DBA专题
DBA授课
DBA公开课
DBA训练营三天
01.Mysql基础入门-数据库简介
02.Mysql基础入门-部署与管理体系
03.MySQL主流版本版本特性与部署安装
04.Mysql-基础入门-用户与权限
05 MySQL-SQL基础2
06 SQL高级开发-函数
07 MySQL-SQL高级处理
08 SQL练习 作业
09 数据库高级开发2
10 Mysql基础入门-索引
11 Mysql之InnoDB引擎架构与体系结构
12 Mysql之InnoDB存储引擎
13 Mysql之日志管理
14 Mysql备份,恢复与迁移
15 主从复制的作用及重要性
16 Mysql Binlog Event详解
17 Mysql 主从复制
18 MySQL主从复制延时优化及监控故障处理
19 MySQL主从复制企业级场景解析
20 MySql主从复制搭建
21 MySQL高可用-技术方案选型
22 MySQL高可用-MHA(原理篇)
23 MySQL MHA实验
24 MySQL MGR
25 部署MySQL InnoDB Cluster
26 MySQL Cluster(MGR)
27 MySQL ProxySQL中间件
相信可能就有无限可能
-
+
首页
17 Mysql 主从复制
# 1.复制简介 ```sql 1.目的 - 解决MySQL单点故障和提升MySQL的整体服务性能,一般采用主从复制.比如大SQL或者备份导致锁表从而影响业务流量(dml,dql),从而影响用户的体验度。 - 主从复制,读写分离-->数据库能支撑更大并发 - 保证数据安全 - 解决单点故障,保证服务持续运行 - 备份 - 迁移 2.角色: - 分为主服务器(master)和从服务器(slave)。 - 主服务器服务可主要写流量和轻TP类查询 - 从服务器负责备份,负责读流量复杂查询,binlog流式传输 3.基本原理:将主库的binlog(记载DML和DDL操作)传输给从库,从库进行日志回放,变成SQL在从服务器同步数据,根据同步级别不同保证近实时的数据副本。 4.主要主从架构类型: - 一主一从(or 两从)+MHA(没有高可用的主从没有意义),轻量级MySQL使用姿势 - 双主(主主复制) - 级联,也叫链式复制 - 半同步复制 - 延迟复制 - 多源复制 ``` ## 1.1.主从复制原理 ### 1.1.1.整体流程 ```sql 1.三个线程 - master:(binlog dump thread) - slave: - I/O thread - SQLthread 2.步骤(简易流程) - Master节点进行insert、update、delete操作时,会按顺序写入到binlog中 - salve从库连接master主库,Master根据slave个数创建binlog dump线程。 - Master节点binlog发生变化 - binlog dump线程通知所有slave节点 - binlog dump线程将Binlog增量内容event方式推送给所有slave节点 - Slave节点: - I/O线程收到binlog events后,写入本地relay-log - SQL线程读取relay-log,根据relay-log内容转化成sql同步数据,并将应用记录存放relay-log.info 3.主库复制步骤简介 - 多个mysql实例 - server_id不同 - server_uuid不同 - 主库开启binlog - 搭建从库 - 备份数据(点位或gtid) - 逻辑备份mysqldump - XBK(dump-slave参数从库备份告知主库点位) - 空库搭建 - 从库连接主库(DBA命令 change master) - 启动复制线程(start slave) - 查看复制状态(show slave status) - 监控复制流程(监控+报警) ``` - 简易版 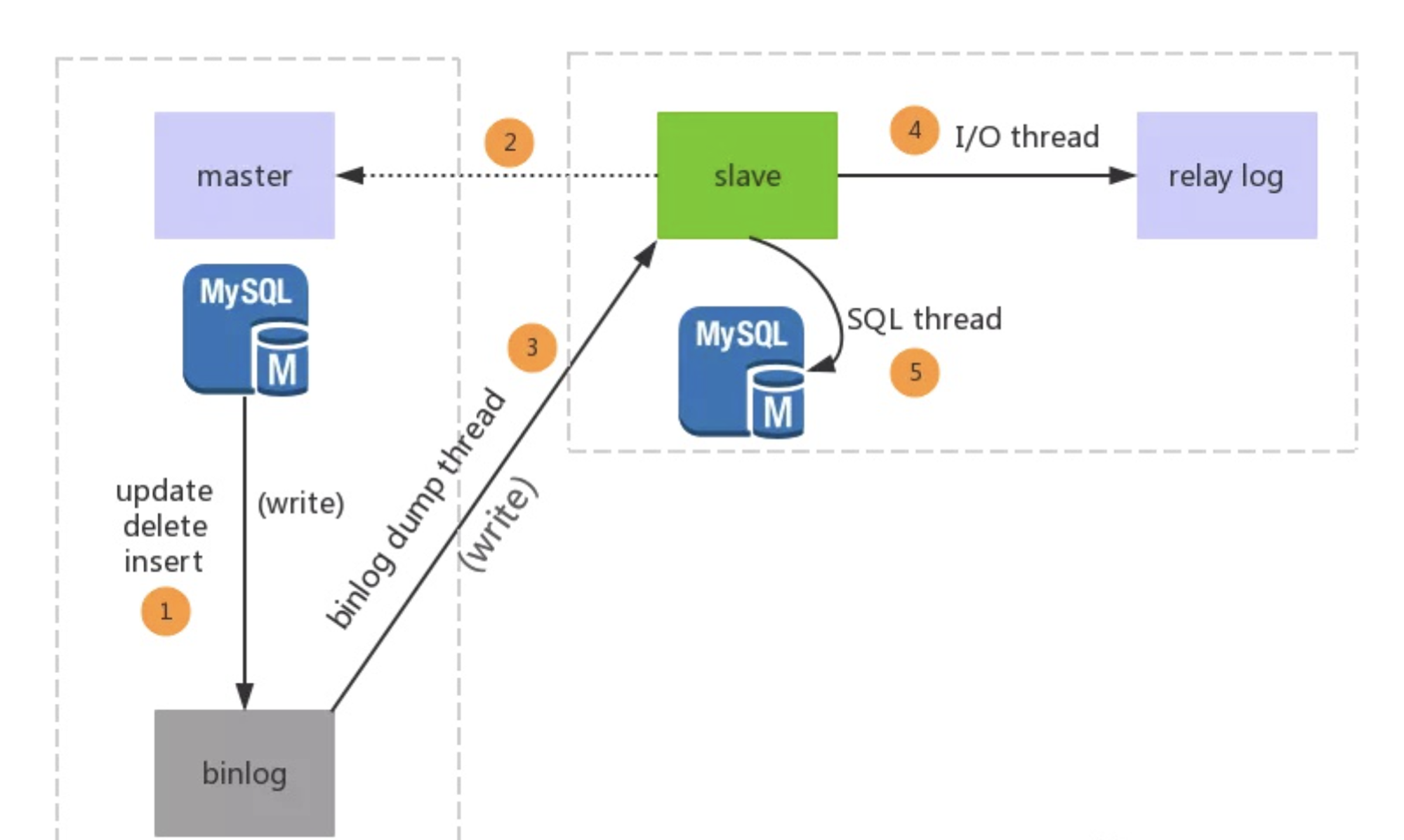 - 详细版 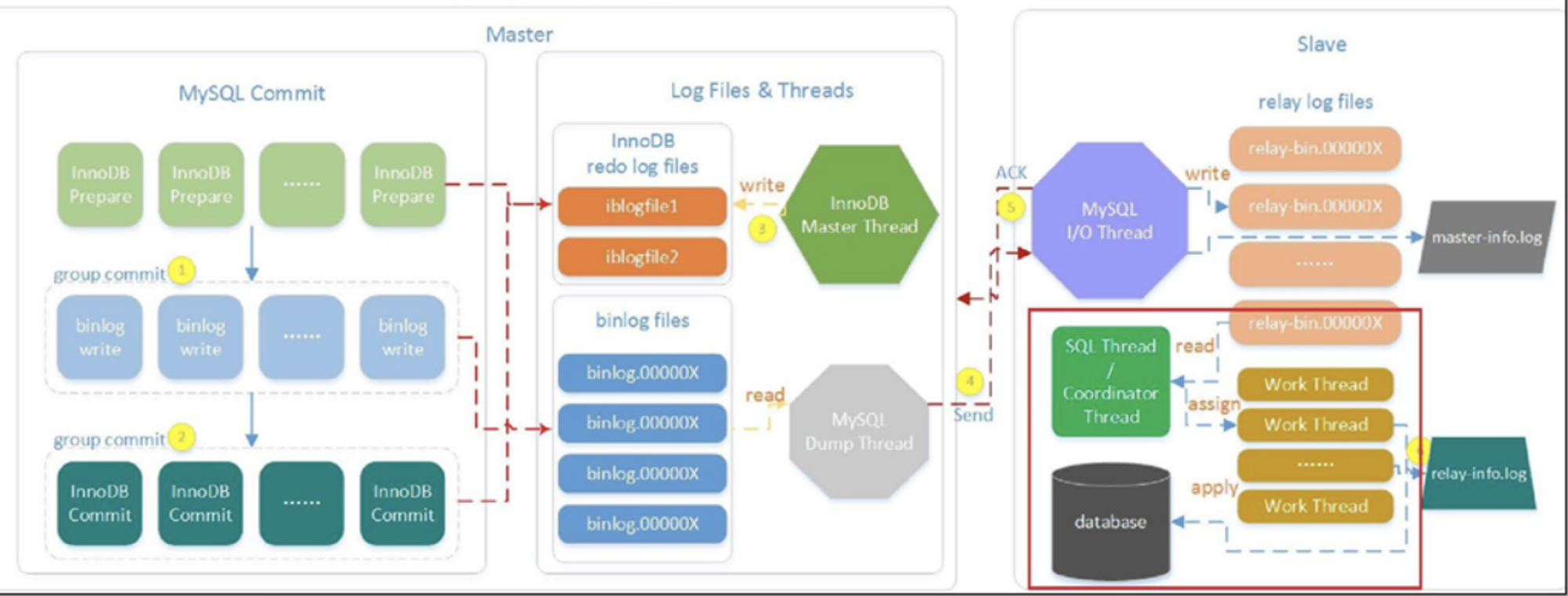 - pos+file版 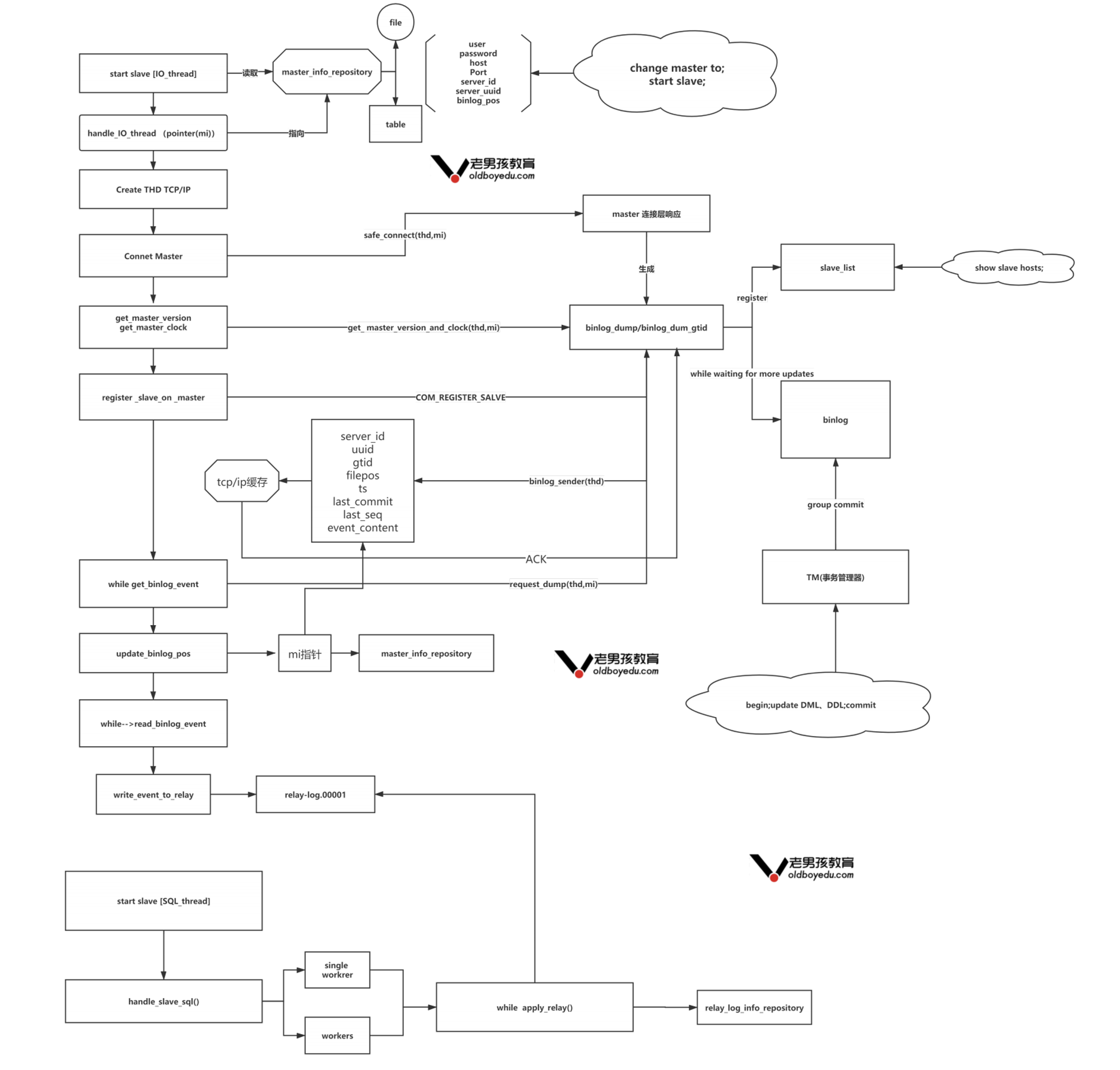 - GTID版 ```sql gtid格式 : a. MASTER 发生事务,生成GTID,记录binlog。 b. slave 根据gtid_next请求下一个GTID的事件。 c. Master 发送 binlog到SLAVE. d. slave 接收二进制日志,存储至relaylog,读取gtid信息并设置gtid_next值。 e. slave SQL 回放GTID事务。 1. 检测本地binlog是否有该GTID 2. 应用事务,并更新本地binlog(log_slave_updates) 3. 已执行的gtid信息更新至mysql.gtid_executed表中,并定期进行压缩。 ``` 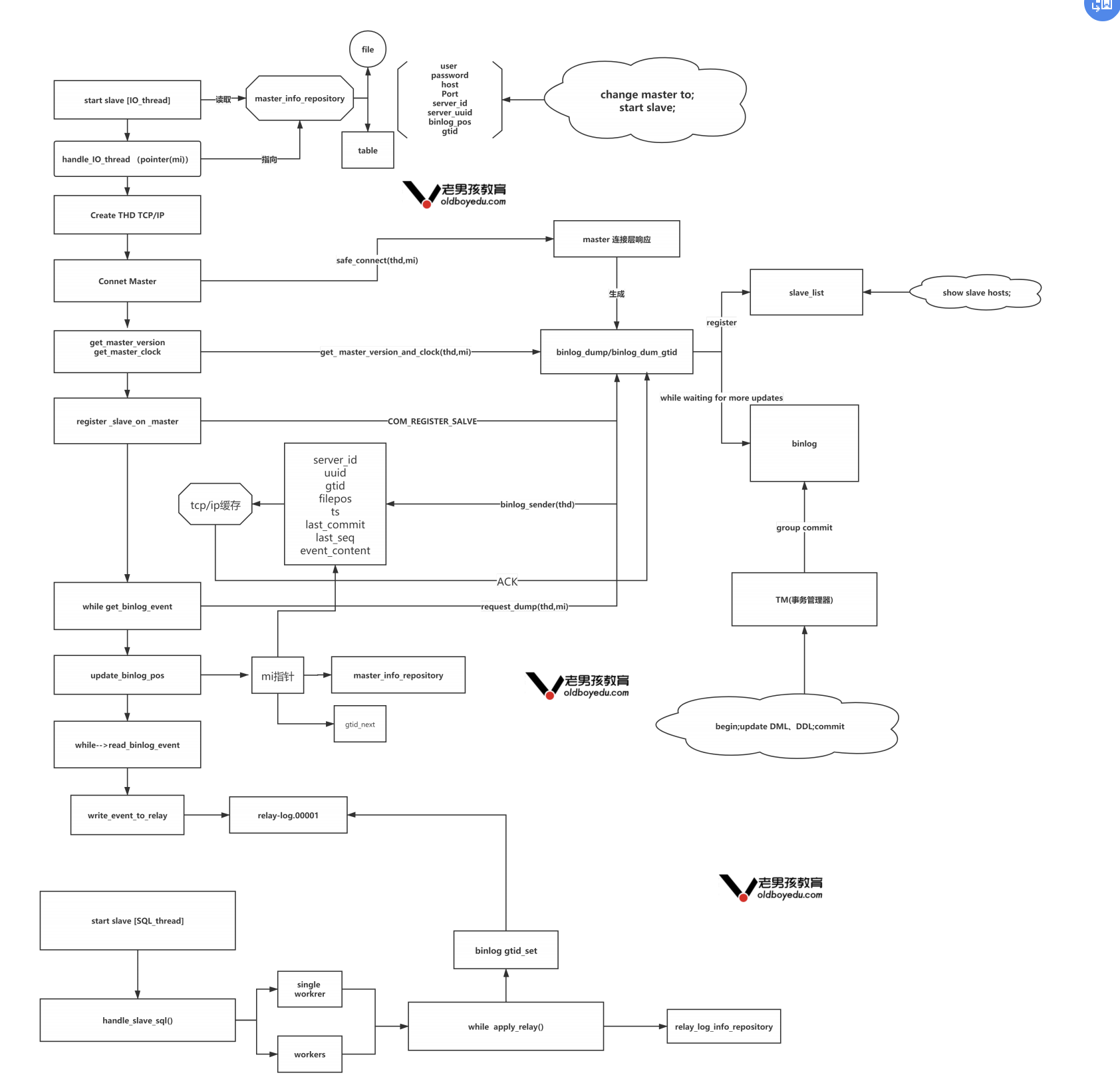 # 2.主从复制流程细节 ## 2.1.主库 ### 2.1.1.binlog_cache - 简介 ```sql 1.执行DML语句-->向Binlog cache写入event-->落盘到binlog 2.事务event在commmit才真正写入binlog,之前在binlog cache存放 ``` - binlog_cache 结构-trx_cache ```sql - binlog_cache主要由IO_CACHE实现,其中trx_cache包括 - binlog cache缓冲区: binlog_cache_size 控制 - binlog cache 临时文件: max_binlog_cache_size 控制 ``` 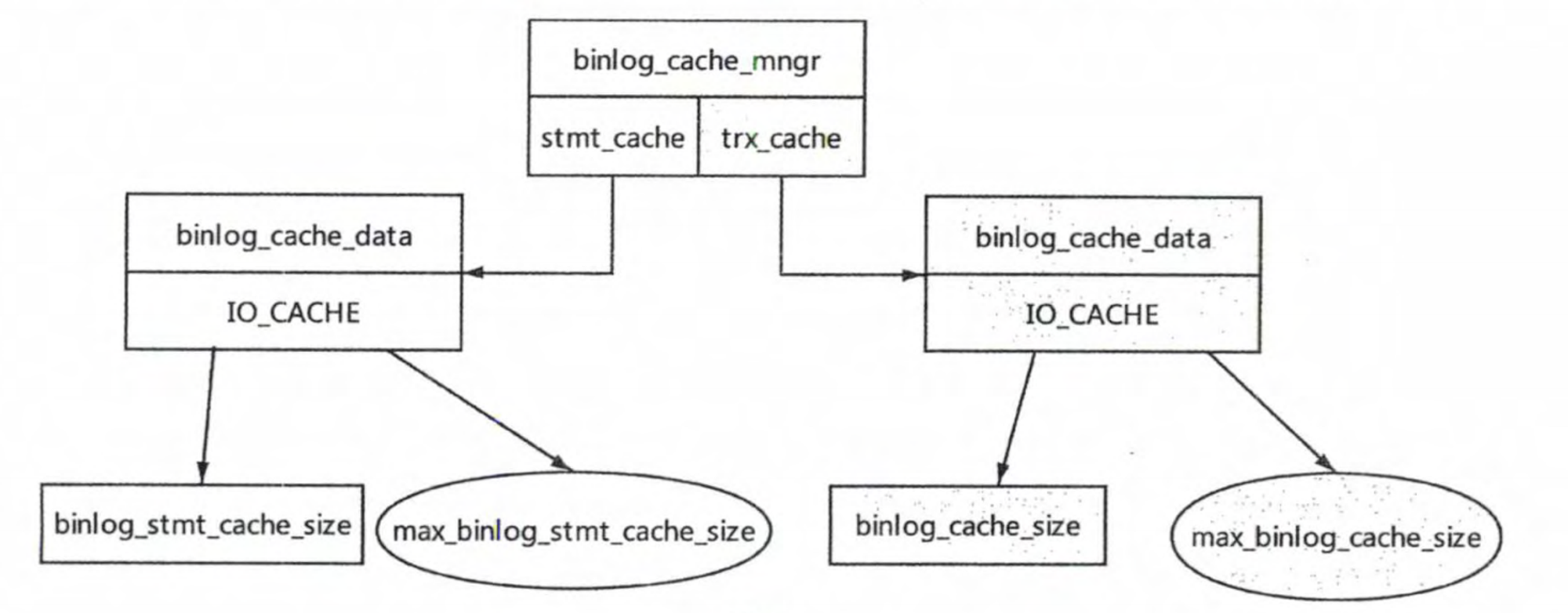 - binlog cache 使用流程 ```sql 一.流程 1.开启读写事务 2.执行DML语句,分配内存空间给binlog cache缓冲区 3.执行DML语句生产的Event不断写入binlog cache缓冲区 - cache满,写入binlog cache临时文件,清空binlog cache缓冲区 - 临时文件以ML开头(存放在tmpdir目录),如果是filesort临时文件则MY开头 - 源码 open_cached_file()函数 4.事务提交 - binlog cache缓冲和文件数据全部写入binlog持久化 - 释放Binlog cache(保留提供下次事务使用)缓冲区和binlog cache临时文件(大小截断为0,保留文件描述符),也就是保留IO_CACHE结构分配的内存空间和文件描述符 5.断开连接(session),释放IO_CACHE binlog cache内存和临时文件 二.binlog_cache_size参数作用及初始化 1.binlog_cache_size介绍 - 会话级别参数 - 开启binlog在事务执行期间保存Event缓存大小 - 经常有大事务调高,避免过多使用物理磁盘 - 查看使用次数 - show status like '%Binlog_cache_disk_use%'; - show status like '%Binlog_cache_use%'; ``` - 生产:Binlog_cache_disk_use使用过多需要加多参数 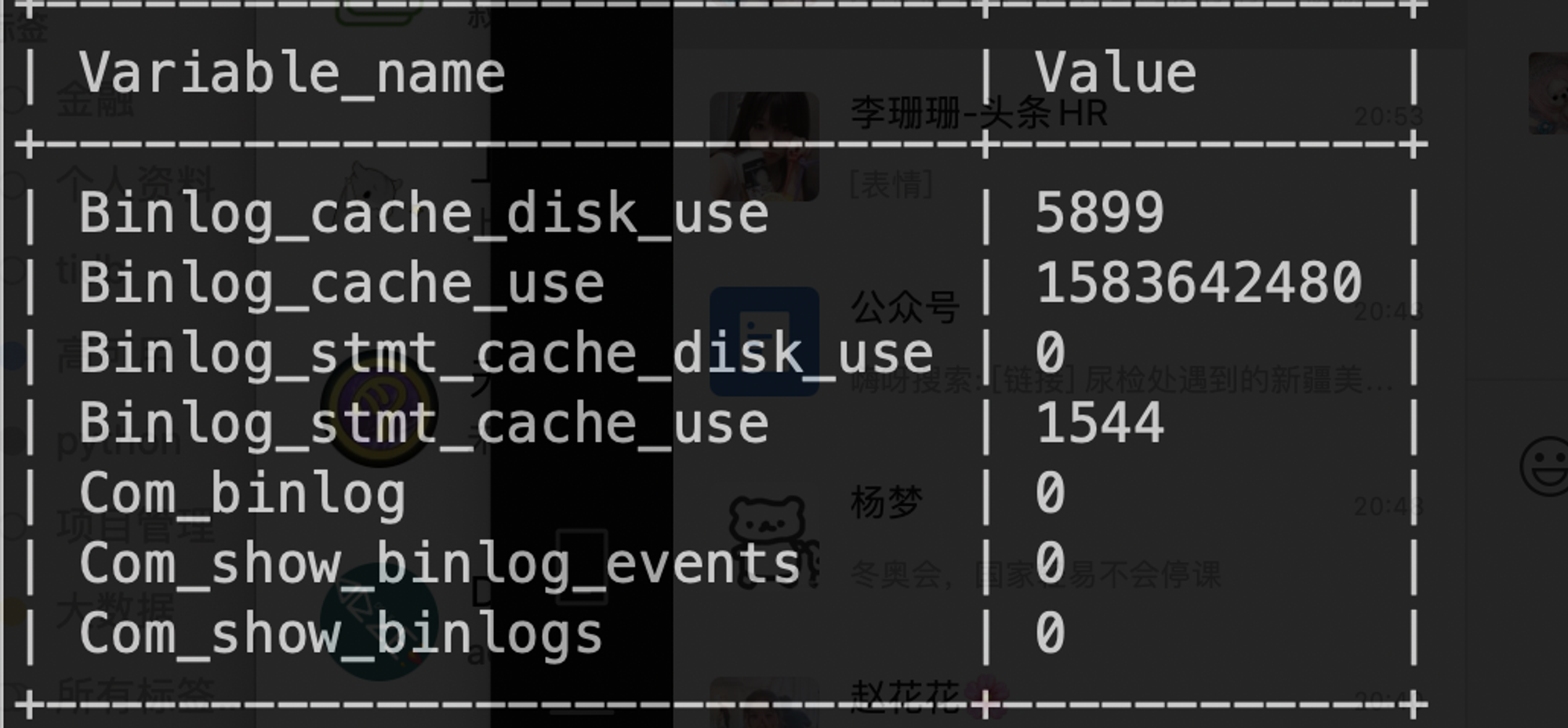 - binlog cache file使用流程 ```sql 1.简介: - binlog cache 缓冲区存不下,用临时文件存储 - Linux ls看不到(使用了Linux临时文件建立的方法),lsof|grep cache查看 - 建立方式 - 源码create_temp_file函数 - 调用my_b_flush_io_cache函数 - binlog cache写满,数据写入临时文件 - 清空binlog cache缓冲区 - binlog_cache_disk_use统计+1 2.max_binlog_cache_size作用 - 会话级别参数,binlog cache临时文件最大容量 - 某个事物Event总量大于参数 max_binlog_cache_size+binlog_cache_size报错 ``` ### 2.1.2.