DBA专题
DBA授课
DBA公开课
DBA训练营三天
01.Mysql基础入门-数据库简介
02.Mysql基础入门-部署与管理体系
03.MySQL主流版本版本特性与部署安装
04.Mysql-基础入门-用户与权限
05 MySQL-SQL基础2
06 SQL高级开发-函数
07 MySQL-SQL高级处理
08 SQL练习 作业
09 数据库高级开发2
10 Mysql基础入门-索引
11 Mysql之InnoDB引擎架构与体系结构
12 Mysql之InnoDB存储引擎
13 Mysql之日志管理
14 Mysql备份,恢复与迁移
15 主从复制的作用及重要性
16 Mysql Binlog Event详解
17 Mysql 主从复制
18 MySQL主从复制延时优化及监控故障处理
19 MySQL主从复制企业级场景解析
20 MySql主从复制搭建
21 MySQL高可用-技术方案选型
22 MySQL高可用-MHA(原理篇)
23 MySQL MHA实验
24 MySQL MGR
25 部署MySQL InnoDB Cluster
26 MySQL Cluster(MGR)
27 MySQL ProxySQL中间件
相信可能就有无限可能
-
+
首页
26 MySQL Cluster(MGR)
# 1.MySQL InnoDB Cluster ```bash #简介 - MySQL InnoDB集群提供了一个集成的,本地的,HA解决方案。 - 利用分布式paxos协议,保障数据一致性,组复制支持单主模式和多主模式。 - MySQL InnoDB Clucster由3部分组成: - MySQL Servers with Group Replication(MGR):集群内mysql节点复制数据+容错+自动故障转移+弹性伸缩+流控。MySQL Server 5.7.17以上版本 - MySQL Router:内置读写分离,负载均衡。自动根据Mysql InnoDB Cluster中的metadata自动调整。 - MySQL Shell:实现快速部署,主要提供了一套AdminAPI,可以自动化配置Group Replication。MySQL Shell 1.0.9或更高的版本。 - 最终功能:故障转移、故障恢复、读写分离、负载均衡,高可用 ``` - 现阶段架构 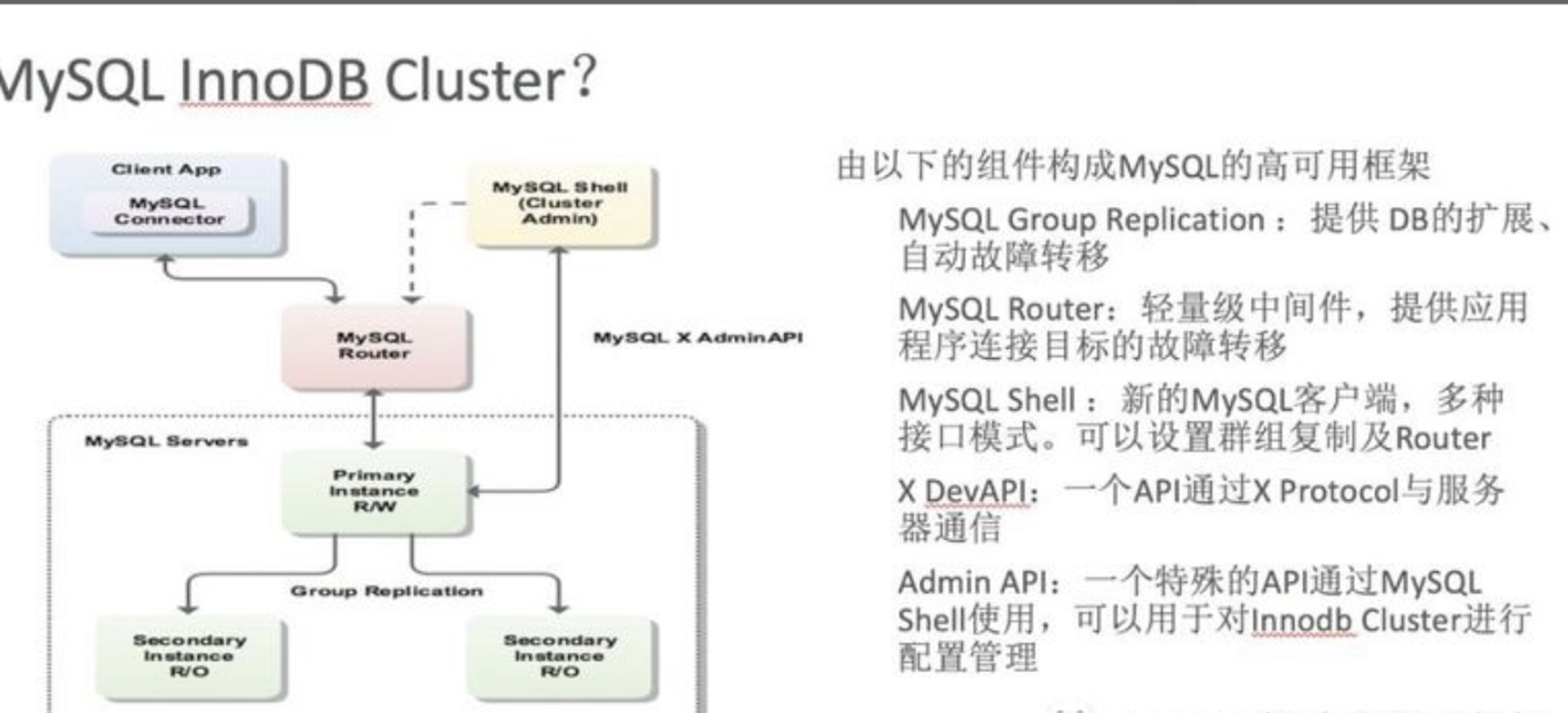 - 官方未来目标-自动scale-in or out 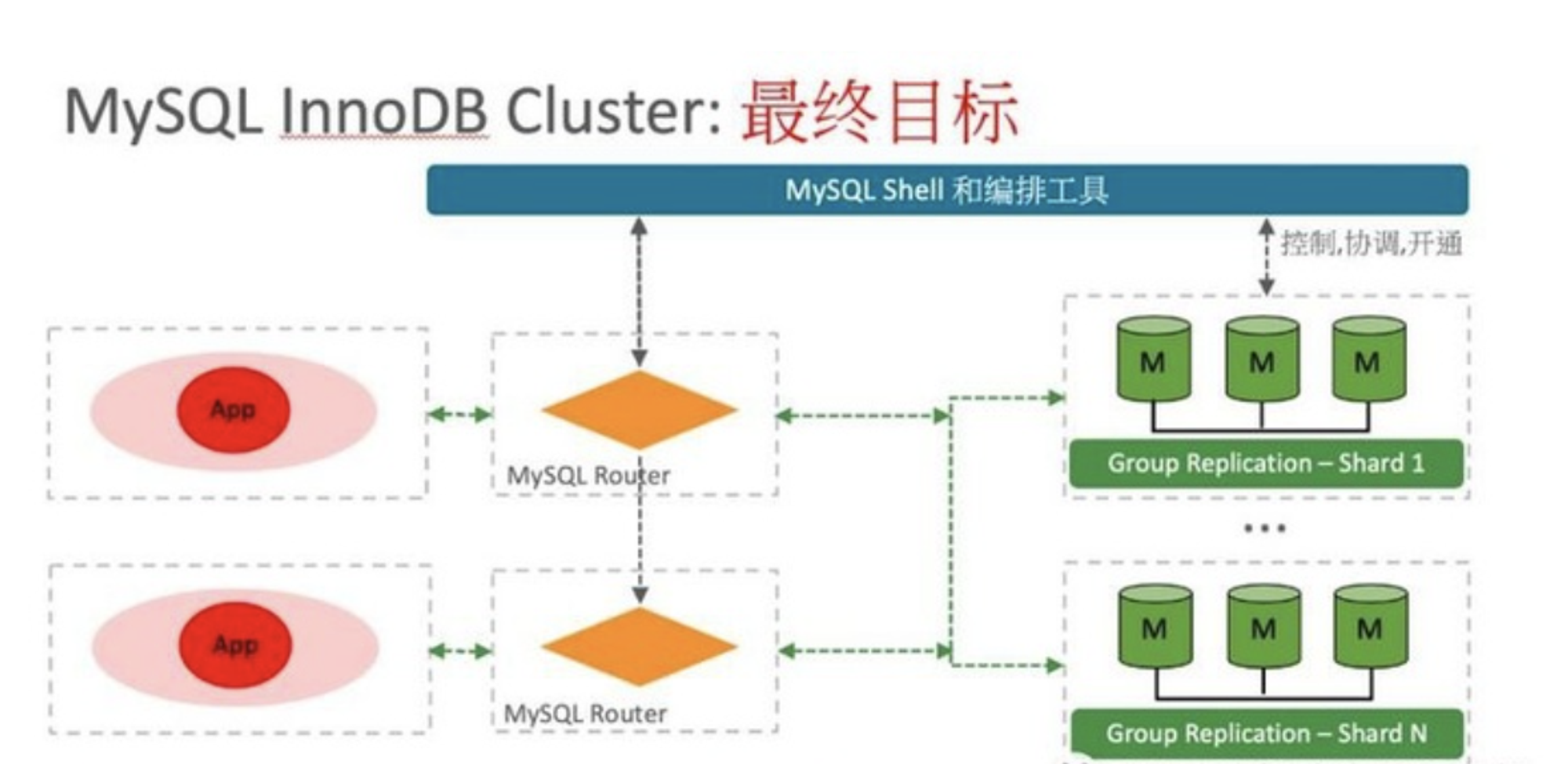 # 2.MGR基础使用 ## 1.1.介绍 ```bash #简介 - 一组Mysql实例构成,每个实例有完整数据,组件通过GCS通信引擎保证消息原子性和节点通信 - 基于Paxos协议和原生复制,多数节点统一事务可提交 #功能 - 自动故障转移 - 分布式容错能力+弹性扩展 - 自动重配置(加入/移除节点,崩溃等等) - 自动侦测和处理冲突 - 支持多主架构(目前MGR单主模式比较稳健不推荐多主) #类比 - PXC对比 - GCS(Group communication System) - 事务消息环绕所有节点确认 VS MGR多数派 性能更好 - Binlogs & Gcache: - PXC Gcache:不是很透明 - mgr写入binlog - Node Provisioning - PXC: 利用XBK等方式 - MGR: 可节点增加用mysql clone - Partition(网络分区) - PXC: 集群完全不可用,不可读不可写 - MGR: 分区少数派可select,write hang住 - Flow Control(流量控制) - PXC:所有节点不可写 - MGR:写入变慢,所有节点可读写 - DDL - PXC: DDL串行 - MGR: 支持并发DDL ``` - 架构 - M:mysql nodes in group replication - R: DAL(MySQL Router等) 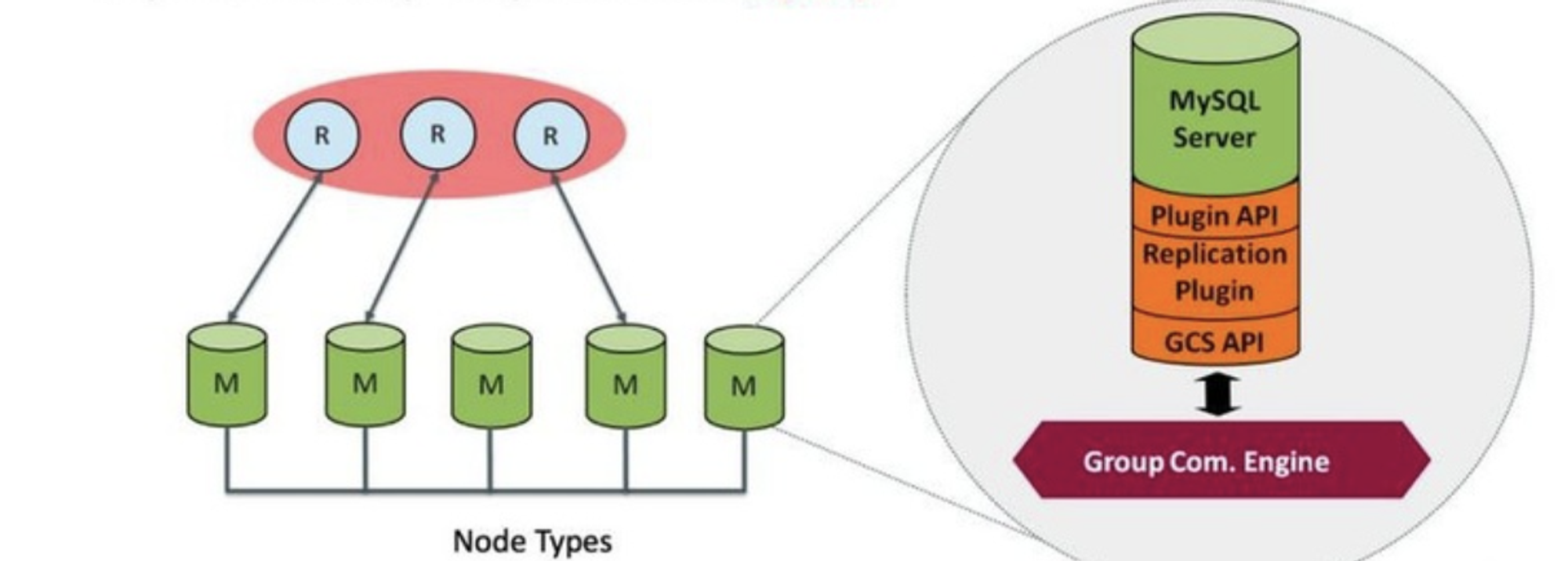 - 详细架构 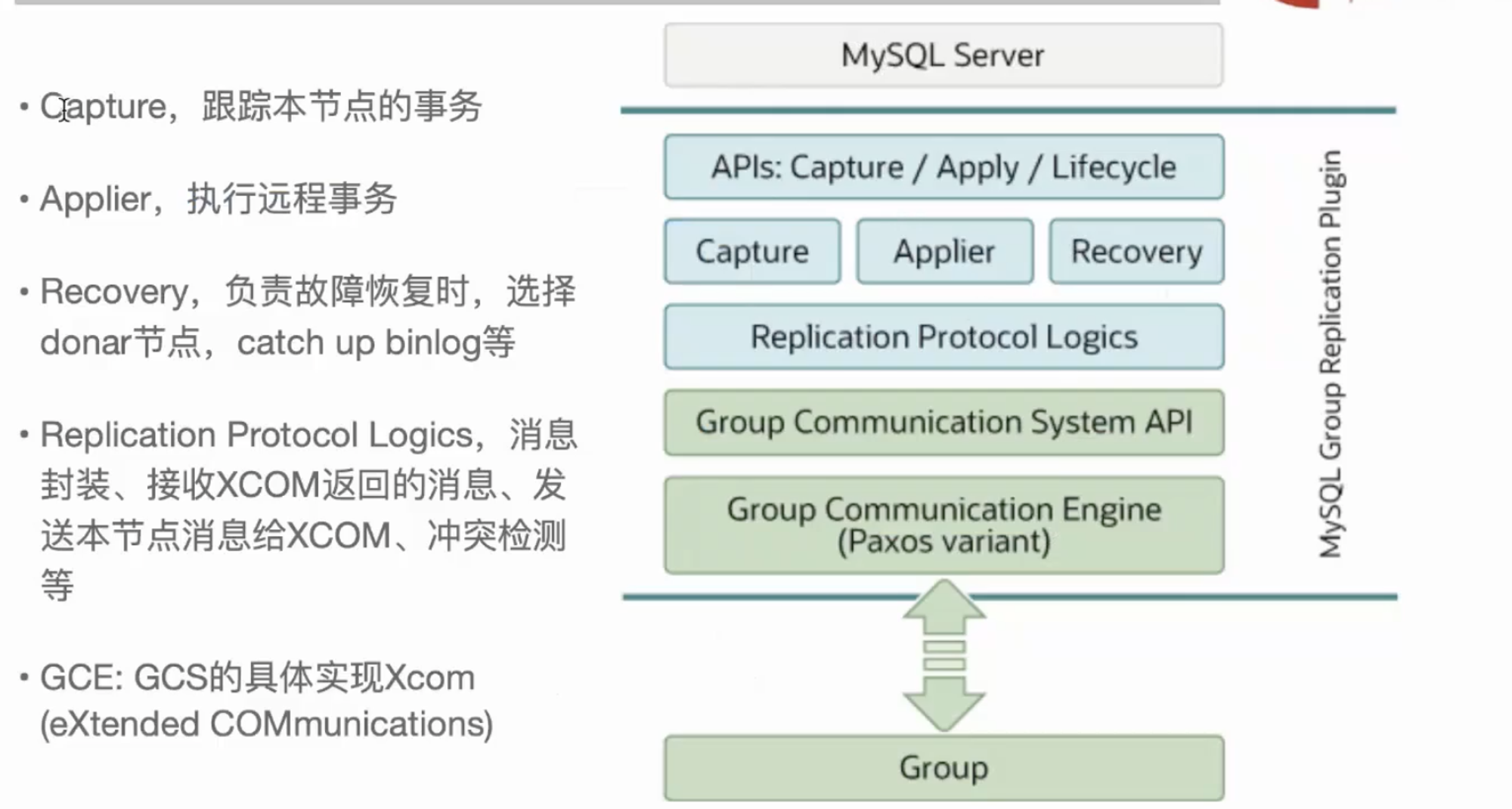 - MGR两种模式-单主 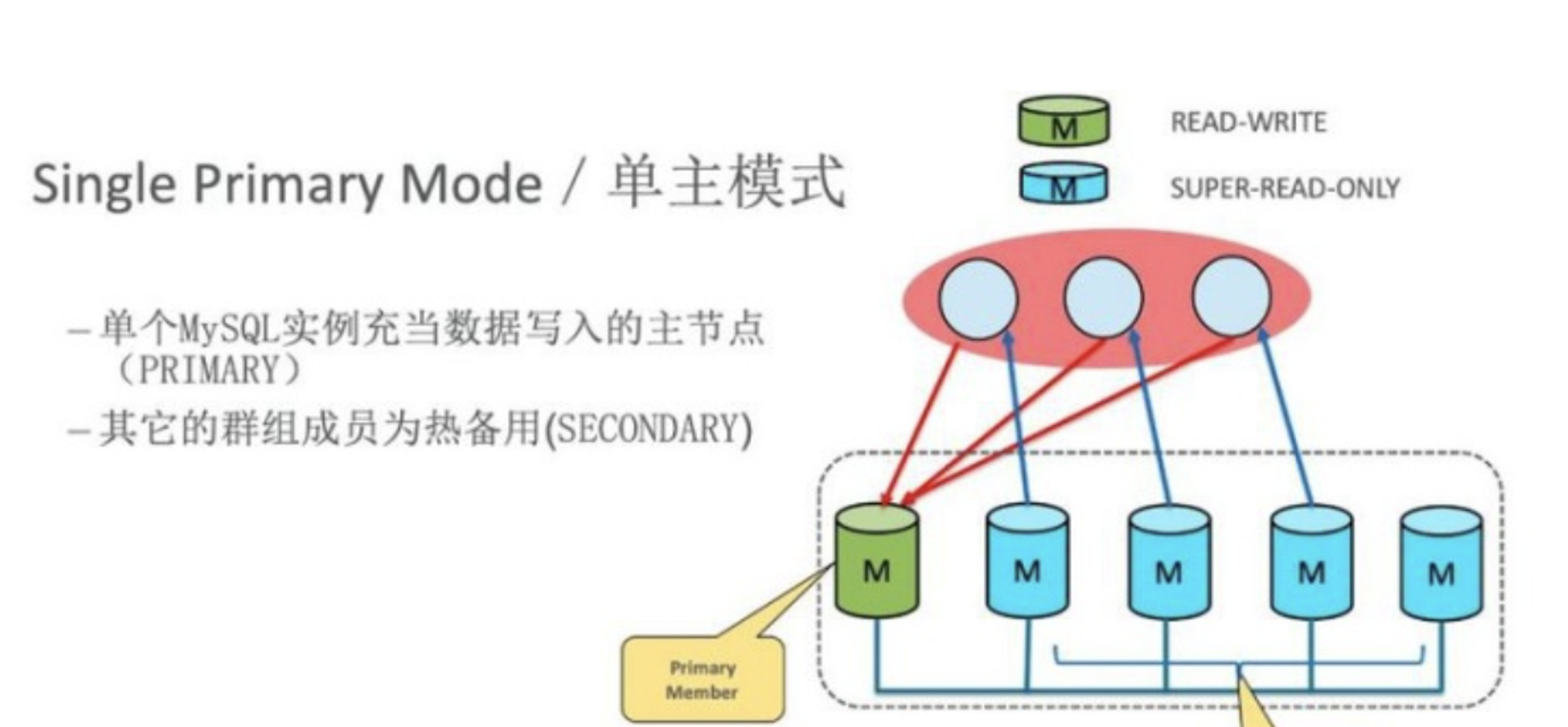 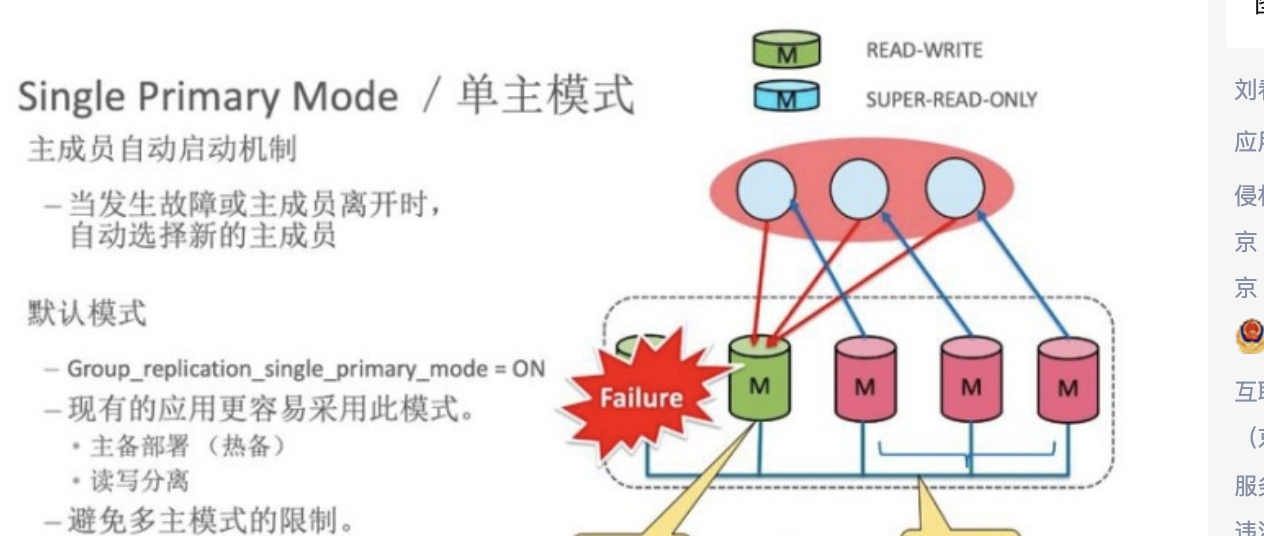 - MGR两种模式-多主(不推荐) ```bash - 组内所有node可以数据写入和读取 - 不同成员对同一条记录进行update,写写冲突,根据组内成员提交的顺序(在群组复制的一致性校验阶段,取得校验成功的先后次序)判断,后提交事务执行回滚处理 - 多主模式需要确保数据写入的一致性,限制如下 - 支持InnoDB - 表必须有主键 - gtid-mode=on - binlog格式为ROW - 对同一个对象执行DDL和DML在同一个node执行 - 不支持串行隔离级别 ``` 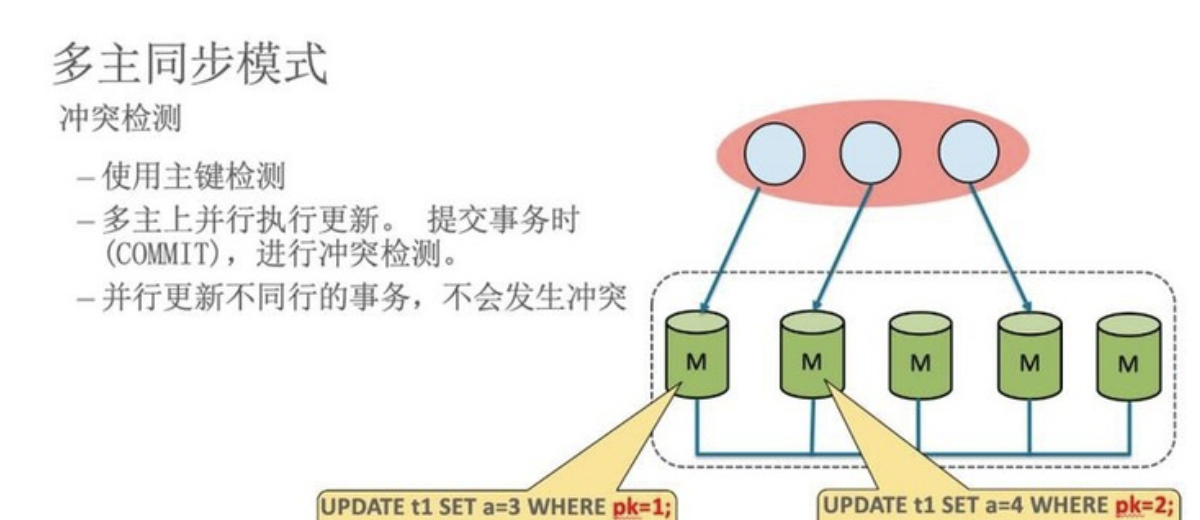 - 高可用 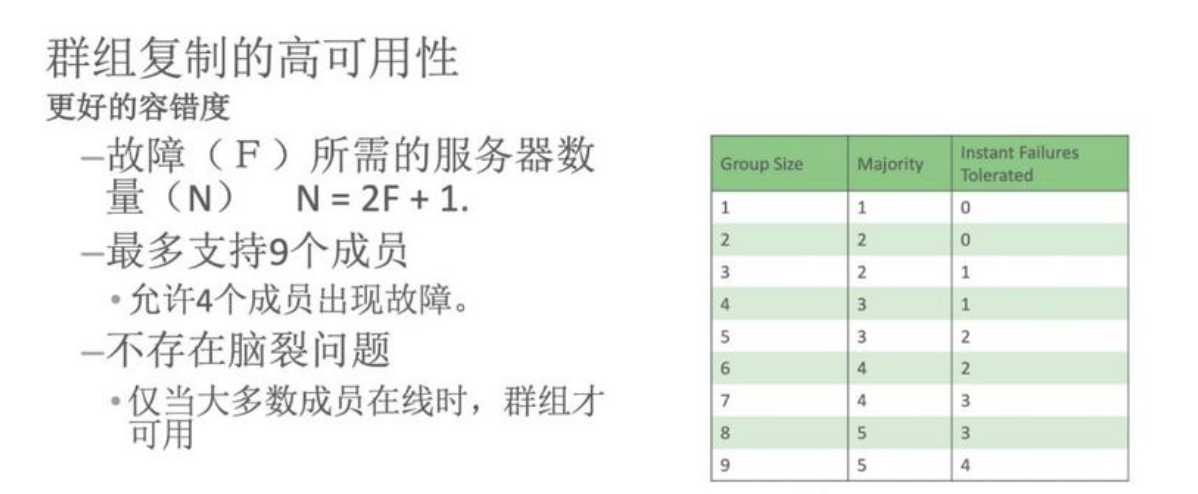 - MGR会监测网络分区,不存在脑裂 ```bash - 部分成员检测到大多数成员丢失,连接到这部分成员的数据更新处理将被挡住并等待,Select可以执行 - S1 和2与 3 4 5 分区,在1和2写操作不能执行,但是可以select - 3 4 5可以进行写操作,网络故障恢复,1和2从3 4 5获取故障期间未更新数据 ``` 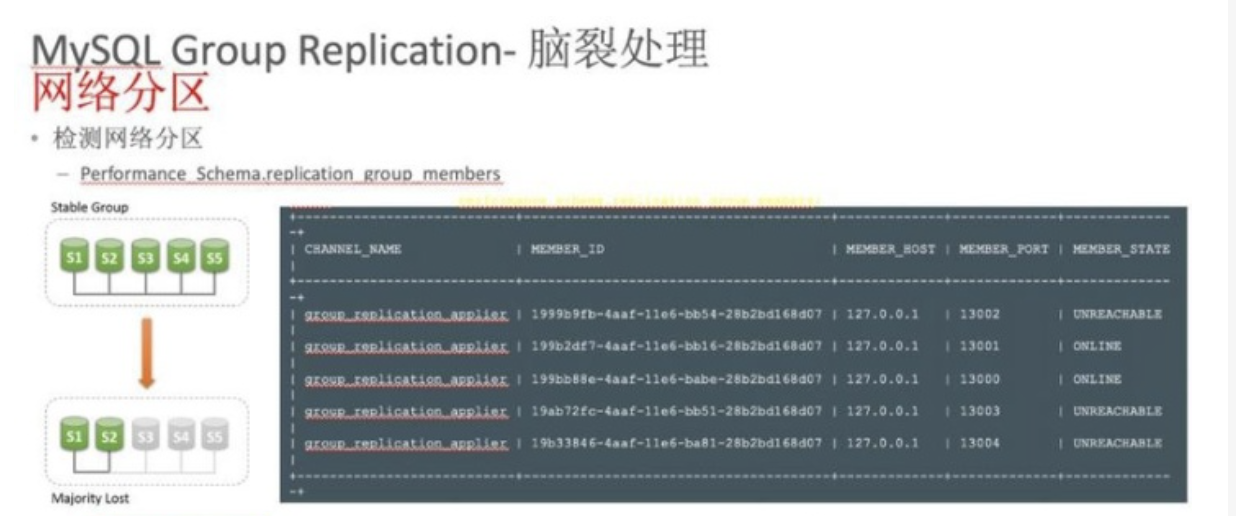 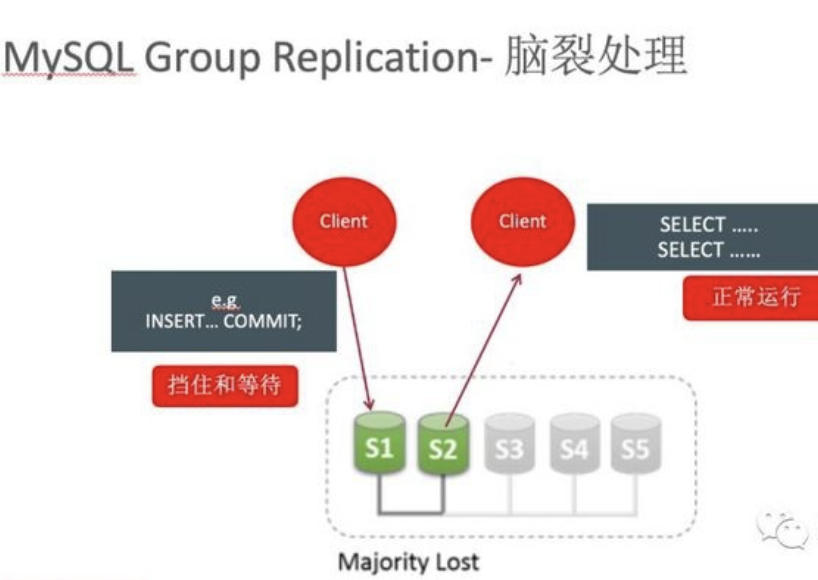 ## 1.2.MGR四种部署方式 - 节点规划 | | | | | | -------- | ------------ | ----------------- | ---- | | host | role | 安装软件 | 备注 | | master01 | mysql router | mysql,mysql shell | | | slave01 | | mysql,mysql shell | | | slave02 | | mysql,mysql shell | | ### 1.2.1.手动安装 仅部署MGR ```bash #步骤 1.