NAME; +---------------+-------------+-------------------------+ | OBJECT_SCHEMA | OBJECT_NAME | INDEX_NAME | +---------------+-------------+-------------------------+ | school | app_user | PRIMARY | | school | app_user | id_app_user_name | | school | app_user | idx_name_phone_password | +---------------+-------------+-------------------------+ 3 rows in set (0.10 sec) ``` ### 3.5 mysql主机CPU高排查 ```sql #top us 看慢查询 sy 看锁、连接数 wa IO高,磁盘坏了,高并发写入 iostat -x 1 或看 bin_log # pmm mysql 监控 https://www.cnblogs.com/cyh00001/p/16702209.html ```
李延召
2024年3月15日 21:53
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码