事物Event的生成和写入binlog流程 - 以DELETE DML为例 ```sql 1.流程 1.1.删除阶段 - InnoDB 层删除了一行数据,并且返回删除的这行数据。 - 第一条语句的第一条数据,生成 query_event,写入binlog_cache - 每条语句第一行数据,生产MAP_EVENT,写入binlog cache - 根据binlog_row_image设置字段过滤,留下需要的字段数据 - 生产DELETE_EVENT,删除数据写入EVENT - 大于8kb,新建一个DELETE_EVENT,上一个写入binlog_cache - 数据删除完成后最后一个DELETE_EVENT写入binlog_cache - 如果cache不够则写入binlog cache file 1.2.提交阶段 - 生成XID_EVENT,写入binlog_cache - 生产GTID_EVENT,event写入binlog(不写入binlog cache) - binlog cache一次性写入binlog - 大事务性能根源大量Event一次性写入binlog堵塞其他事务提交 - 清空binlog cache缓存和文件 注意: 1.GTID_EVENT直接写入binlog,因此GTID_EVENT是事务第一个Event 2.XID和GTID是commit阶段生产 - 显示事务:XID_EVENT和GTID_event为commit发起时间 - 其余DML是命令发起时间 ``` 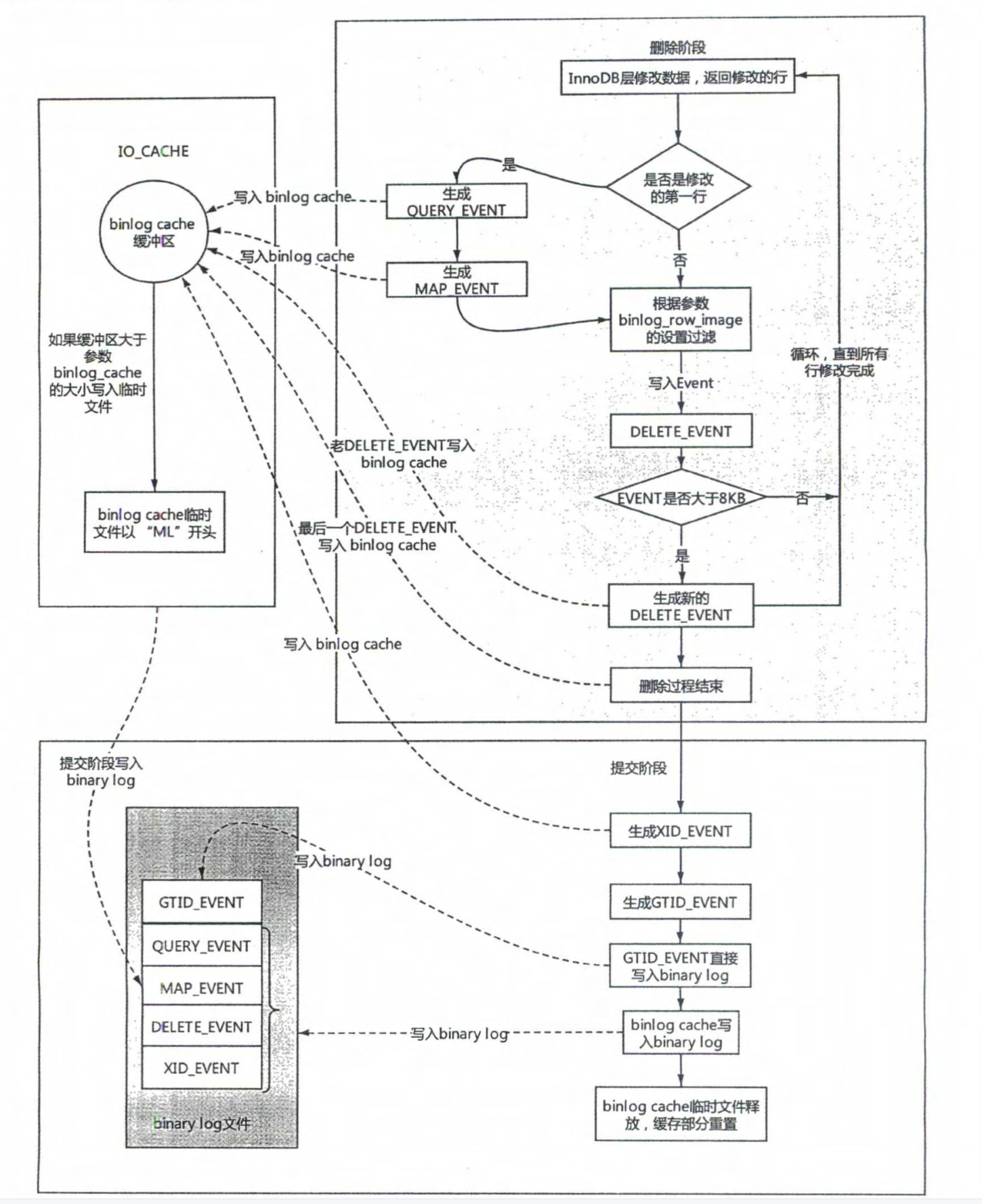 ### 2.1.3.MySQL层事务提交流程(2PC) - 参数设置 ```sql 1.binlog_group_commit_sync_delay:0 - binlog提交多少后等待延时多少秒刷盘,默认0,最高1s - 设置延时可以多个事务一起提交 - 提交binlog提交并发和slave吞吐 - 主库执行时间laentcy变长 2.binlog_group_commit_sync_no_delay_count: O - 延时提交的最大事务数,默认0,与时间一起使用。 3.binlog_order_commits: ON - 提交事务是否按照而写入二进制binlog顺序提交 - 可获得commit阶段的性能提高 4.sync_binlog:1 - 双一 不在赘述 5.binlog_transaction_dependency_tracking(5.7.22参数): COMMIT ORDER - 控制binlog文件中last_commited计算方式 - COMMIT ORDER:即group commit,binlog last_committed传到从库并行执行 - writeset:对事务处理行数据hash出一个set值,放进hash表,如果两个事务先后提交但无冲突(操作同一个行)则在从库并行执行 - writeset_session,比writeset多了一个约束,同一个session的事务,在binlog里保留先后顺序,也就是last_committed按先后顺序递增。 ``` - 2PC流程图(加强版) ```sql 1.prepare阶段 - 获取MDL commit锁 - binlog prepare:讲COMMIT队列最大的seq number写入本次事务的last commit - InnoDB prepare:更爱事务状态,写入Undo - 生产XID event写入binlog_cache 2.FLUSH阶段 - 形成FLUSH队列:事务加入flush队列,第一个加入队列为leader线程,其余非leader线程阻塞等待leader 线程commit阶段唤醒 - 获取lock log - flush固化:这一队列事务已经不能更改,队列取出准备处理 - InnoDB redo持久化 - 生产GTID,seq number,last commited,生产GTID_EVENT,写入binlog(事务的第一个Event) - Transaction_depenaency_tracker为COMMIT则 - 每次事务提交,seq number +1 - last commited在binlog准备阶段赋值给每个事务 - last commited是前一个COMMIT队列的最大 seq number - last commited和seq number为Logical_clock,维护offset(偏移量)的值. - binlog cache里所有Event写入OS CACHE(其中一个包含 QUERY_EVENT,map_event ,dml_event,xid_event) - 是除了gtid_event意外的其他event - 写入binlog调用的是linux的write函数 - 判断binlog是否需要切换+设置切换标记 - 每个队列每个事务写入event+现有binlog是否大于max_binlog_size(所以大事务来说Event肯定是包含一个binary log中) 3.SYNC阶段 - FLUSH队列加入SYNC 队列: - 第一个进入 FLUSH 队列的 leader线程为本阶段leader 。 - 其他加入SYNC 队列,被LOCK 到commit阶段被leader线程唤醒 - 方式LOCK log - 获取Lock sync - 根据delay设置决定FLUSH进入固化时间 - delay越久,加入sync队列的flush队列可能越多-->sync事务多 - 提高sync效率 - 增加group commit组成员数据(last commited还没改) - 缺点:导致DML语句时间变成 - 参数 - binlog_group commit_sync_delay:延长delay时间-->增加commit group提交数量,减少磁盘sync次数,最大1s - binlog_group_commit_sync_no_delay_count:group commit数量达到值进入固化阶段 - 将sync阶段固化 - 根据sync_binlog决定事务是否刷盘,如果是1,直接唤醒dump线程发送event 4.COMMIT阶段 - SYNC队列加入COMMIT队列 - 第一个加入SYNC队列leader线程为本阶段leader线程 - 其余加入sync队列加入commit队列(leader被LOCK COMMIT阻塞),最后被leader唤醒 - 释放LOCK SYNC - 获取LOCK commit - 根据binlog_order_commits 决定是否按照InnoDB层事务提交 - 固化COMMIT 队列,准备处理-->成为一个group commit - 更改last_commit: - commit队列每个事务都会尝试更新 - 事务当前seq_number大于last_commited更新,小于不变 - 事务按照顺序进行InnoDB层提交 - undo状态更新 - InnoDB释放锁资源 - 释放LOCK COMMIT 5.收尾 - leader唤醒其他组内成员 - 事务情况自己的binlog cache内存和文件,但不释放 - 判断是否切换binlog 注意: 1.COMMIT队列>=SYNC队列>= FLUSH队列(数据库压力不大则都为1) 2.并行回放取决于last_commited 3.