安装mysql节点,初始化 2.创建用户 3.配置MGR复制channel 4.启动引导节点 5.启动其他节点 6.确认状态 ``` - 准备三台数据库节点 ```bash #初始化mysql node #3.初始化数据 shell> mysqld --initialize-insecure --user=mysql --basedir=/chj/class/dowland/mysql-8.0.24 --datadir=/chj/class/data/mysql3306/var #配置文件 ##master mysqld --defaults-file=/chj/class/data/mysql3306/etc/my.cnf --user=mysql & create user 'qianlong'@'%' identified with mysql_native_password by '123456'; grant all on *.* to qianlong@'172.%'; [root@master app]# cat > /chj/class/data/mysql3306/etc/my.cnf <<EOF [client] socket=/tmp/mysql.sock [mysqld] user=mysql basedir= /chj/class/dowland/mysql-8.0.24 datadir=/chj/class/data/mysql3306/var/ socket= /chj/class/data/mysql3306/tmp/mysql.sock pid_file= /chj/class/data/mysql3306/var/mysql.pid tmpdir= /chj/class/data/mysql3306/tmp/ slave_load_tmpdir= /chj/class/data/mysql3306/tmp/ log_error= /chj/class/data/mysql3306/log/mysql.err general_log= 0 general_log_file= /chj/class/data/mysql3306/log/mysql.log server_id=151 gtid_mode=ON enforce_gtid_consistency=ON binlog_checksum=NONE binlog_transaction_dependency_tracking=WRITESET transaction_write_set_extraction=XXHASH64 loose-group_replication_group_name="ca842376-1c50-42ac-bb57-a5adc7da7a12" loose-group_replication_start_on_boot=OFF loose-group_replication_local_address= "172.21.188.37:33061" loose-group_replication_group_seeds= "172.21.188.37:33061,172.21.188.36:33062,172.21.188.19:33063" loose-group_replication_bootstrap_group=OFF loose-group_replication_ip_whitelist="172.21.188.37,172.21.188.36,172.21.188.19" loose-group_replication_enforce_update_everywhere_checks = OFF EOF ##slave1 cat > /chj/class/data/mysql3306/etc/my.cnf <<EOF [client] socket=/tmp/mysql.sock [mysqld] user=mysql basedir= /chj/class/dowland/mysql-8.0.24 datadir=/chj/class/data/mysql3306/var/ socket= /chj/class/data/mysql3306/tmp/mysql.sock pid_file= /chj/class/data/mysql3306/var/mysql.pid tmpdir= /chj/class/data/mysql3306/tmp/ slave_load_tmpdir= /chj/class/data/mysql3306/tmp/ log_error= /chj/class/data/mysql3306/log/mysql.err general_log= 0 general_log_file= /chj/class/data/mysql3306/log/mysql.log server_id=152 gtid_mode=ON enforce_gtid_consistency=ON binlog_checksum=NONE binlog_transaction_dependency_tracking=WRITESET transaction_write_set_extraction=XXHASH64 loose-group_replication_group_name="ca842376-1c50-42ac-bb57-a5adc7da7a12" loose-group_replication_start_on_boot=OFF loose-group_replication_local_address= "172.21.188.36:33062" loose-group_replication_group_seeds= "172.21.188.37:33061,172.21.188.36:33062,172.21.188.19:33063" loose-group_replication_bootstrap_group=OFF loose-group_replication_ip_whitelist="172.21.188.37,172.21.188.36,172.21.188.19" loose-group_replication_enforce_update_everywhere_checks = OFF EOF ##slave2 cat > /chj/class/data/mysql3306/etc/my.cnf <<EOF [client] socket=/tmp/mysql.sock [mysqld] user=mysql basedir= /chj/class/dowland/mysql-8.0.24 datadir=/chj/class/data/mysql3306/var/ socket= /chj/class/data/mysql3306/tmp/mysql.sock pid_file= /chj/class/data/mysql3306/var/mysql.pid tmpdir= /chj/class/data/mysql3306/tmp/ slave_load_tmpdir= /chj/class/data/mysql3306/tmp/ log_error= /chj/class/data/mysql3306/log/mysql.err general_log= 0 general_log_file= /chj/class/data/mysql3306/log/mysql.log server_id=153 gtid_mode=ON enforce_gtid_consistency=ON binlog_checksum=NONE binlog_transaction_dependency_tracking=WRITESET transaction_write_set_extraction=XXHASH64 loose-group_replication_group_name="ca842376-1c50-42ac-bb57-a5adc7da7a12" loose-group_replication_start_on_boot=OFF loose-group_replication_local_address= "172.21.188.19:33063" loose-group_replication_group_seeds= "172.21.188.37:33061,172.21.188.36:33062,172.21.188.19:33063" loose-group_replication_bootstrap_group=OFF loose-group_replication_ip_whitelist="172.21.188.37,172.21.188.36,172.21.188.19" loose-group_replication_enforce_update_everywhere_checks = OFF EOF ``` - 配置channel和Node ```bash 1.所有节点操作 #安装MGR插件 INSTALL PLUGIN group_replication SONAME 'group_replication.so'; #设置复制账号 SET SQL_LOG_BIN=0; CREATE USER repl@'%' IDENTIFIED BY 'repl'; GRANT REPLICATION SLAVE ON *.* TO repl@'%'; FLUSH PRIVILEGES; SET SQL_LOG_BIN=1; #设置复制通道 CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='repl' FOR CHANNEL 'group_replication_recovery'; 2.主节点操作 #启动MGR单主模式 ##主库 设置引导节点 启动主节点 1.开启MGR单节点引导 SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF; #一定关闭 不然会有新的MGR集群 2.查看MGR组信息 mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ | group_replication_applier | c1e210d0-8c0f-11ec-a239-fa202013137b | master01 | 3306 | ONLINE | PRIMARY | 8.0.24 | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ 3.从节点加入 ##从库加入 reset master; START GROUP_REPLICATION; #查看节点状态 SELECT * FROM performance_schema.replication_group_members; #停止MGR STOP GROUP_REPLICATION; ``` - 数据插入测试 ```bash CREATE TABLE `runoob_tbl` ( `runoob_id` int unsigned NOT NULL AUTO_INCREMENT, `runoob_title` varchar(100) NOT NULL, `runoob_author` varchar(40) NOT NULL, `submission_date` date DEFAULT NULL, PRIMARY KEY (`runoob_id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb3; insert into runoob_tbl(runoob_title, runoob_author, submission_date) values("学习 PHP", "菜鸟教程", NOW()); #检验其他两个节点数据 ``` - 高可用测试 ```bash #master01直接kill,检验是否故障转移 3个节点,可以宕机一个节点不可用 #master01 kill -9 mysql #slave提升 pri SELECT * FROM performance_schema.replication_group_members; show variables like '%read_only%'; #插入数据测试 insert into runoob_tbl(runoob_title, runoob_author, submission_date) values("学习 MySQL", "oldboy教程", NOW()); ``` - recovery测试 ```bash #宕机的主节点master01恢复 mysqld --defaults-file=/chj/class/data/mysql3306/etc/my.cnf --user=mysql & #查看节点状态和数据补充 SELECT * FROM performance_schema.replication_group_members; ``` ### 1.2.2.MySQL Shell安装+myrouter部署 ```bash #简介 MySQL Shell,可编程的高级客户端,支持标准SQL语法、JavaScript语法、Python语法,以及API接口,可以更方便的管理和使用MySQL服务器。 