大事务Event提交一次性写入binlog,也即是commit阶段会阻塞,这也是MySQL不适合大事务的原因 ``` ### 研讨:writeset和writeset_session的方式 - 简易版 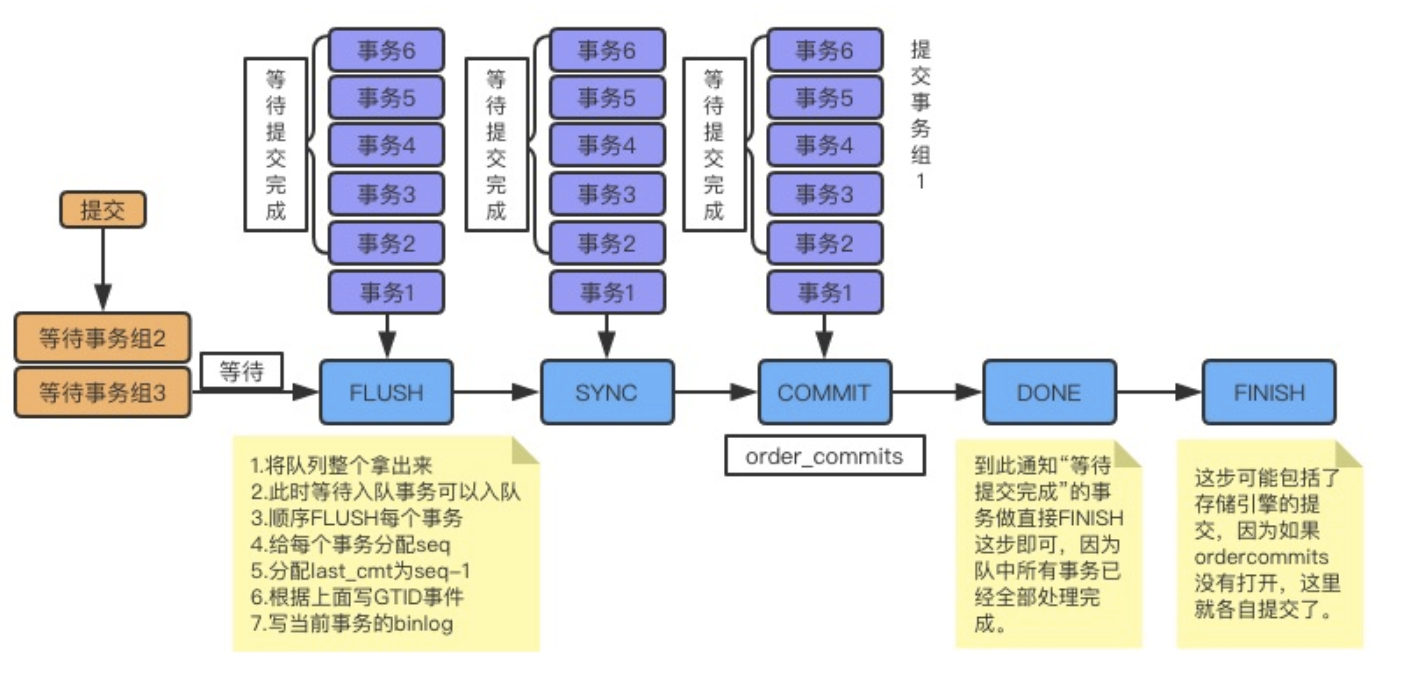 - 完整版 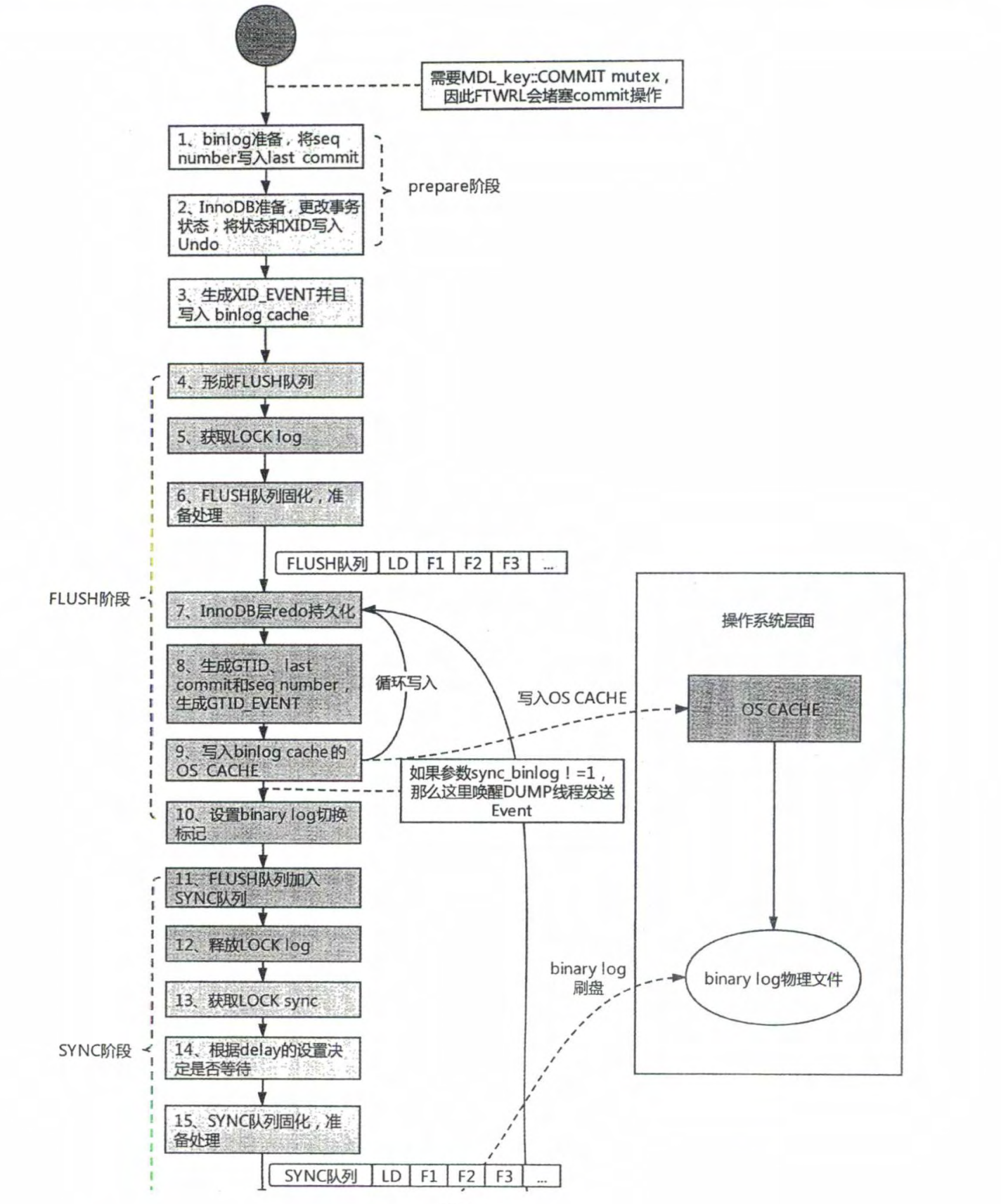 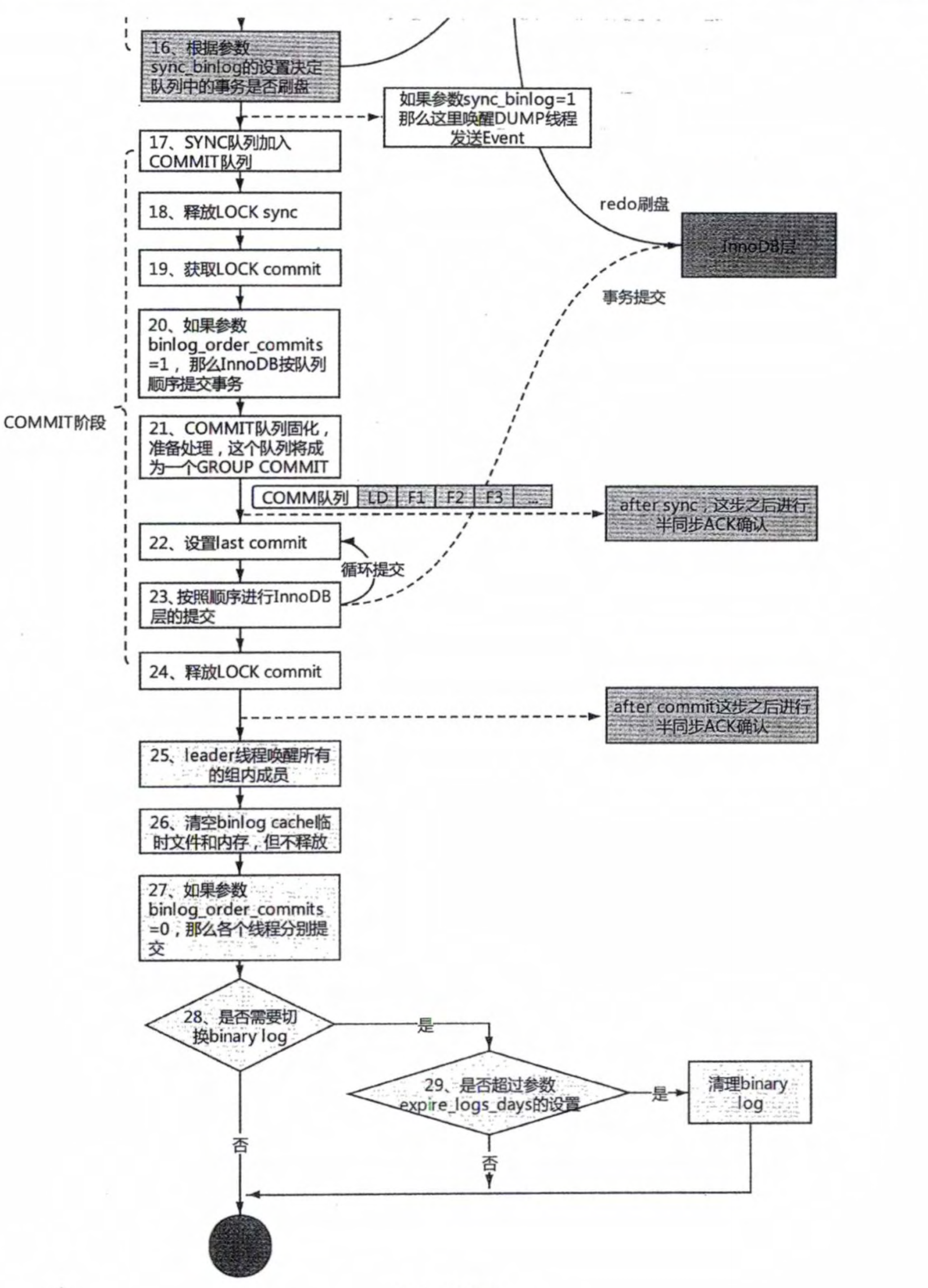 ### 2.1.4.主库的DUMP线程 1.介绍 ```sql 目的:发送event给从库 分类:GTID MODE和 POSITION MODE 启动流程 使用函数: - postiion:com_binlog_dump - 使用I/O线程给的log name和postion进行主库binlog定位 - GTID:com_binlog_dump_gtid - 使用从库的gtid set信息进行主库binlog查找过滤,知道位置 ``` 2.整体流程 ```sql 1.读取信息(点位) 2.杀死slave老的dump线程 3.检查binlog和server_id 4.判断是否GTID mode(二进制就直接定位) 5.检查GTID是否开启 6.检查从库GTID SET是否大于主库GTID SET - sync_binlog参数第二功能 - 不为1,则flush阶段发送event给从库,可能从比主多事务 - 为1,sync阶段发送event 7.根据主库的gtid_purged检查从库需要的 GTID Event 是否已经被清理 8.实际扫描主库的 binary log, 检查从库需要的 GTID Event 是否已经被清理 - 如果主库binlog被误删,则需要判断扫描主库binlog - 扫描binlog作为DUMP线程发送起点 - 扫描最后一个binlog,拿到PREVIOUS_GTIDS_LOG_EVENT.检查需要GTID是否在这个数后面,是则结束,不是检查上一个binlog - 循环找到binlog文件 - 如果主从延时高+设置relay_log_recover=ON,则Retrieved_Gtid_Set不初始化, - 使用从 Executed_Gtid_Set查,需要时间可能长最大到几十秒(扫描binlog多) 9.循环binlog,读取event - 初始化IO CACHE循环读取binlog中的event - 读取完则sleep等待唤醒 10.三项检查 11.过滤GITD发送给从库的I/O线程 12.读取下一个binlog ``` 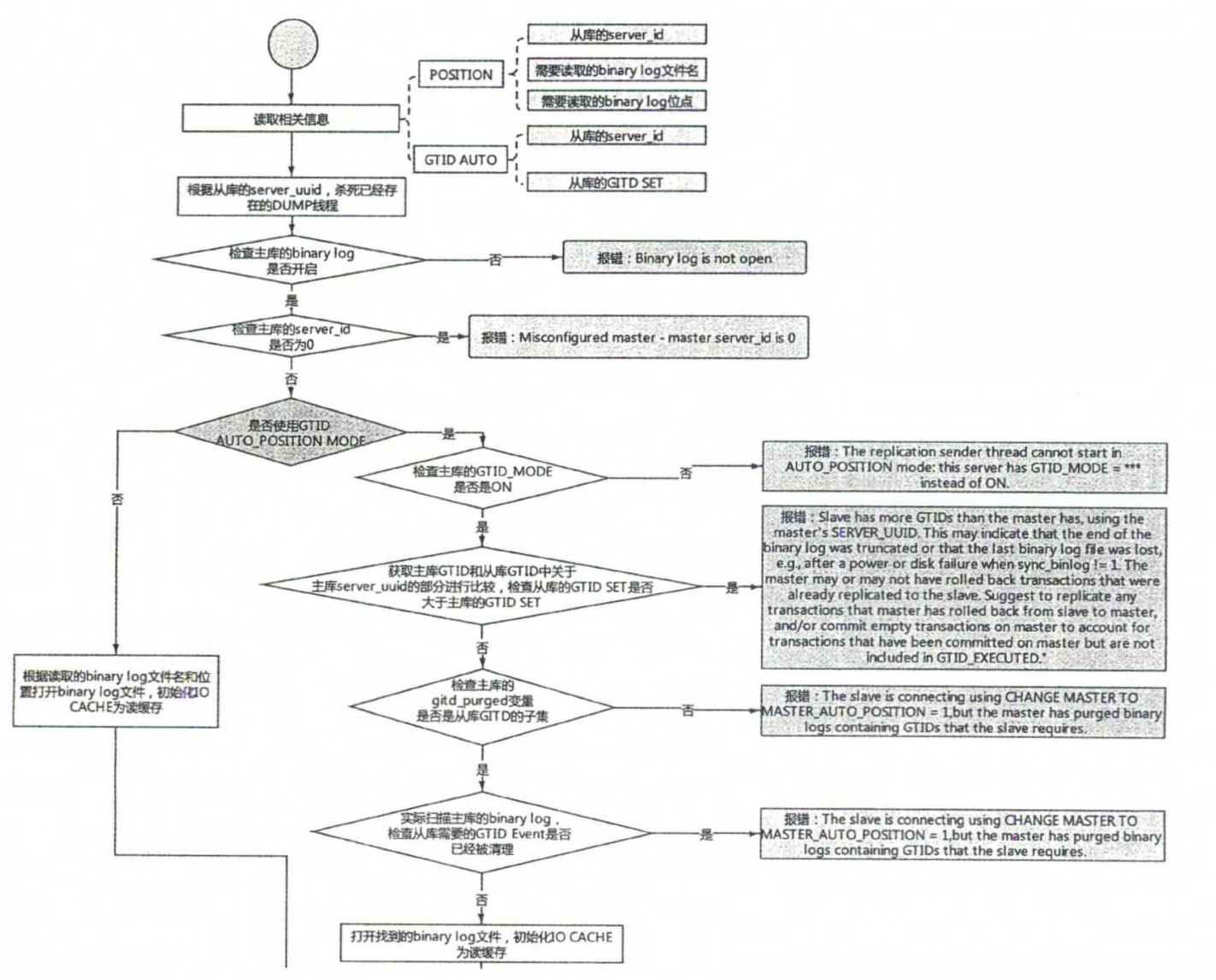 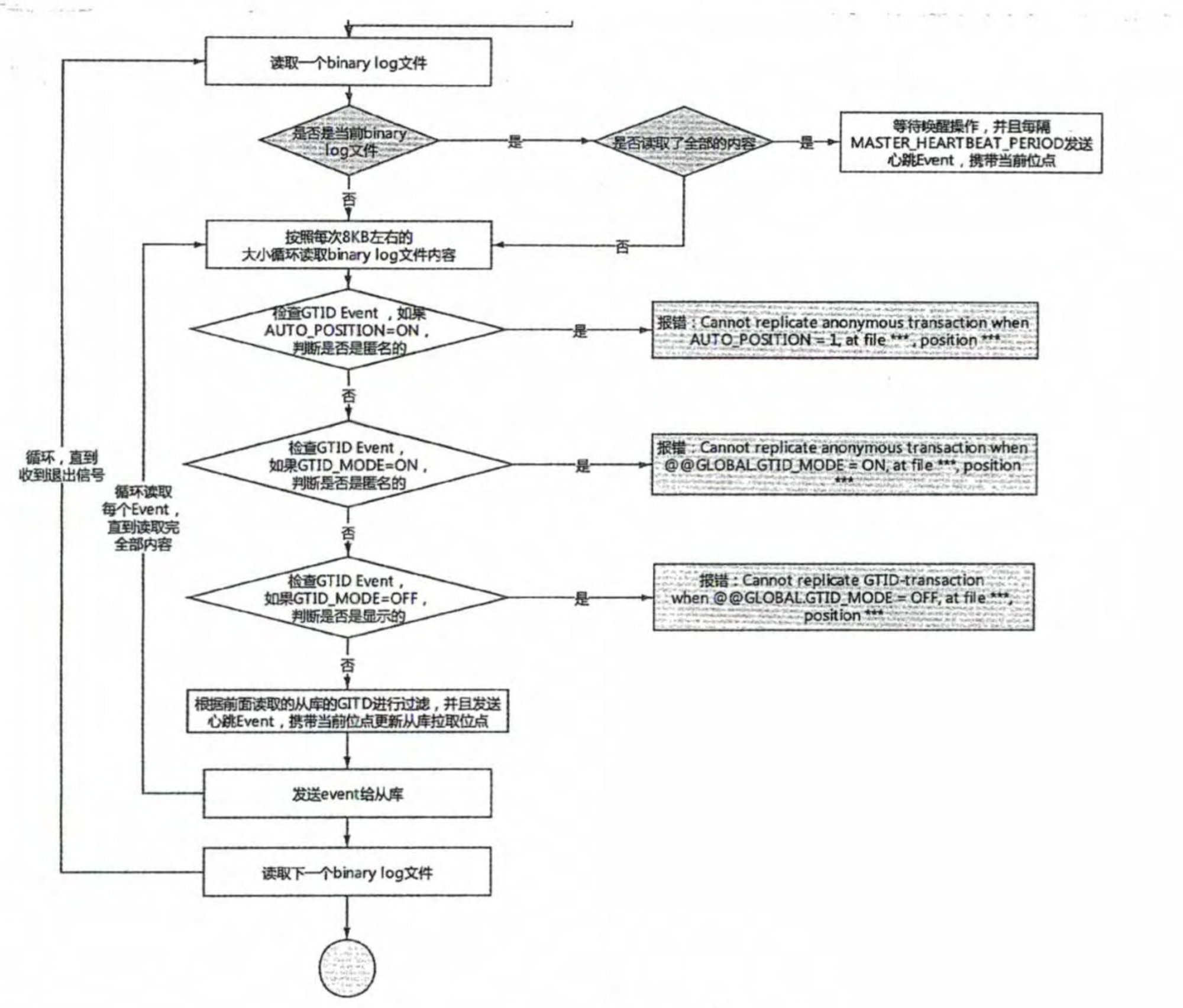 ## 2.2.从库 > IO:从库接收event+ SQL:回放成SQL到从库 ### 2.2.0.从库MTS版本优化 - 5.6.之前,仅有一个I/O和一个SQL线程 ```sql 效率过低,因为主从的事务是同事多个 ``` - 5.6,有了基于库级别并行复制,SQL线程变成coordinator(协调者)线程: ```sql 1.场景 - 多库 - 每个库使用均匀 2.SQL线程工作 - SQL线程协调多个worker并发执行sql并负责检查 - DDL操作则等待worker执行完后再继续 3.问题 - creash safe有问题:处理并行复制关系逻辑比较复杂 - 效率不高,单库多表是常见 ``` - 5.7.MTS ```sql 1.改进 - group commit: - 对事务进行分组,优化生产二进制日志操作数 - 既然事务在主能提交成功,则证明之间没有锁冲突(数据冲突),则从也可以并行 - 在prepare事务可以并行提交(如果有冲突,则会有先后顺序,有冲突不可能一起提交) - 参数slave-parallel-type - LOGICAL_CLOCK(基于组提交的并行复制方式)。slave_parallel_workers(并行复制参数) - 如果没有开启GTID,则会用Anonymous_Gtid(匿名GTID),记录组提交的信息(不建议,会有问题) ``` - 8.0.writeset的MTS解决了这个问题(作业留存) ### 2.2.1.从库MTS流程 - 介绍 ```sql - SQL线程蜕变成协调器(负责检查点),新增worker线程回放事务 - 仅讨论LOGICAL LOCK 并发方式 - 参数 slave_parallel_type: LOGICAL_CLOCK - 参数 slave_p arallel_workers: 4 - 从库持久化MTS信息的三个地方(如果参数为TABLE) - slave_master_info表:I/O线程更新,Event个数 - relay_log_info_repository表:SQL协调线程执行检查点更新 - slave_worker_info表:线程每次提交事务时候更新 ``` - 流程解析(深入-高级DBA) ```sql 1.EVENT加入 GAQ队列 - GAQ队列:协调线程维护,环形队列,记录分发的事务 2.获取last_commit和seq number,current_lwm值(最早未提交事务的前一个提交事务的seq_number) 3.比较last commit和current_lwm - last commit<=current_lwm:事务进队列,等待并行回放 4.等待空闲工作线程获得Event分配 5.回放Event ``` 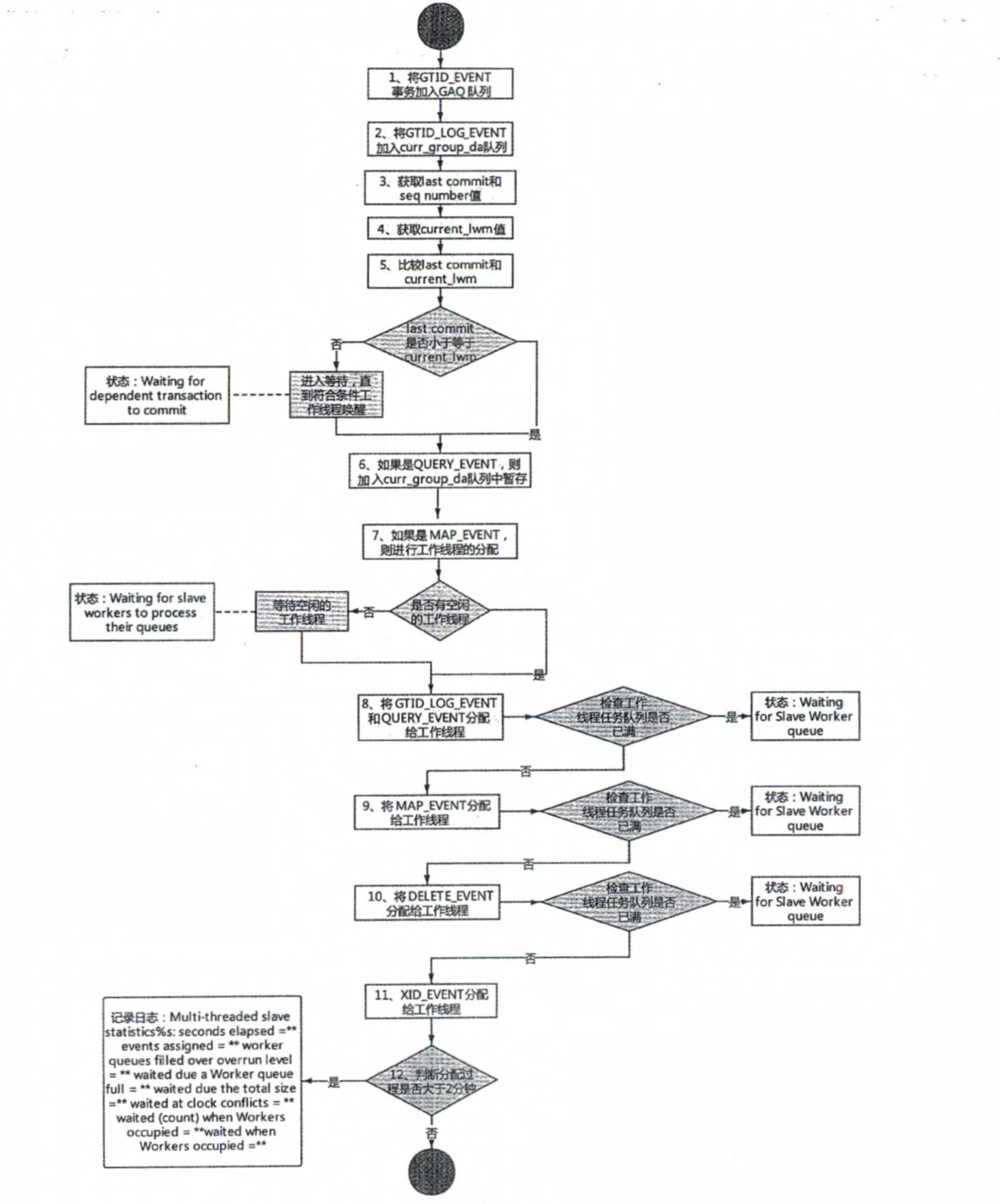 ### 2.2.2.I/O线程 - 主要功能 ```sql - 初始化讲需要读取信息发送给主库 - 接受来自DUMP线程的EVENT - 将EVENT写入relay log ``` - 流程(高级DBA) ```sql 1.使用slave_master_info中的从库信息进行连接 - MASTER_CONNECT_RETRY: 每次重连间隔时间,默认为 60 秒。 - MASTER RETRY_COUNT: 重连的次数,默认为 86 400 次。 2.获取主库重要信息 - 发起命令 SELECT UNIX_ TIMESTAMP() 获取主库时间,计算主从延时 - 发起SELECT @@GLOBAL.SERVER_ID 获取主库 server id,比较与从库server_id是否相同 - 发起令 SELEC @@GLOBAL.GTID_MODE,获取主库GTID_MOED设置(是否是匿名事务) - 发起令 SELECT @@GLOBAL. SERVER_ UUTD 获取主库的 serve _uuid.一致则报错 3.注册从库信息 - 调用register_slave函数进行从库注册 - 完毕后show slave status看到从库 4.发送需要读取的GTID SET和POSITION信息给主库 - 给主库的DUMP线程 - GTID SET是Retrieved_ Gtid _ Set和Executed_Gtid Set的并集 - 主库调用com_binlog_dump_gtid函数 5.网络层读取Event 6.写入Event到relay log - 调用queue_event函数 - 监测是否合法 - Cannot replicate GTID-transaction when @@GLOBAL.GTID_MODE = OFF; - Cannot replicate anonymous transaction when AUTO _POSITION = 1; - Cannot replicate anonymous transaction when @@GLOBAL.GTID_MODE = ON 7.持久化信息 - event写入relay log后,持久化这些信息 - 根据sync_relay_log设计,绝对relay_log执行fsync.单位是Event个数(会影响从库性能) - 根据sync_master_info,更新slave_master_info(Event个数) - 事务结束更新Retrieved Gtid _ Set ``` ```sql 1.使用slave_master_info中的从库信息进行连接 - MASTER_CONNECT_RETRY: 每次重连间隔时间,默认为 60 秒。 - MASTER RETRY_COUNT: 重连的次数,默认为 86 400 次。 2.获取主库重要信息 - 发起命令 SELECT UNIX_ TIMESTAMP() 获取主库时间,计算主从延时 - 发起SELECT @@GLOBAL.SERVER_ID 获取主库 server id,比较与从库server_id是否相同 - 发起令 SELEC @@GLOBAL.GTID_MODE,获取主库GTID_MOED设置(是否是匿名事务) - 发起令 SELECT @@GLOBAL. SERVER_ UUTD 获取主库的 serve _uuid.一致则报错 3.注册从库信息 - 调用register_slave函数进行从库注册 - 完毕后show slave status看到从库 4.发送需要读取的GTID SET和POSITION信息给主库 - 给主库的DUMP线程 - GTID SET是Retrieved_ Gtid _ Set和Executed_Gtid Set的并集 - 主库调用com_binlog_dump_gtid函数 5.网络层读取Event 6.写入Event到relay log - 调用queue_event函数 - 监测是否合法 - Cannot replicate GTID-transaction when @@GLOBAL.GTID_MODE = OFF; - Cannot replicate anonymous transaction when AUTO _POSITION = 1; - Cannot replicate anonymous transaction when @@GLOBAL.GTID_MODE = ON 7.持久化信息 - event写入relay log后,持久化这些信息 - 根据sync_relay_log设计,绝对relay_log执行fsync.单位是Event个数(会影响从库性能) - 根据sync_master_info,更新slave_master_info(Event个数) - 事务结束更新Retrieved Gtid _ Set ``` 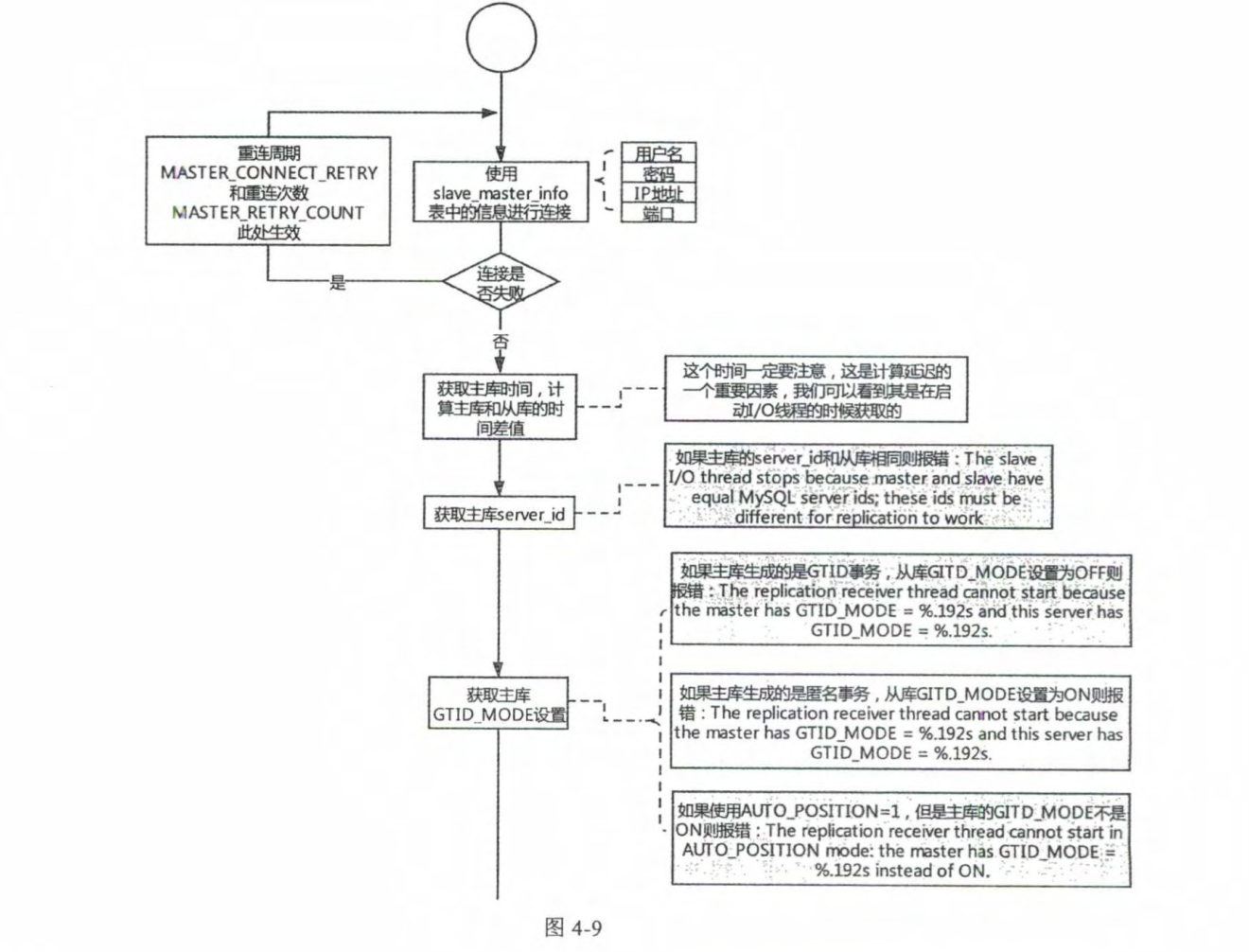 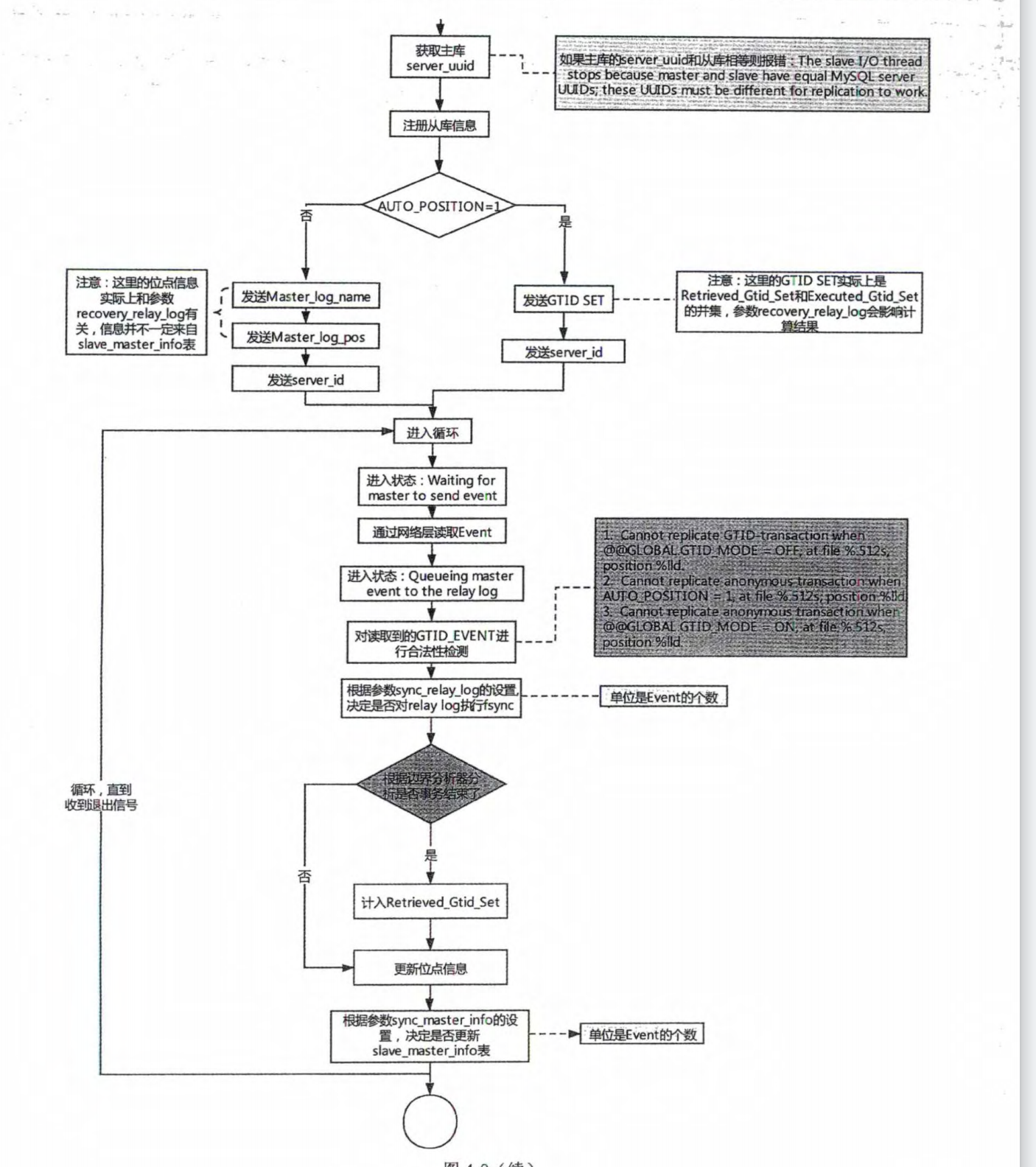 ### 2.2.3.SQL线程 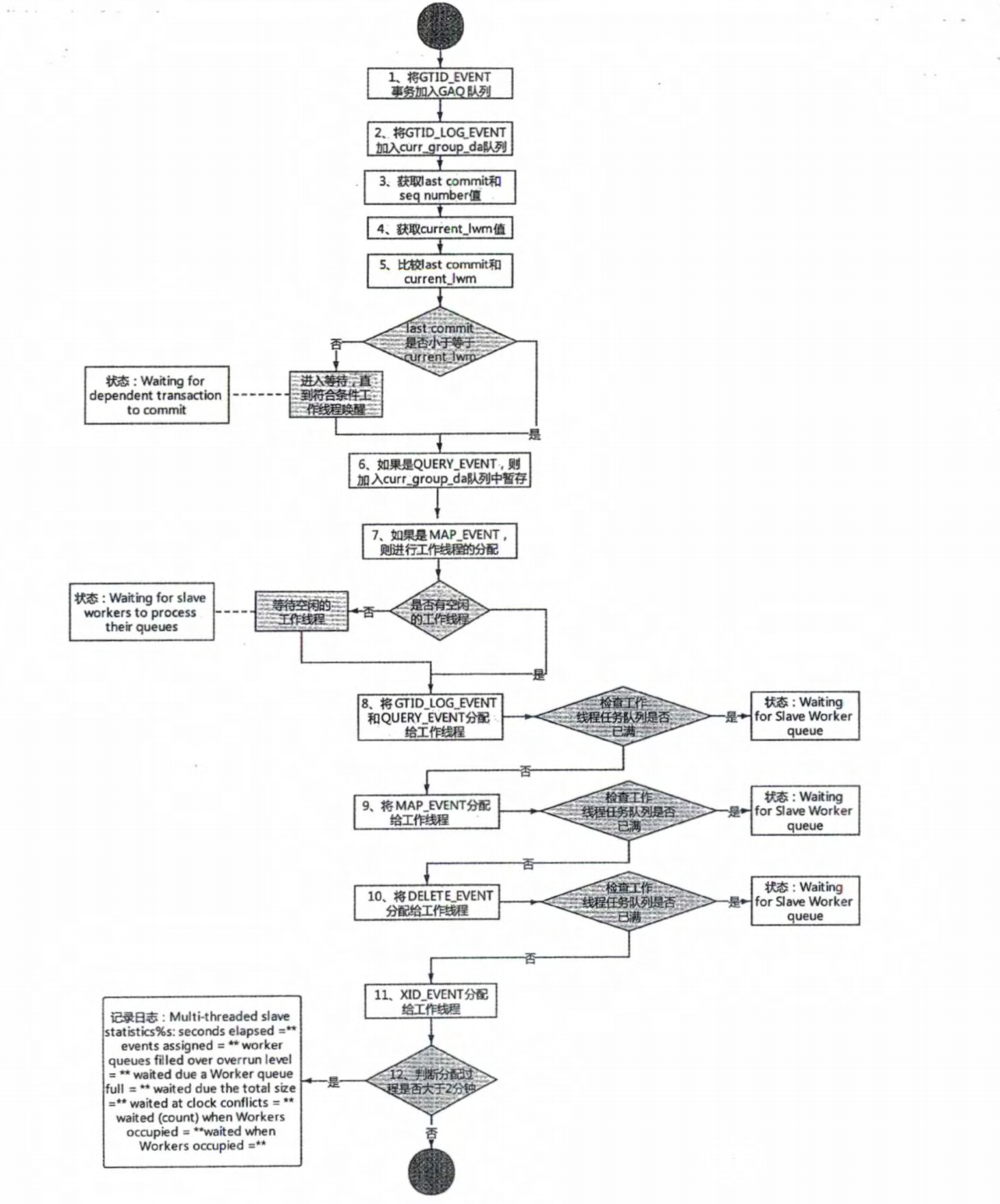 - 功能 ```sql - 读取relay log中的Event - 应用与从库 - MTS模式SQL为协调线程,分发给Event工作 ``` - 流程 ```sql 1.检查是否是MTS 2.检查relay_log_info_repository设置 3.进读取循环 reading event from the relay log 4.判断执行MTS检查点 5.判断清理和切换relay log 6.获取 last_master_timestamp(单线程计算Seconds_Behing_Master) - 多线程MTS在检查点的XID Event计算 与单线程完全不同 7.partial transaction恢复 - I/O线程重连 - 从库异常重启 8.MTS进行Event分发,单SQL线程进行Event应用 ``` - 特别提示-从库数据查找 ```sql 1.主库表中有主键,则从库能显著的降低延时,从库根据Event的行数据进行索引,根据主键查找数据 2.从库索引利用是自行判断,顺序主键--》唯一键--》普通索引 - 如果参数slave_rows_search_algorithms 没有设置 HASH_SCAN或表中无主键或唯一键,从库性能急剧下降,导致主从延时增大,如果索引没有,则主库每改一行数据都是全表扫描 结论:MySQL强制设置主键 ``` 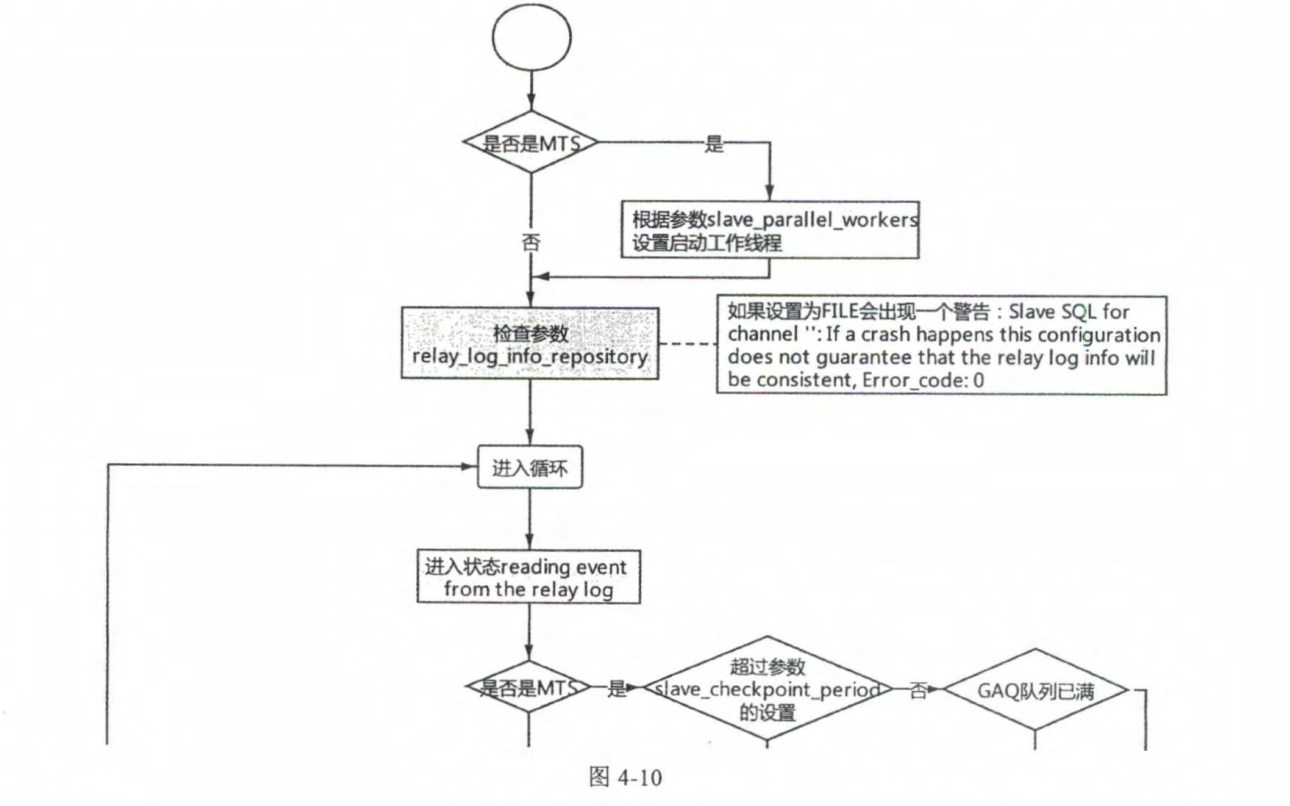 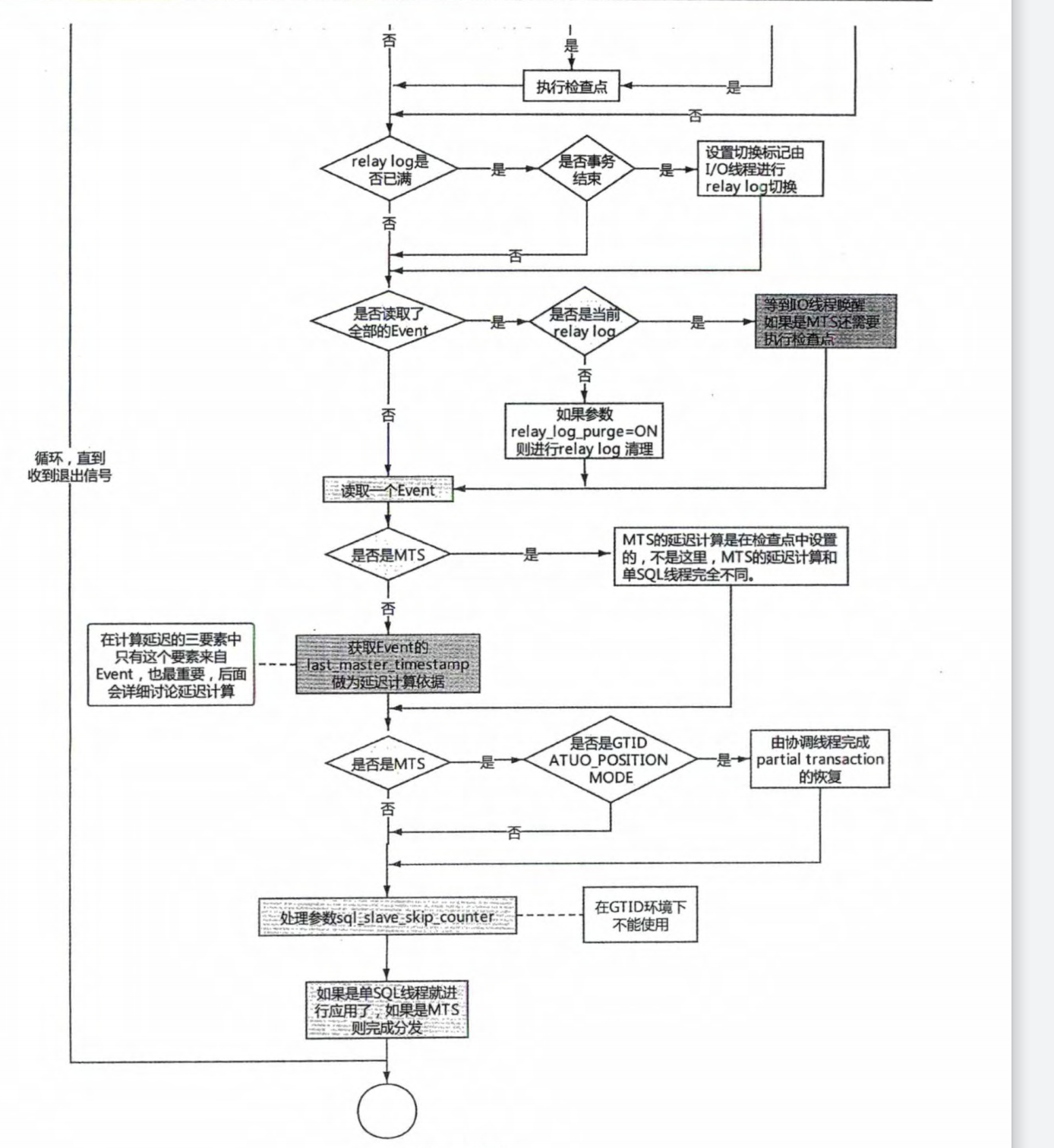 # 3.从库的关闭和异常恢复流程 ## 3.1.关闭流程 - 简介 ```sql stop slave由用户线程发起,作用SQL和IO线程 ``` - 流程 ```sql 1.用户发起stop slave命令 2.全局变量abort slave - 如果有Event没完成,读取-应用一个event然后回滚 - 如果超过rpl_stop_slave_timeout或者强制关闭 3.刷新 salve_relay_log_info和slave_master_info表 4.唤醒用户线程 5.强制刷新relay log ``` 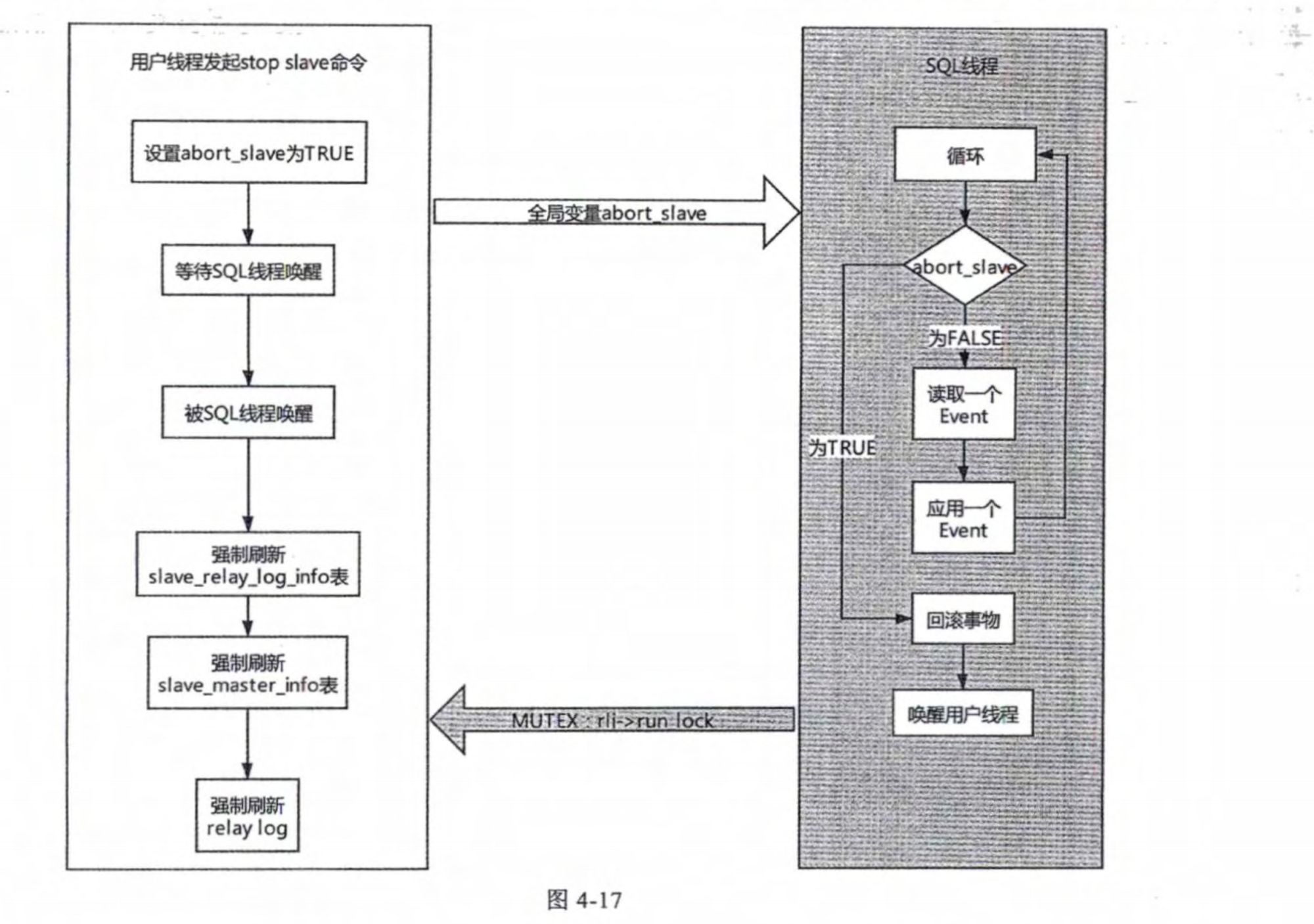 - stop slave变慢原因 ```sql 1.DDL语句包换在QUERY_event中,执行完才能响应stop slave 2.DML语句包含多个DML Event,当一个Event执行完后响应stop slave,然后整个事务回滚 ``` - 从库relay log性能落盘参数 ```sql #每多少个event触发一次sync操作,不能设置1,性能太差 sync_relay_log: 1000-10000 ``` ## 3.2.恢复流程 - 介绍 - 大部分恢复流程集中在init_slave函数,除了以下恢复 - Executed_Gtid_Set在初始化之前 - 流程 ```sql 1.建立内存机构 mi 和 rli 2.读取 slave_master_info表到mi内存结构 3.recover_relay_log是否设置为1 - 1:读取slave_relay_log_info到内存 - 0:扫描relay log,获取Retrieved_Gtid_Set 4.recover_relay_log是否设置为1,且MTS(主要在于是否有点位检查,推荐为1,0从库可能多回放) - 1:或者检查点位--确认需要回复的Event-使用SQL线程读取relay log进行gap恢复-恢复到relog-log-pos的位置 - 0:使用relay_log_name和relay_log_pos设置relay log读取位置 5.启动slave IOh和SQL线程 ``` recovery_relay_log=1作用 ```sql 1.不需要初始化Retrieved_Gtid_Set,避免扫描relay log过程 2.Mysql从库恢复会扫描需要回复的事务,使用GTID重新拉去填充 gap 3.保证恢复正确性 ``` 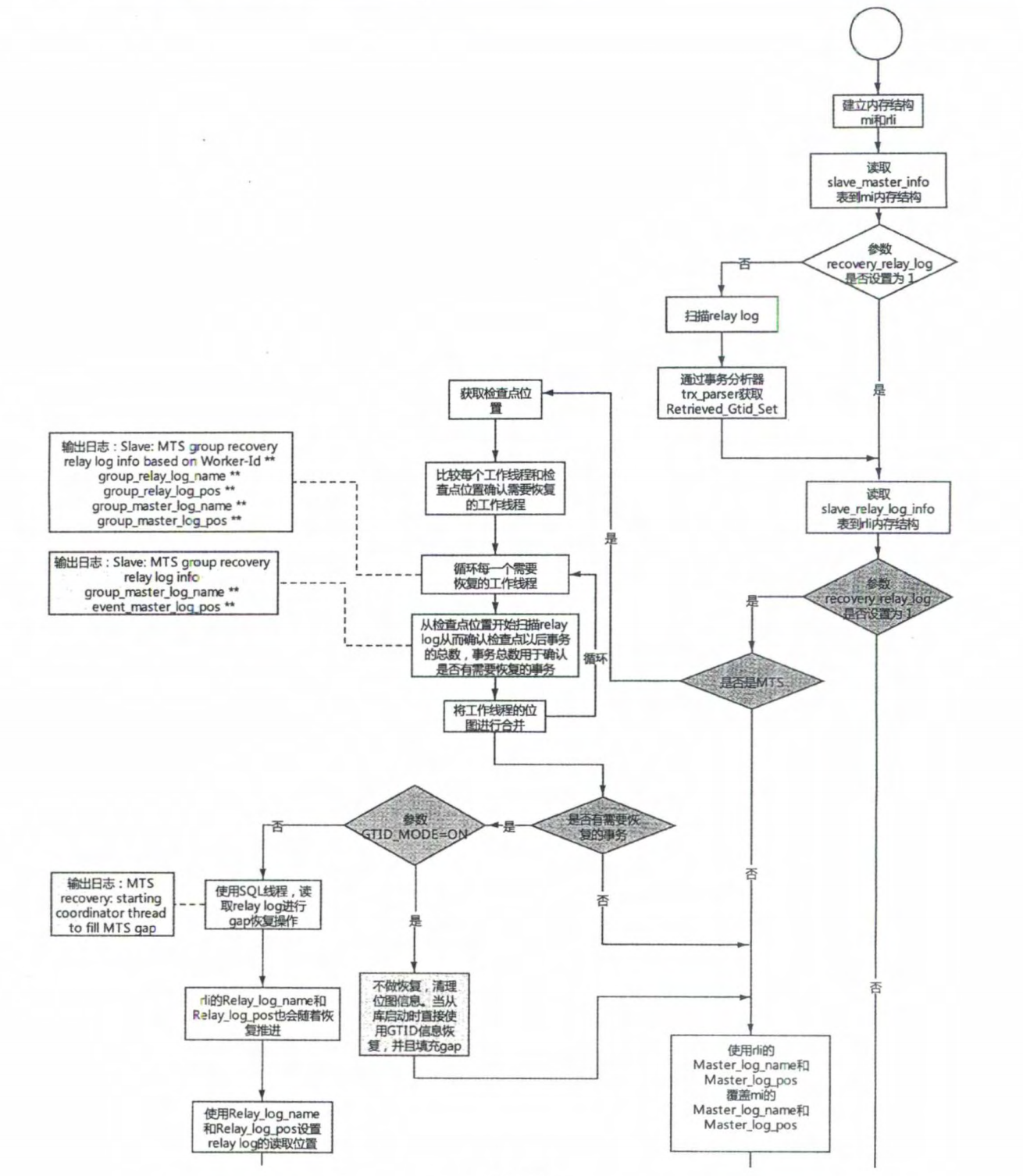 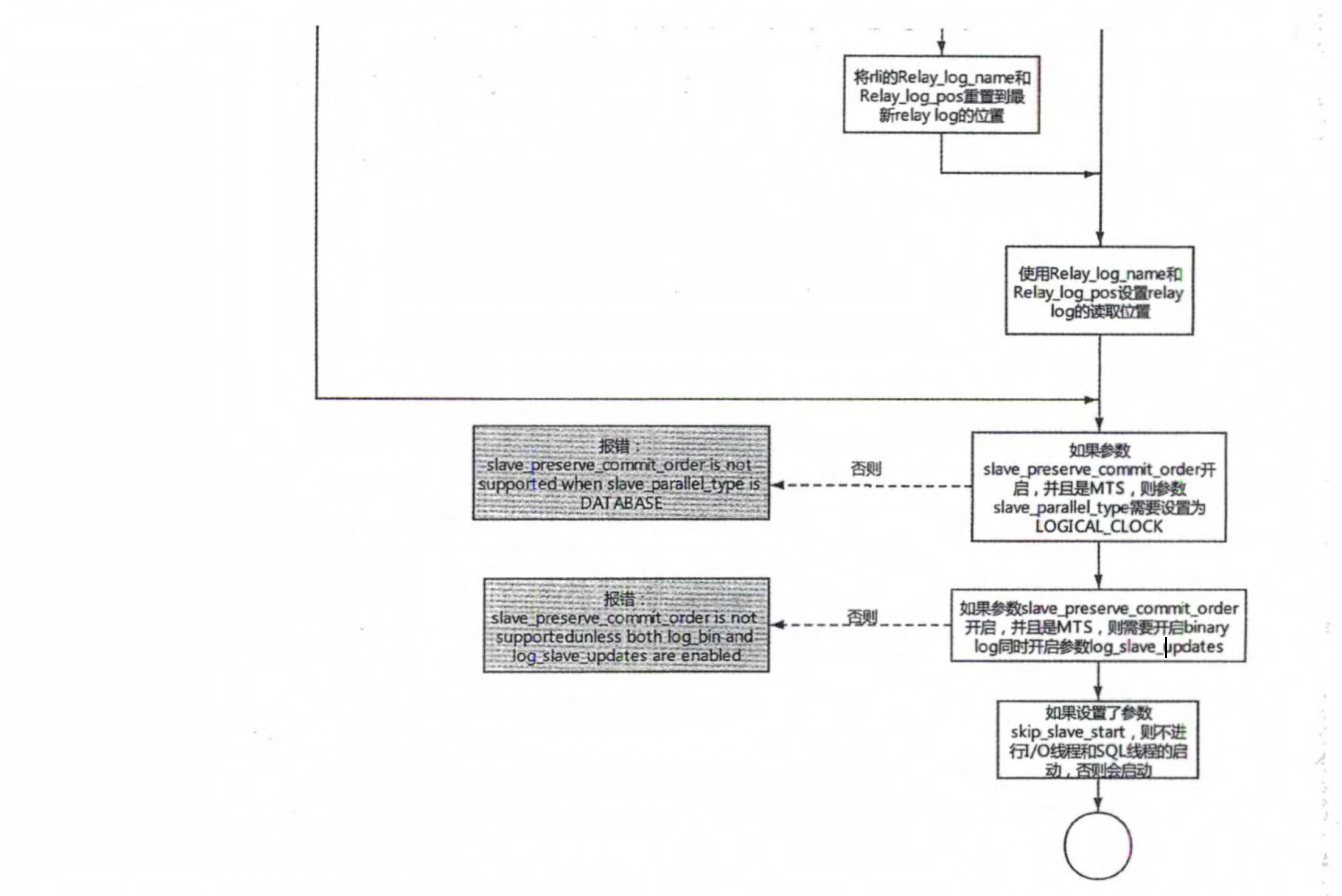 ## 3.3.从库Seconds_Behind_Master计算方式 > 非常重要,判断Mysql主从延时,掌握计算方法同事说明 即使为0也并不一定代表没有延迟 > - 简介 ```sql - 发起 show slave status进行一次Seconds_Behind_Master计算 - 计算方式在 show_slave_status_send_data() 函数中 / * The pseudo code compute Seconds:_Behi,nd_Ma:ster: if (SQL thread is running) //如果 SQL 线程启动了 { if (SQL thread processed all the available relay log //如果SQL线程巳经应用完所有的I/O线程写入的Event; { if (IO thread is running) //如果i/o线程启动了 print 0; //延时为0 else print NULL;//否则延时为NULL } else: //SQL线程没有应用玩I/O线程写入的Event,则计算延时 compute Seconds_Behind_Master } else: print NULL;//SQL线程没启动设置为空值 */ ``` - 判断SQL线程应用完的Event代码 ```sql "mi- get_master_log os() = mi- rli-get_group_master log os()" - 判断I/O线程读取主库的binary log和SQL线程应用到主库的binary log位置比较 - 如果主从网络波动大,SQL线程应用Event速度>I/O线程读取Event速度==》虽然延时为0,但是是因为I/O线程读取Event慢,并不代表没有延时 ``` - Seconds_Behind_Master 计算因素 ```sql 源码如下: long time diff = ((long)(time(0)- mi -> ril->last_master_timestamp) - mi -> clock_diff_with_master); 1.