1.安装mysql,初始化 2.MySQL Shell客户端连入 3.检查前置条件 4.创建MGR集群 ``` - mysql shell客户端连入 ```bash tar xf mysql-router-8.0.28-linux-glibc2.12-x86_64.tar.xz tar xf mysql-shell-8.0.28-linux-glibc2.12-x86-64bit.tar.gz #进入shell ./mysqlsh #创建Mysql连接 MySQL JS > \c qianlong@172.21.188.37:3306 Creating a session to 'qianlong@172.21.188.37:3306' Please provide the password for 'qianlong@172.21.188.37:3306': ****** Save password for 'qianlong@172.21.188.37:3306'? [Y]es/[N]o/Ne[v]er (default No): y #检查权限,所有节点 dba.configureInstance(); The instance 'master01:3306' is already ready to be used in an InnoDB cluster. #检查配置,所有节点 dba.checkInstanceConfiguration("qianlong@172.21.188.37:3306"); #安装插件,所有节点 mysql>INSTALL PLUGIN group_replication SONAME 'group_replication.so'; #创建集群,在主节点即可 var cluster = dba.createCluster('myCluster'); cluster.status(); #添加节点,在主节点shell执行 var cluster = dba.getCluster('myCluster'); cluster.addInstance('qianlong@172.21.188.36:3306'); ``` ### 1.2.3配置mysql-router - 安装 ```bash tar xf mysql-router-8.0.28-linux-glibc2.12-x86_64.tar.xz cd mysql-router-8.0.28-linux-glibc2.12-x86_64/bin # 注册router到集群,生成myrouter目录, 并生成启动程序和配置文件. ./mysqlrouter --bootstrap root@master:3306 -d ./myrouter --user=root vim ./myrouter/mysqlrouter.conf #仅修改以下配置部分即可 [routing:myCluster_rw] bind_address=0.0.0.0 #绑定本机 bind_port=6446 #读写(单主模式下连接primaryduankou) destinations=metadata-cache://myCluster/?role=PRIMARY #读取MGR集群myCluster的pri节点 routing_strategy=first-available protocol=classic [routing:myCluster_ro] bind_address=0.0.0.0 bind_port=6447 destinations=metadata-cache://myCluster/?role=SECONDARY #读取SEC节点 routing_strategy=round-robin-with-fallback protocol=classic # 启动myrouter myrouter/start.sh ``` - 连接router ```bash mysql -u root -h 127.0.0.1 -P 6446 -p #读写节点 mysql -u root -h 127.0.0.1 -P 6447 -p #只读节点 ``` - 验证功能 ```bash 1.数据同步 mysql -u root -h 127.0.0.1 -P 6446 -p #连接primary节点 select @@server_id; #验证是否是主节点 use school; insert into runoob_tbl(runoob_title, runoob_author, submission_date) values("myrouter测试", "菜鸟教程", NOW()); #查看3个节点是否数据同步成功 2.读写分离 #写节点验证 连接6446仅能连接写节点且可以进行 Write/Read操作 #读节点流量测试验证 - myrouter读流量分发是指流量连接均衡,比如第一次连接slave01,第二个连接slave02,轮训方式实现负载均衡 mysql -u root -h 127.0.0.1 -P 6447 -p show proceslist; 可以发现slave节点有routerq的负载连接 3.宕机测试 master节点 shutdown或者kill测试 MGR进行高可用转移 myrouter节点再次验证读写节点是否正常,转换到后端failover转移后的节点 ``` ### MRG参数整理 https://cdn.modb.pro/db/23301 # 3.监控MGR ## 3.1.