(long)(time(O):从库服务器当前时间 2.mi->clock_diff_with_master - 主从系统时间差值,IO线程启动进行一次性计算(人为修改则出现问题,如果为负数延时为0) 3.mi->rli->last_master_timestamp(重点) (1. DML(单线程):commit事务那一刻的时间(比如主库执行10分钟,则执行完毕从库延时瞬间为10分钟),T2 - T1 = 10min (2. DML(MTS): - ril->last_master_timestamp) 取值为检查点事务的XID_event的timestamp(并行事务group的提交时间) -- DML的QUERY_EVENT一般为begin时间不记录,DDL则是实际语句不能忽略时间,因此DML和DDL计算延时的区别在DDL的exec_time能正确描述语句执行时间(课下实验) 计算公式: 1.DML(单线程)从服务器系统时间-Event的header的timestamp时间-主从时间差 2.DML(MTS) 从服务器系统时间-检查点XID_event HEADER的timestamp时间-主从时间差 3.DDL 从服务器系统时间 - (QUERY_EVENT header的timestamp和本DDL在主库执行时间)-主从时间差 ``` ### 3.3.1.从库Seconds_Behind_Master 延时场景归纳 1.从库高负载 ```sql 因为CPU或者IO负载,执行Event(说明 top -H 一个SQL线程只能占用一个CPU,如果系统整体负载不高,但是cpu单核满了) 1.大事务造成延时:主库执行DML大事务时间开始,主库执行花费20s,则从库从20开始(Query_event没有准备记录执行时间) 2.大表ddl,延时从0开始,Query_event记录准确执行时间 3.表没有合理使用主键或者唯一键(设置参数为 HASH_SCAN) 4.sync_relay_log sync_master_info sync_relay_log_info设置不合理 5.从库开始binary log功能 ``` 2.从库低负载 ```sql 没有堵塞Event和机器负载 1.长时间为commit事务导致延时瞬间增加(GTID_EVENT和XID_EVENT是提交时间) 2.InnoDB层行锁延时,从库修改操作和SQL线程修改数据 3.MDL Lock: SQL线程进行DDL操作,但是从库做了锁表操作 4.MTS不合理设置 slave_checkpoint_period 参数 5.从库手动修改服务器时间或者 6.网络延时 网络波动:延时为0,但是下游没更新实时数据 ``` # [4.](http://4.ss)Mysql主从复制搭建 ## 4.1.搭建一主一从(mysqldump) - 主从复制步骤简介 ```sql 1. 多个mysql实例 - server_id不同 - server_uuid不同 2. 主库开启binlog 3. 搭建从库 - 备份数据(pos点位或gtid) - 逻辑备份mysqldump - XBK(dump-slave参数从库备份告知主库点位) - 空库搭建 4. 从库连接主库(DBA命令 change master) 5. 启动复制线程(start slave) 6. 查看复制状态(show slave status) 7. 监控复制流程(监控+报警) 8. 集群元信息录入平台 ``` - 初始环境准备 ```sql #一主二从,三个服务器节点。 master:172.21.188.37 slave1:172.21.188.36 slave2:172.21.188.38 主库db-01-37: vim /chj/class/data/mysql57/etc/my.cnf [mysql] # CLIENT # no_auto_rehash port= 3306 socket= /chj/class/data/mysql57/tmp/mysql.sock default_character_set= utf8mb4 [mysqld] user= mysql port= 3306 basedir= /chj/class/dowland/mysql-5.7.30-linux-glibc2.12-x86_64 server_id = 1 gtid_mode=ON enforce-gtid-consistency=true datadir=/chj/class/data/mysql57/var/ socket= /chj/class/data/mysql57/tmp/mysql.sock pid_file= /chj/class/data/mysql57/var/mysql.pid tmpdir= /chj/class/data/mysql57/tmp/ log_error= /chj/class/data/mysql57/log/mysql.err general_log= 0 general_log_file= /chj/class/data/mysql57/log/mysql.log log_bin = /chj/class/data/mysql57/var/mysql-bin binlog_format = row #从库(db02): cat > /chj/class/data/mysql57/etc/my.cnf <<EOF [mysql] no_auto_rehash port= 3306 socket= /chj/class/data/mysql57/tmp/mysql.sock default_character_set= utf8mb4 prompt=db02 [mysqld] user= mysql port= 3306 basedir= /chj/class/dowland/mysql-5.7.30-linux-glibc2.12-x86_64 server_id = 101 gtid_mode=ON enforce-gtid-consistency=true datadir=/chj/class/data/mysql57/var/ socket= /chj/class/data/mysql57/tmp/mysql.sock pid_file= /chj/class/data/mysql57/var/mysql.pid tmpdir= /chj/class/data/mysql57/tmp/ log_error= /chj/class/data/mysql57/log/mysql.err general_log= 0 general_log_file= /chj/class/data/mysql57/log/mysql.log log_bin = /chj/class/data/mysql57/var/mysql-bin binlog_format = row EOF #从库(db03) 不加gtid做实验 vim /chj/class/data/mysql57/etc/my.cnf [mysql] no_auto_rehash port= 3306 socket= /chj/class/data/mysql57/tmp/mysql.sock default_character_set= utf8mb4 prompt=db03> [mysqld] user= mysql port= 3306 basedir= /chj/class/downland/mysql5730/ server_id = 102 datadir=/chj/class/data/mysql57/var/ socket= /chj/class/data/mysql57/tmp/mysql.sock pid_file= /chj/class/data/mysql57/var/mysql.pid tmpdir= /chj/class/data/mysql57/tmp/ log_error= /chj/class/data/mysql57/log/mysql.err general_log= 0 general_log_file= /chj/class/data/mysql57/log/mysql.log log_bin = /chj/class/data/mysql57/var/mysql-bin binlog_format = row #初始化从库 mysqld --initialize-insecure --user=mysql --basedir=/chj/app/mysql-5.7.30-linux-glibc2.12-x86_64/ --datadir=/chj/class/data/mysql57/var/ #启动从库 mysqld_safe --defaults-file=/chj/class/data/mysql57/etc/my.cnf --user=mysql & #登入 mysql -uroot -p -h127.0.0.1 -P3306 #查看设置 server_id和binlog mysql>select @@server_id; select @@server_uuid;show variables like 'log_bin%'; #创建复制账户-主库 mysql > create user repl@'172.%' identified with mysql_native_password by '123';grant replication slave on *.* to repl@'172.%'; #创建从库root账户-从库 mysql > create user root@'172.%' identified with mysql_native_password by '123';grant all on *.* to root@'172.%'; ``` 主从复制重要参数 ```sql server_id:每个实例不能一直 gtid_mode: on enforce_gtid_consistency: on log-bin:主库必须开启 log-slave-updates1:从库建议开启(用来备份) binlog_format= ROW skip-slave-start=1 ``` ## 4.2.常用构建主从 ### 4.2.1.mysqldump备份主库数据-pos传统 ```sql #备份db01主库数据,在02节点执行 shell> mysqldump -uqianlong -p123456 -h172.21.188.37 -P 3306 -A --master-data=2 --single-transaction -R -E --triggers >/tmp/full.sql #db02-从库 [mysql]>source /tmp/full.sql #筛选pos shell > grep "\--\ CHANGE MASTER" /tmp/full.sql CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=317; #构建主从命令 CHANGE MASTER TO MASTER_HOST='172.21.188.37', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=317, MASTER_CONNECT_RETRY=10; #开启主从 mysql >start slave; mysql >show slave status\G #关闭主从 mysql >stop slave; mysql >reset slave all; #跳过事务,N代表N个event, n=1 跳过下一个事务 n>1,从当前位置跳过N个event,如果跳到一个事务中,则跳过该事务进行复制. set global sql_slave_skip_counter=N ``` ### 4.2.2.mysqldump备份主库数据-GTID构建 ```sql 与pos复制的不同 (0)在主从复制环境中,主库发生过的事务,在全局都是由唯一GTID记录的,更方便Failover (1)change master to 的时候不再需要binlog 文件名和position号,MASTER_AUTO_POSITION=1; (2)在复制过程中,从库不再依赖master.info文件,而是直接读取最后一个relaylog的 GTID号 (3) mysqldump备份时,默认会将备份中包含的事务操作,以以下方式 SET @@GLOBAL.GTID_PURGED='8c49d7ec-7e78-11e8-9638-000c29ca725d:1'; 告诉从库,备份中已经有以上事务,直接从下一个GTID开始请求binlog就行。 #从库执行已经执行的GTID点位 reset master ; SET @@GLOBAL.GTID_PURGED='196c4617-3fa0-11ec-9cce-fa202013137b:1-1181, ddd2aab7-24ae-11ec-8406-fa202013137b:1-72978, e7e868e0-3faf-11ec-b6e6-fa202013137b:1-3'; #构建主从 change master to ew master_host='172.21.188.37', MASTER_PORT=3306, master_user='repl', master_password='123' , MASTER_AUTO_POSITION=1; start slave; ##GTID跳过主键冲突等错误(少数错误) 1.stop slave 2.设置事务号从Executed_Gtid_Set事务号获取 SET @@SESSION.GTID_NEXT= '8f9e146f-0a18-11e7-810a-0050568833c8:4'; 3.执行空事物 BEGIN; COMMIT; 4.