成员状态 ```bash #MGR node状态 offline-->online-->re-->error #MGR加入节点状态 re-->online re-->un ``` 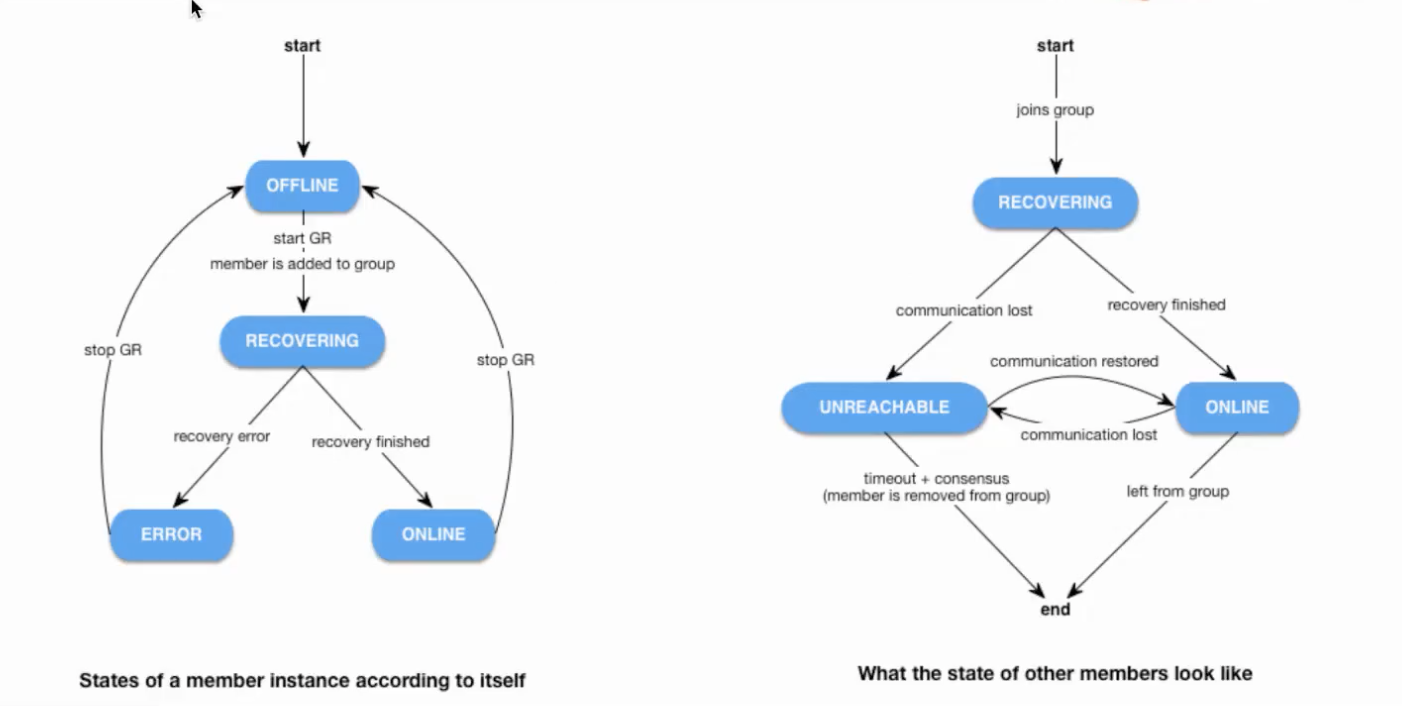 ```bash #查看成员状态 mysql> select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+--------------+-------------+--------------+-------------+----------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | +---------------------------+--------------------------------------+--------------+-------------+--------------+-------------+----------------+ | group_replication_applier | af39db70-6850-11ec-94c9-00155d064000 | 192.168.6.27 | 4306 | ONLINE | PRIMARY | 8.0.25 | | group_replication_applier | b05c0838-6850-11ec-a06b-00155d064000 | 192.168.6.27 | 4307 | ONLINE | SECONDARY | 8.0.25 | | group_replication_applier | b0f86046-6850-11ec-92fe-00155d064000 | 192.168.6.27 | 4308 | ONLINE | SECONDARY | 8.0.25 | +---------------------------+--------------------------------------+--------------+-------------+--------------+-------------+----------------+ 输出结果中主要几个列的解读如下: MEMBER_ID 列值就是各节点的 server_uuid,用于唯一标识每个节点,在命令行模式下,调用 udf 时传入 MEMBER_ID 以指定各节点。 MEMBER_ROLE 表示各节点的角色,如果是 PRIMARY 则表示该节点可接受读写事务,如果是 SECONDARY 则表示该节点只能接受只读事务。如果只有一个节点是 PRIMARY,其余都是 SECONDARY,则表示当前处于 单主模式;如果所有节点都是 PRIMARY,则表示当前处于 多主模式。 MEMBER_STATE 表示各节点的状态,共有几种状态:ONLINE、RECOVERING、OFFLINE、ERROR、UNREACHABLE 等,下面分别介绍几种状态。 ONLINE,表示节点处于正常状态,可提供服务。 RECOVERING,表示节点正在进行分布式恢复,等待加入集群,这时候有可能正在从donor节点利用clone复制数据,或者传输binlog中。 OFFLINE,表示该节点当前处于离线状态。提醒,在正要加入或重加入集群时,可能也会有很短瞬间的状态显示为 OFFLINE。 ERROR,表示该节点当前处于错误状态,无法成为集群的一员。当节点正在进行分布式恢复或应用事务时,也是有可能处于这个状态的。当节点处于ERROR状态时,是无法参与集群事务裁决的。节点正在加入或重加入集群时,在完成兼容性检查成为正式MGR节点前,可能也会显示为ERROR状态。 UNREACHABLE,当组通信消息收发超时时,故障检测机制会将本节点标记为怀疑状态,怀疑其可能无法和其他节点连接,例如当某个节点意外断开连接时。当在某个节点上看到其他节点处于 UNREACHABLE 状态时,有可能意味着此时部分节点发生了网络分区,也就是多个节点分裂成两个或多个子集,子集内的节点可以互通,但子集间无法互通。 当节点的状态不是ONLINE 时,就应当立即发出告警并检查发生了什么。 在节点状态发生变化时,或者有节点加入、退出时,表 performance_schema.replication_group_members 的数据都会更新,各节点间会交换和共享这些状态信息,因此可以在任意节点查看。 ``` ## 3.2.事务和队列状态监控 ```bash #查看集群成员队列 select MEMBER_ID as id,COUNT_TRANSACTIONS_IN_QUEUE as trx_qu from replication_group_member_stats ; +--------------------------------------+-------------------+---------------------+----------+----------+----------+ | id |trx_tobe_certified |relaylog_tobe_applied| trx_chkd | trx_done | proposed | +--------------------------------------+-------------------+---------------------+----------+----------+----------+ | 4ebd3504-11d9-11ec-8f92-70b5e873a570 | 0 | 0 | 422248 | 6 | 422248 | | 549b92bf-11d9-11ec-88e1-70b5e873a570 | 0 | 238391 | 422079 | 183692 | 0 | | 5596116c-11d9-11ec-8624-70b5e873a570 | 2936 | 238519 | 422115 | 183598 | 0 | | ed5fe7ba-37c2-11ec-8e12-70b5e873a570 | 2976 | 238123 | 422167 | 184044 | 0 | +--------------------------------------+-------------------+---------------------+----------+----------+----------+ 其中,relaylog_tobe_applied 的值表示远程事务写到relay log后,等待回放的事务队列,trx_tobe_certified 表示等待被认证的事务队列大小,这二者任何一个值大于0,都表示当前有一定程度的延迟。 