恢复自动事务SET SESSION GTID_NEXT = AUTOMATIC; 5.START SLAVE; ##重置master方法跳过错误 STOP SLAVE; RESET MASTER; SET @@GLOBAL.GTID_PURGED ='8f9e146f-0a18-11e7-810a-0050568833c8:1-4'; START SLAVE; ##使用pt-slave-restart工具,忽略特定错误,(冲突较多时可以使用,建议保留relaylog核对事务) 作业:用pt-slave-restart 来忽略一个从库多余主键错误 ``` - 批量生产跳过GTID脚本 ```sql import os script_file = "./skip_file.sql" def write_script(script_content): file_handle = open(script_file, 'a+') file_handle.writelines(script_content + "\n") file_handle.close() def delete_script_file(): if os.path.exists(script_file): os.remove(script_file) def get_skip_script_list(master_uuid, start_tran_id, end_tran_id): script_list = [] current_tran_id = start_tran_id while current_tran_id <= end_tran_id: current_script = """ SET @@SESSION.GTID_NEXT= '{master_uuid}:{tran_id}'; BEGIN; COMMIT; """.format( master_uuid=master_uuid, tran_id=current_tran_id ) current_tran_id = current_tran_id + 1 script_list.append(current_script) script_list.append("SET SESSION GTID_NEXT = AUTOMATIC;") return script_list def main(): master_uuid = "e0a86c29-f20d-11e8-93c2-04b0e7954a65" start_tran_id = 104935 end_tran_id = 105007 script_list = get_skip_script_list(master_uuid, start_tran_id, end_tran_id) write_script("\n".join(script_list)) if __name__ == '__main__': main() ``` ### 4.2.3.XBK备份主库数据-GTID构建 ```sql 1.备份全量数据(可以选择压缩模式qpress后解压缩) innobackupex --defaults-file=/chj/class/data/mysql57/etc/my.cnf --host=172.21.188.37 --port=3306 --user=qianlong --password=123456 --no-timestamp --parallel=8 --use-memory=2G /chj/class/backup/backup_3306 #先用手动方式 tar zcvf /chj/class/backup/backup_3306.tar.gz /chj/class/backup/backup_3306 2.传输到新节点 rsync等方式即可 tar xf backup_3306.tar.gz 3.恢复数据 innobackupex --apply-log ./backup_3306 innobackupex --defaults-file=/chj/class/data/mysql57/etc/my.cnf --copy-back /chj/class/backup/backup_3306/ chown -R mysql:mysql /chj/class/data 4.构建主从 mysqld --defaults-file=/chj/class/data/mysql57/etc/my.cnf --user=mysql --prompt="\\u@\\h : \\d\\r:\\m:\\s>" & #获取点位 cat /chj/class/downland/chj/class/backup/backup_3306/xtrabackup_info |grep binlog_pos binlog_pos = filename 'mysql-bin.000002', position '770' #构建主从 reset master; SET @@GLOBAL.GTID_PURGED =" 196c4617-3fa0-11ec-9cce-fa202013137b:1-1181, ddd2aab7-24ae-11ec-8406-fa202013137b:1-72978, e7e868e0-3faf-11ec-b6e6-fa202013137b:1-3" change master to master_host='172.21.188.36', MASTER_PORT=3306, master_user='repl', master_password='123' , MASTER_AUTO_POSITION=1; start slave; show slave status\G ``` ### 4.2.3.传统复制和GTID转换(线下实验) 1.如果停服,则直接修改my.cnf服务后启动实例即可 2.如果在线维护(推荐5.7之后使用) ```sql #前言 不能直接修改复制方式,会报错 ERROR 1777 (HY000): CHANGE MASTER TO MASTER_AUTO_POSITION = cannot be executed because @@GLOBAL.GTID_MODE = OFF. #看下GTID参数如果都为OFF则需要在线开启 select @@enforce_gtid_consistency; #OFF select @@gtid_mode;" #OFF #直接更改gtid_mode会报错,提示OFF <-> OFF_PERMISSIVE <-> ON_PERMISSIVE <-> ON mysql-- ::>>set global gtid_mode='on'; ERROR (HY000): The value of @@GLOBAL.GTID_MODE can only be changed one step at a time: OFF <-> OFF_PERMISSIVE <-> ON_PERMISSIVE <-> ON. Also note that this value must be stepped up or down simultaneously on all servers. See the Manual for instructions. #正确开启步骤 分两部分 开启enforce_gtid_consistency 和 gtid_mode ##gtid_mode gtid_mode过程: OFF <-> OFF_PERMISSIVE <-> ON_PERMISSIVE <-> ON 两个邻近状态可以互相转换,否则会出错。 四个状态含义: - MySQL 5.7.6及更高版本中记录的事务可以是匿名的, - 匿名事务:可用GTID,依赖二进制日志文件和位置标定 - GTID事务:具有唯一标识符 - OFF:新事务和复制事务都必须是匿名的 - OFF_PERMISSIVE:新事务是匿名的。复制的事务可以是匿名或GTID事务 - ON_PERMISSIVE: 新事务是GTID。复制的事务可以是匿名或GTID事务。 - ON: 新事务和复制事务都必须是GTID事务 ##enforce_gtid_consistency 1.可以配置的值 - OFF:允许违反GTID一致性 - ON:不允许违法GTID一致性 - WARN: 允许所有事务违反GTID一致性,但在这种情况下会生成警告 (5.7.6以上版本) #开启正确步骤 1.需要开启的服务器上,所有事物都允许违反GTID的一致性,找出不符合GTID一致性事务并修复 set global enforce_gtid_consistency=warn; 2.在服务器上设置,这一步操作需要在处理完上面一步操作的基础上执行,从而确保所有的事务都不能违反GTID的一致性。 set global enforce_gtid_consistency=on; 新的事务是匿名的,同时允许复制的事务为GTID或者匿名事务 set global gtid_mode=off_permissive 4.新的事务使用gtid,同时允许复制的事务为GTID或者匿名事务 set global gtid_mode=on_permissive 5.等待 ongoing_anonymous_transaction_count = 0,表示的是已经标记为匿名的正在进行的事务数量,如果状态值为0,说明当前没有事务在等待被处理。没等为0开始操作会报错 show status like '%ongoing_anonymous_transaction_count%' 6.开启gitid,修改my.cnf配置参数 set global gtid_mode=on 7.stop slave 搭建GTID主从 8.在/etc/my.cnf添加参数 ``` ### 4.2.4.GTID复制限制 - GTID复制依赖与事务,有些特性Mysql不支持 ```sql 1.事务中混合多个引擎,产生多个GTID 2.主从表数据引擎不一致,数据不一致 3.基于GTID复制不支持CREATE TABLE...SELECT 4.不支持创建和删除临时表,autocommit=1可以创建临时表,但是不产生GTID信息,不会同步到SLAVE上,删除临时表报错 5.不推荐进行mysql_upgrade ``` # [5.](http://5.ss)MySQL-异步,半同步,增强半同步复制 > 核心目的是为了在宕机发生主从切换后,业务数据保持一致性 > ## 5.1.异步复制 ```sql Mysql5.5之前: 如果主库和从库的数据有一定的延迟 - 主库写入一个事务并提交成功,不知道slave是否已经收到或者处理binlog,主库宕机 - 高可用从库-->主库,由于从库没有这个binlog,损失这个事务,从而造成主从不一致。 - 速度最快,性能最高,宕机如果主从有延时,有丢失数据风险 ``` - 异步复制时间轴 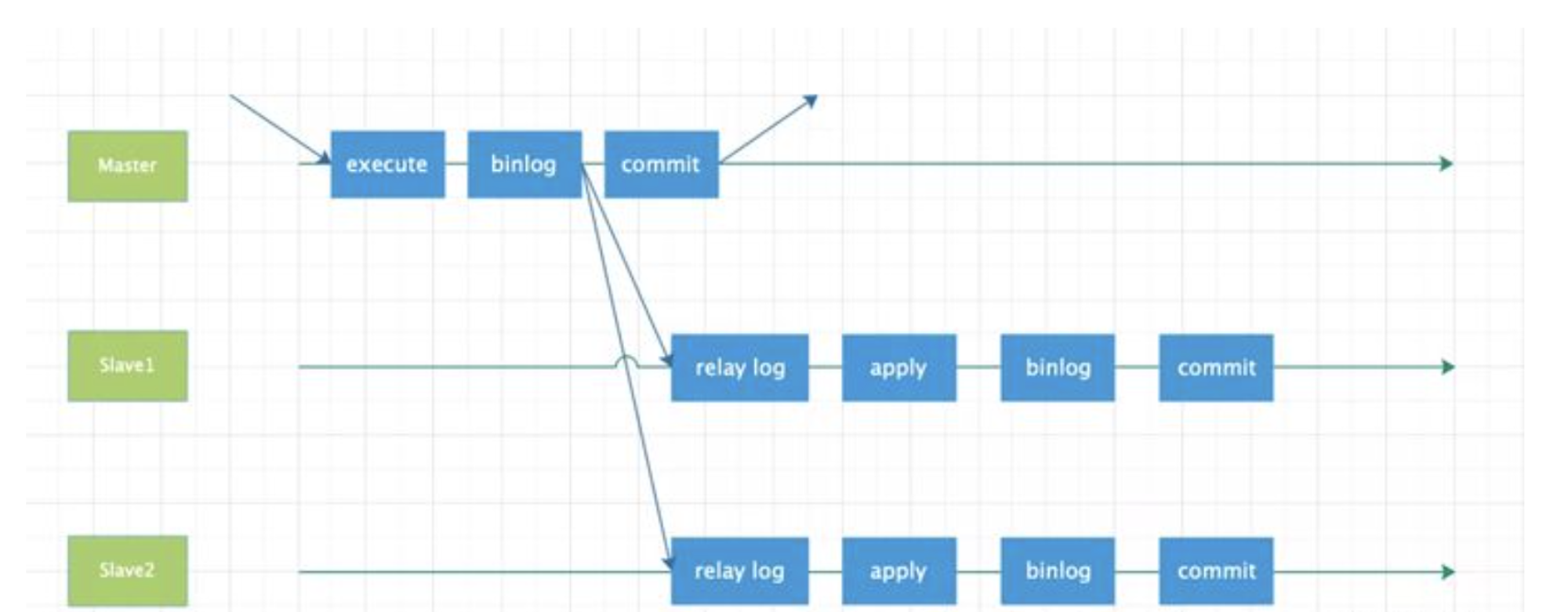 ## 5.2.半同步复制 ### 5.2.1.传统半同步复制 - 简介 ```sql 改进: 1.主库写入binlog 2.提交事务后并commit 3.等待至少一个从节点确认收到所有Event并写入relay log刷盘 4.返回ACK给主库 #条件 1.当至少有一个从库赶上时,主库会恢复到半同步复制。(默认10s) 2.ACK超时则变为异步复制(rpl_semi_sync_master_timeout),追上恢复半同步 mysql> show variables like '%rpl_semi_sync_master_timeout%'; 问题: - 主库已经提交给事物引擎层,仅等待ACK返回,此时宕机,从库还未写入Relay log,主从不一致 ``` 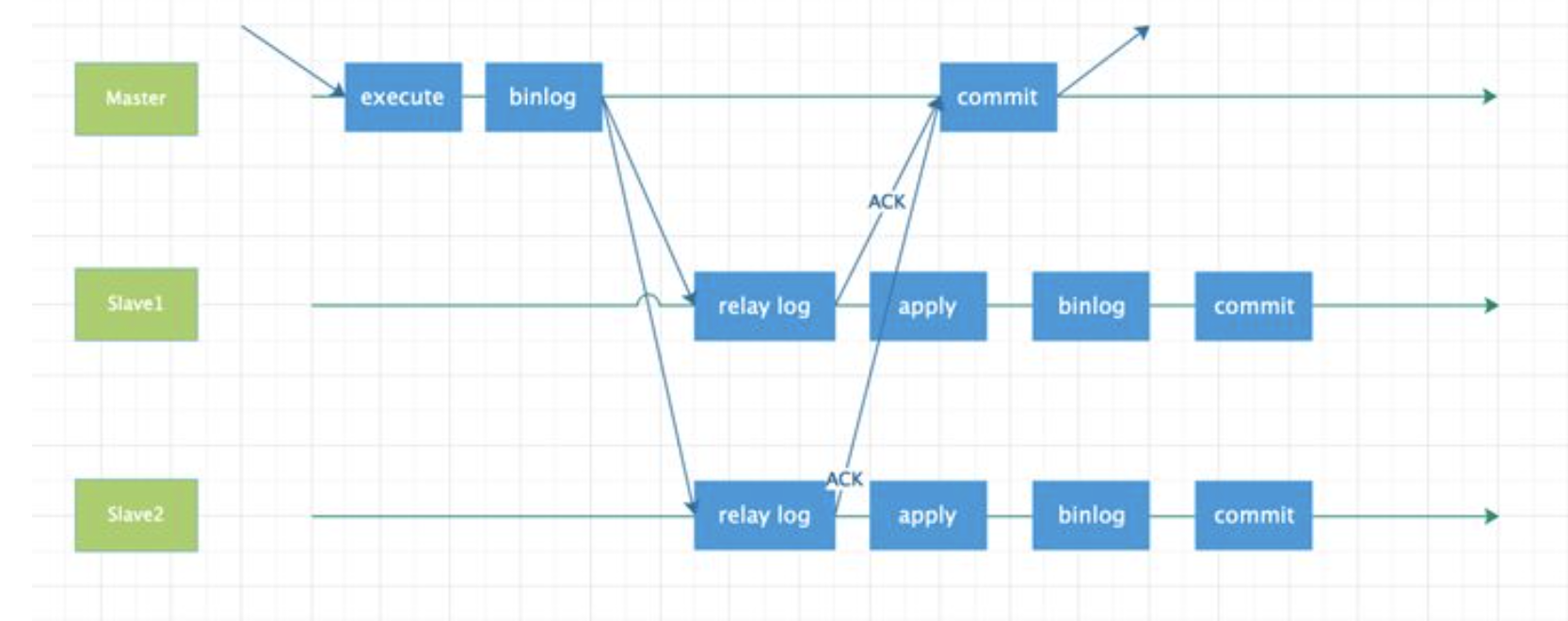 ### 5.2.2.增强半同步复制(Loss-Less无损复制) ```sql 改进:在ACK等待时间做了调整 1.主库写入binlog 2.等待从库的ACK返回 3.从库至少一个写入relay log并落盘 4.返回主库消息 5.通知主库commit 6.客户端收到变化 总结: 1.两个半同步:保证了事务提交成功后,至少两份日志,master binlog和slave的relay log 2.半同步复制很大程度上取决于主从库之间的网络情况,往返时延RTT越小决定了从库的实时性越好。通俗地说,主从库之间的网络越快,从库约实时。 3.全同步复制,所有从库执行事务返回,影响性能,不用 4.版本改进 5.6版本 - dump thread:传送binlog给slave.等待slave ack,成为性能瓶颈,高并发业务,影响数据库TPS 5.7.版本 - 半同步复制 独立出一个ack collector thread ,专门用于接收slave 的反馈信息。 #知识点 往返时延RTT(Round-Trip Time)在计算机网络中是一个重要的性能指标,它表示从发送端发送数据开始到发送端接收到接收端的确认,总共经历的时长(TCP三次握手的前两次握手)。 ``` - 使用 ```sql #使用条件 1.安装插件,主库和从库都要启用半同步复制才会进行半同步复制功能 主: mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; 从: mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; 2.查看是否加载成功 show plugins; SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE '%semi%'; 3.启动半同步复制 主: mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1; 从: mysql> SET GLOBAL rpl_semi_sync_slave_enabled = 1; 4.重启IO线程 mysql> STOP SLAVE IO_THREAD; mysql> START SLAVE IO_THREAD; #重启后,slave会在master上注册为半同步复制的slave角色。 主的error.log记录 2021-12-05T05:05:21.433124Z 21 [Note] Stop asynchronous binlog_dump to slave (server_id: 101) 2021-12-05T05:05:21.433178Z 23 [Note] Start binlog_dump to master_thread_id(23) slave_server(101), pos(, 4) 2021-12-05T05:05:21.433222Z 23 [Note] Start semi-sync binlog_dump to slave (server_id: 101), pos(, 4) ``` - 总要参数 ```sql SHOW GLOBAL STATUS LIKE '%semi%'; Rpl_semi_sync_master_clients # 半同步复制客户端的个数 Rpl_semi_sync_master_net_avg_wait_time #平均等待时间(默认毫秒) ACK Rpl_semi_sync_master_net_wait_time #总共等待时间 Rpl_semi_sync_master_net_waits #等待次数 Rpl_semi_sync_master_no_times #关闭半同步复制的次数 Rpl_semi_sync_master_no_tx #表示没有成功接收slave提交的次数 Rpl_semi_sync_master_status #表示当前是异步模式还是半同步模式,on为半同步 Rpl_semi_sync_master_timefunc_failures #调用时间函数失败的次数 Rpl_semi_sync_master_tx_avg_wait_time #事物的平均传输时间 Rpl_semi_sync_master_tx_wait_time #事物的总共传输时间 Rpl_semi_sync_master_tx_waits #事物等待次数 Rpl_semi_sync_master_wait_pos_backtraverse # 网上有人理解为"后来的先到了,而先来的还没有到的次数" Rpl_semi_sync_master_wait_sessions #当前有多少个session因为slave的回复而造成等待 Rpl_semi_sync_master_yes_tx #成功接受到slave事物回复的次数 ```
李延召
2024年4月17日 13:13
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码