还可以通过关注上述两个数值的变化,看看两个队列是在逐步加大还是缩小,据此判断Primary节点是否"跑得太快"了,或者Secondary节点是否"跑得太慢"。 多提一下,在启用流控(flow control)时,上述两个值超过相应的阈值时(group_replication_flow_control_applier_threshold 和 group_replication_flow_control_certifier_threshold 默认阈值都是 25000),就会触发流控机制。 #查看工作线程状态 mysql> select * from replication_applier_status +---------------------------+---------------+-----------------+----------------------------+ | CHANNEL_NAME | SERVICE_STATE | REMAINING_DELAY | COUNT_TRANSACTIONS_RETRIES | +---------------------------+---------------+-----------------+----------------------------+ | group_replication_applier | ON | NULL | 0 | +---------------------------+---------------+-----------------+----------------------------+ #其他监控 另外,也可以查看接收到的事务和已执行完的事务之间的差距来判断: mysql> SELECT RECEIVED_TRANSACTION_SET FROM performance_schema.replication_connection_status WHERE channel_name = 'group_replication_applier' UNION ALL SELECT variable_value FROM performance_schema.global_variables WHERE variable_name = 'gtid_executed'\G *************************** 1. row *************************** RECEIVED_TRANSACTION_SET: 6cfb873b-573f-11ec-814a-d08e7908bcb1:1-3124520 *************************** 2. row *************************** RECEIVED_TRANSACTION_SET: 6cfb873b-573f-11ec-814a-d08e7908bcb1:1-3078139 可以看到,接收到的事务 GTID 已经到了 3124520,而本地只执行到 3078139,二者的差距是 46381。 可以顺便持续关注这个差值的变化情况,估算出本地节点是否能及时追平延迟,还是会加大延迟。 另外,当原来的主节点发生故障,想要手动选择某个节点做为新的主节点时,也应该先判断哪个节点已执行的事务GTID值更大,应优先选择该节点。 #per库相关MGR表 show tables like '%replication%'; ``` # 4.MGR集群管理 ## 4.1.模式切换 - 手动切主 ```bash SELECT group_replication_set_as_primary('e6ccf2a1-8c10-11ec-8bcc-fa2020131854'); SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE "%stage/group_rpl%"; #shell var mic=dba.getCluster() mic.status() mic.setPrimaryInstance('master01:3306') #应用场景 平滑升级:升级-5.7.30-->8.0.20-->24 节点扩缩容 ``` - 自动切换:关节节点或者网络分区 - 单主变多主 ```bash set global group_replication_single_primary_mode=off; set global group_replication_enforce_update_everywhere_checks=on; #切换多主 select group_replication_switch_to_multi_primary_mode(); #切换单主 select group_replication_switch_to_single_primary_mode(); ``` ## 4.2.节点管理 ```bash 1.创建集群 var cluster = dba.createCluster('Cluster01') 2.给集群分配变量 var cluster = dba.getCluster('Cluster01') 3 获取集群结构信息 cluster.describe() 4 查看集群状态 cluster.status() 5.配置检查 新节点加入集群之前,检查配置是否正确 dba.checkInstanceConfiguration('mgr_user@node1:3306') 6 节点验证 验证新加节点上的数据是否会阻止它加入集群: cluster.checkInstanceState('mgr_user@node4:3306') 输出可以是下面这些情况: OK new:实例没有执行任何 GTID 事务,因此不会与集群执行的 GTID 冲突。 OK 可恢复:实例执行的 GTID 与集群种子实例执行的 GTID 不冲突。 ERROR diverged: 实例执行的 GTID 与集群种子实例执行的 GTID 不一致。 ERROR lost_transactions:实例执行的 GTID 比集群种子实例的执行 GTID 多。 State 为 ok,表示可以加入集群。 7.增加实例 cluster.addInstance('mgr_user@node1:3306'); 8.删除实例 cluster.removeInstance('mgr_user@node1:3306'); 9 列出集群中实例的配置 cluster.options() 10 更改集群全局配置 cluster.setOption(option, value) 11 更改集群单个实例的配置 cluster.setInstanceOption(instance, option, value) 12 将实例重新加入集群 cluster.rejoinInstance(instance) 14 切换到多主模式 cluster.switchToMultiPrimaryMode() 15 切换到单主模式 cluster.switchToSinglePrimaryMode('node3:3306') 16 更新集群元数据 cluster.rescan() ``` ```bash MySQL 172.31.7.110:3306 ssl JS > dba.checkInstanceConfiguration('172.31.7.111:3306') Please provide the password for 'root@172.31.7.111:3306': ****** Save password for 'root@172.31.7.111:3306'? [Y]es/[N]o/Ne[v]er (default No): Validating MySQL instance at 172.31.7.111:3306 for use in an InnoDB cluster... This instance reports its own address as 172.31.7.111:3306 Checking whether existing tables comply with Group Replication requirements... No incompatible tables detected Checking instance configuration... Instance configuration is compatible with InnoDB cluster The instance '172.31.7.111:3306' is valid to be used in an InnoDB cluster. { "status": "ok" } ``` # 5.数据同步,恢复 ## 5.1.选主算法 ```bash - 所有节点参与,版本号>权重>uuid 1. 版本号,版本小成为primary - 小于8.0.16,按照号版本好排序 - 大于8.0.17:按照补丁版本号排序 2.节点权重,默认50,越高越靠前 show variables like '%group_replication_member_weight%'; 3.server_uuid:越小越在前 ``` - 容错 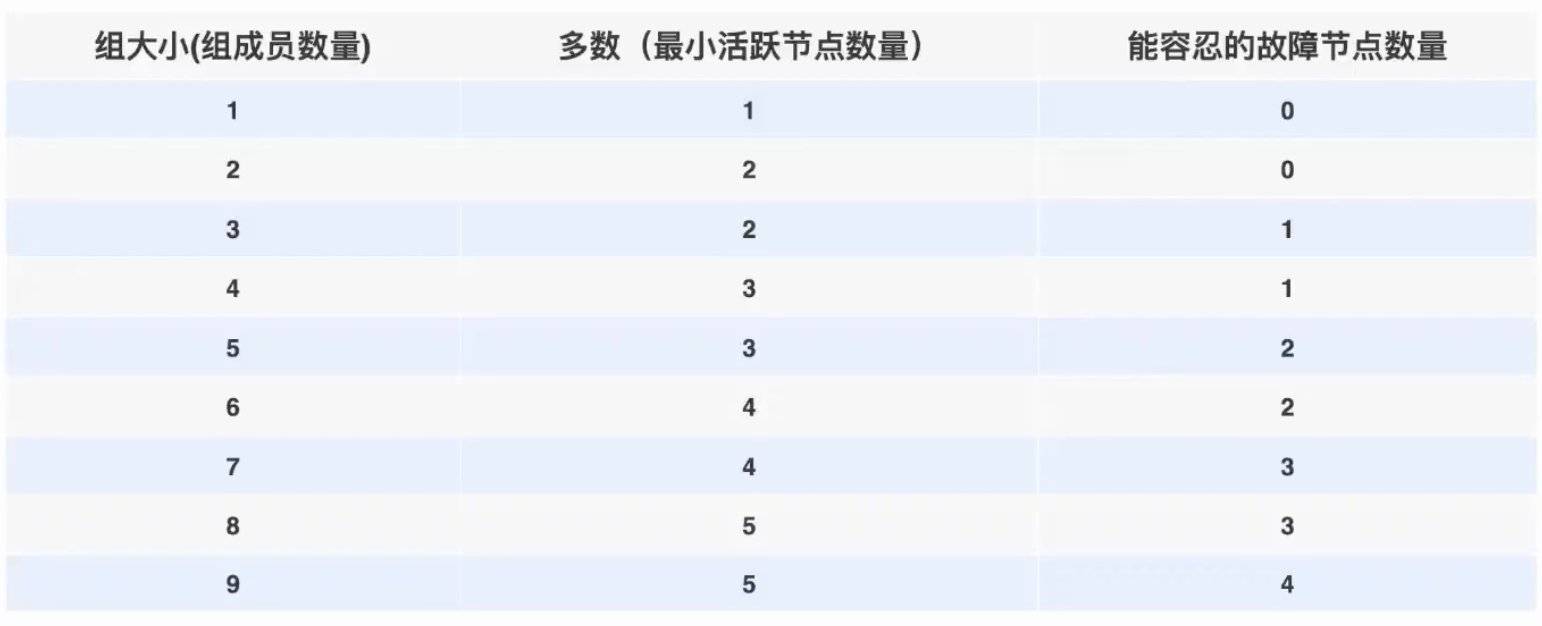 - 版本混用 ```bash 支持5.7和8.0混用 - 8.0可以加入5.7 - 5.7无法加入8.0 支持在线修改协议版本 ``` - 滚动升级 ```bash - 先升级从节点 - 增加新节点,替换老节点 - 最后仅剩下PRI节点 - 停掉主节点,自动切换新节点/手动切换新节点 - 原主节点升到高版本 ``` ## 5.2.数据同步 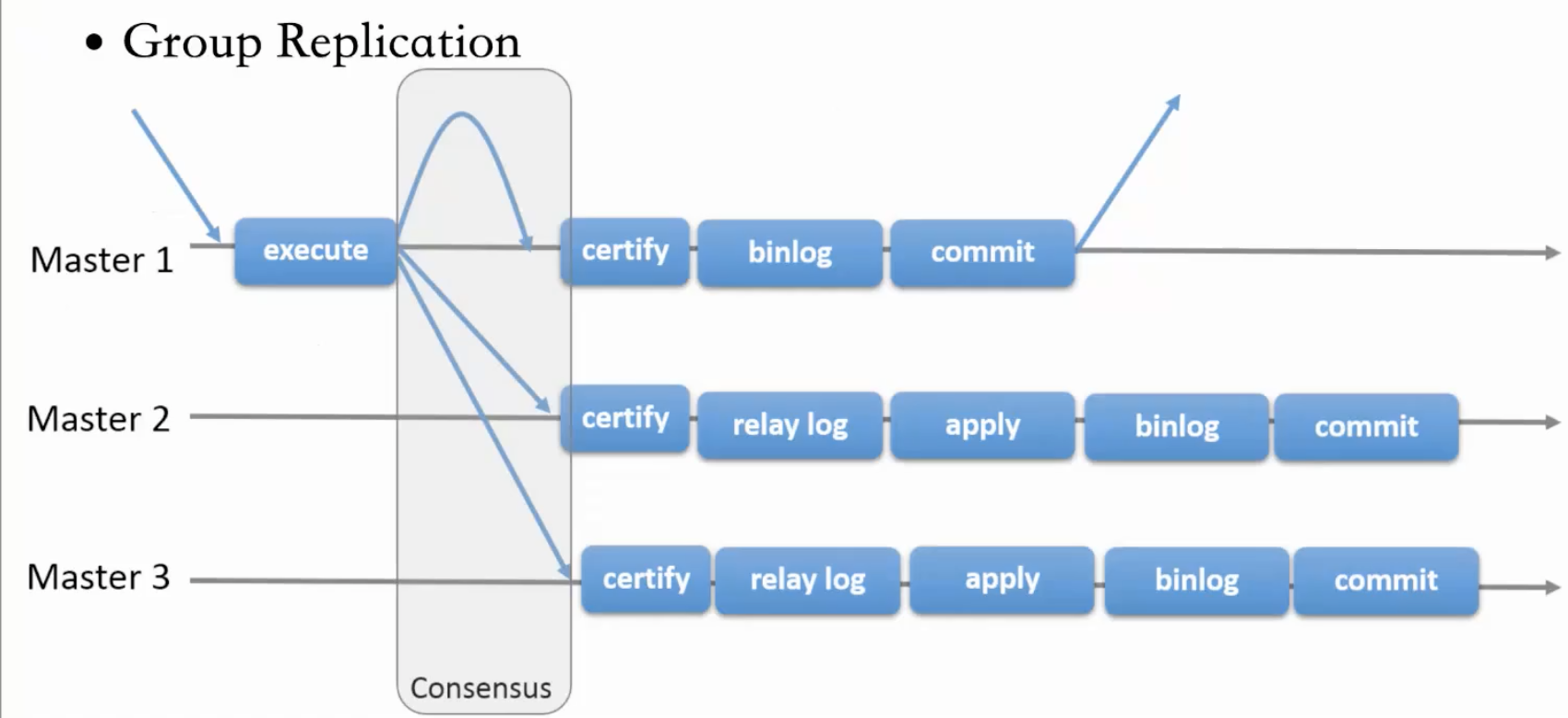 ```bash - 事务写入binlog前写进MGR层 - 事务消息通过Paxos全局排序后,给MGR节点 - 在各个节点认证(远程与本地事务是否冲突,对比事务版本号新旧) - 认证通过后本地节点写binlog完成提交 - 远程节点写relay-log后并行回访 ``` 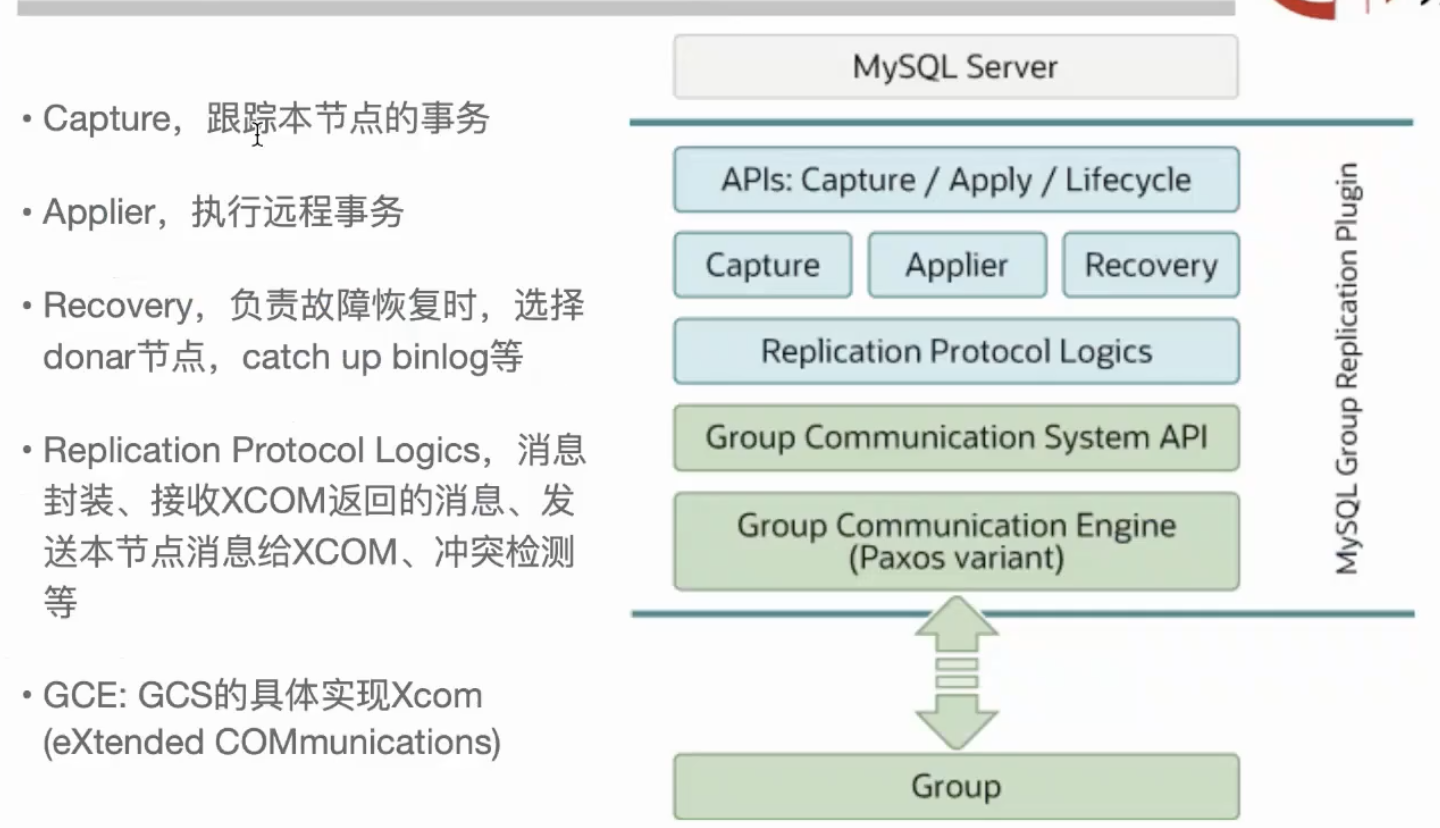 - 新成员加入 ```bash 1.新成员加入,view change 2.自动选择donor节点,分布式恢复 3.从donor节点 clone数据进行恢复 4.追加恢复clone发起到结束期间新增事务 5.追加完成,事务达成一致后,为online状态 ``` ## 5.3.数据恢复 - 本地恢复 ```bash - 故障恢复初始化,包括线程初始化,group成员初始化 - 启动复制通道,先回放d本地relay log.接入MGR层新的Paxos消息入队到 Xcomcache(参数group_replication_message_cache_size,默认一个G) ``` - 全局恢复 ```bash - 选择donor节点,获取缺失事务 - 处理缓存事务 - 所有事务apply,默认完成 -(参数group_replication_recovery_complete_at) - TRANSACTIONS_APPLIED 代表本地所有缓存事务回放完毕才能加入组进行服务 - DISABLE:无需本地缓存事务回放完毕加入组提供服务 - 通知其他节点,本节点上线 #如果TPS很大,cache_size超过则失败. ``` - 整体 ```bash - 节点加入或者重新加入集群,补差异数据 - 自动选择donor接受事务数据 - 自动计算事务差距(参数group_replication_clone_threshold) - 差异少 binlog - 差异大 clone - 自动尝试 retyr_count次 - 完成标记 group_replication_recovery_complete_at #阈值定义group_replication_clone_threshold - 事务差异未超过,binlog - 需要事务不存在,使用clone - 两端都要启动clone,且具有backup权限 ``` # 6.MGR冲突监测与流控 ## 6.1.冲突监测 ```bash #事务执行过程 - 事务在引擎层prepare后,写入binlog前写入MGR层 - 事务封装消息通过Paxos全局排序后广播到各个节点 - 在各节点进行单独认证(certifiy) - 认证后再本地节点写binlog完成提交 - 其他节点写relay log,applier线程并行回访 #冲突监测 - MGR certifiy阶段,就是事务冲突监测 - 存在多节点更新同一条记录,或者交叉更新问题 - 单主 or 多主都要监测(单主模式从节点read-only关闭写入) - 认证数据库 - 一个std::map的kv结构 - key:hash(db+table+pk) value:gtid set - 待认证事务队列 - 事务节点 uuid,gtid_executed,writeset #事务排序 - 封装事务消息 - Transaction Message:是否本地事务,快照版本,执行线程,gtid等,用于认证 - gtid message:gtid,组提交相关 - transaction Data - Paxos广播,RR轮询方式排序 - 没有事务,也有空操作参与排序 - 大事务、网络延时,分区 导致其他节点达成多数据认证慢,代价很高 #事务认证 - 基于pipeline机制 - 事务队列>=认证队列》=applier队列 - 先判断是否是远程事务 - 对比快照版本 - 认证通过后,分配gtid,更新到数据库 #冲突监测数据库清理 - 判断事务是否可以commit or rollback - 维护内存中,不宜过大,每60s清理过期事务 - 优化(20s)清理 - 代码优化 给hash表加上索引 - 扫描gtid_executed队列,对比后决定是否处理 #最佳实践 - 高并发,启用流控 - 不要跑大事务(认证数据库扫描代价太大) - 减少DDL频次,避免高峰期 ``` ## 6.2.流控 ```bash #为什么做流控 - 节点配置不一致 - 处理能力差节点有延时,复制延时导致无法读取新数据 - 保护集群稳定性:加入新节点,需要选择一个作为donor节点,如果节点延时选Primary,影响主节点写入性能 - 当某节点中堆积大量延迟事务队列时,也很容易造成该节点发生OOM风险。 综上几点,为了避免个别节点存在严重的事务复制延迟及其他风险,必要时可以采用流量控制(下面简称“流控”)来避免/缓解这个问题,降低节点间的事务延迟差距。 #MGR流控有几个要点: 1. 基于两个队列 - 事务认证队列:group_replication_flow_control_applier_threshold - 被applied的relay log队列:group_replication_flow_control_certifier_threshold - 默认值均为25000,实行配额控制 2. 启动流程(基于 quot 实现) - group_replication_flow_control_mode,默认值:QUOTA - 当任何一个队列大小超过设定阈值(配额)后,就会触发流控机制。 - 仅影响启用流控的节点,不影响MGR中的其他节点(在PXC里是所有节点同时被流控影响) 3. group_replication_flow_control_member_quota_percent:设置流控配额百分比,会在多个启用流控的Primary节点间平摊配额 4.流控只针对写事务,不影响只读事务 5.group_replication_flow_control_period: - 触发流控后,会暂缓事务写入请求 - 默认值1,1s后再次检查是否还超过阈值。如果还是超过则继续流控,否则的话就放开事务写入请求 - 实际使用:效果有限,事务写入高峰频繁造成TPS抖动,流控效果不好 - 优化:GreatSQL针对场景缺陷,重新设计流控算法。增加主从延迟时间来计算流控阈值,并且同时考虑了大事务处理和主从节点的同步,流控粒度更细致,不会出现官方社区版本的1秒小抖动问题 #相关参数 show variables like '%flow_control%' group_replication_flow_control_mode=QUOTA #启用流控 disable不启用 group_replication_flow_control_period=1 #每1s监测是否 #看认证队列和apply队列值,超过25000触发流控 group_replication_flow_control_applier_threshold group_replication_flow_control_certifier_threshold #多主模式流控配额 group_replication_flow_control_member_quota_percent #流控百分比(每个节点流控百分比) group_replication_flow_control_hold_percent ``` # 7.MGR数据一致性 ```bash - 通过消息传播和施放进行数据同步 - 8.0.14后通过变量 group_replication_consistency 精确地控制每个节点上数据的一致性。 - 一个事务广播到其他节点,达成共识(一致性冲突监测),本地提交,异地异步回方,最终一致性 - 五种模式(8.0.14后) - EVENTUAL(默认) - BEFORE - AFTER - BEFORE_AND_AFTER #特点 优点:MGR+DAL,在单主模式下,可以根据业务场景进行读写分离,不用担心会产生延迟,充分利用了MGR主节点以外的节点。 缺点:使用读写一致性会对性能有极大影响,尤其是网络环境不稳定的场景下。 ``` 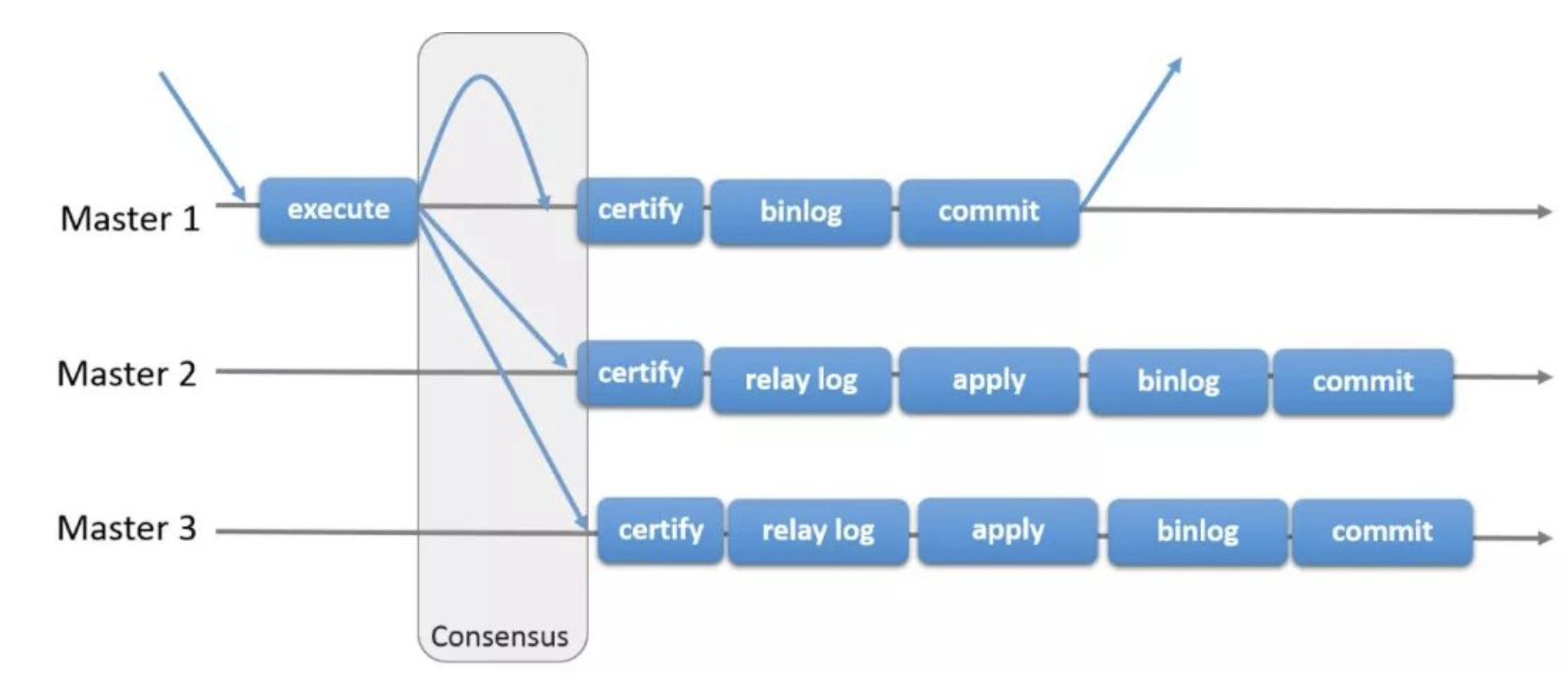 - EVENTUAL ```bash EVENTUAL 默认值,开启该级别的事务(T2),事务执行前不会等待先序事务(T1)的回放完成,也不会影响后序事务等待该事务回放完成。 ``` 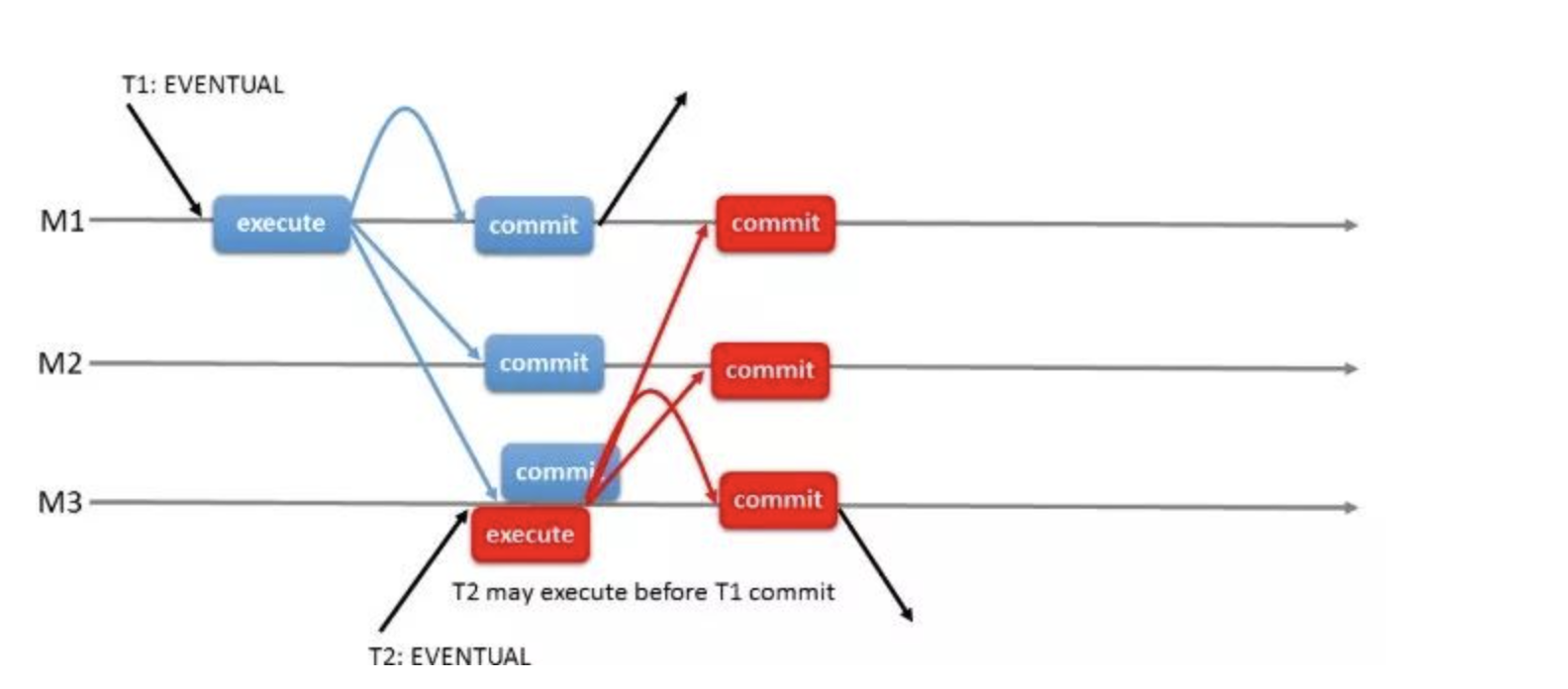 - BEFORE ```bash BEFORE 开启了该级别的事务(T2),在开始前首先要等待先序事务(T1)的回放完成,确保此事务将在最新的数据上执行。 使用场景 - 应用大量写入数据,偶尔进行读取一致性数据,应当选择BEFORE。 - 有特定事务需要读写一致性,以便对敏感数据操作时,始终读取最新的数据;应当选择BEFORE。 ``` 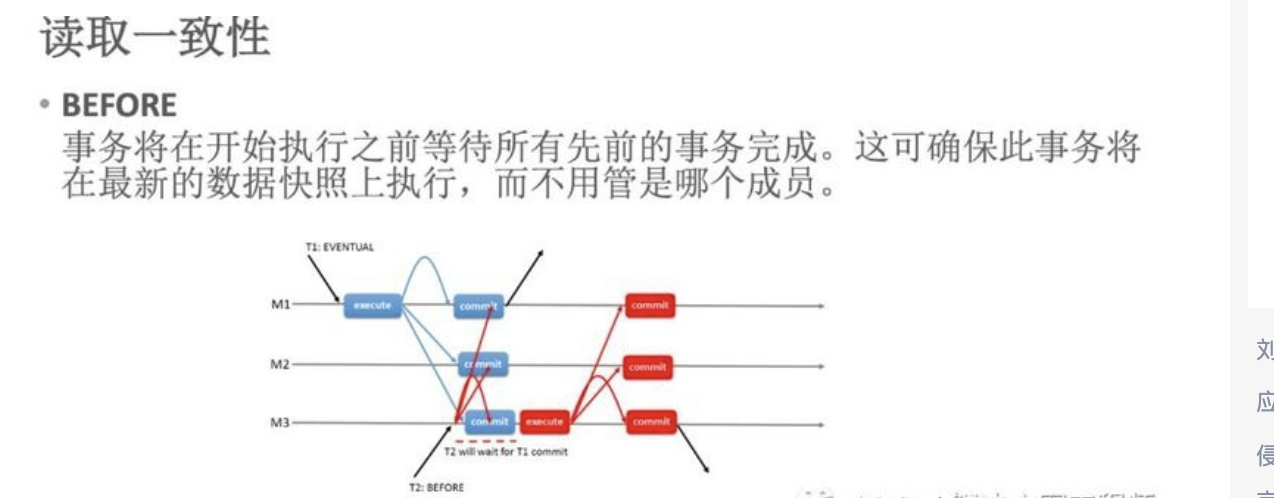 - AFTER ```bash AFTER,开启该级别的事务(T1),只有等该事务回放完成。其他后序事务(T2)才开始执行,这样所有后序事务都会读取包含其更改的数据库状态,而不管它们在哪个成员上执行。 适用场景: - 写少读多的场景进行读写分离,担心读取到过期事务,可选择AFTER。 - 只读为主的集群,有RW的事务需要保证提交的事务能被其他后序事务读到最新读数据,可选择AFTER 特点: - 任何单点的故障都会导致集群不可用,到节点提出集群(5-10s) - 可以满足部分业务对严格数据一致性的需求,但对一般的业务却是极度不友好的 - 不推荐使用 ``` 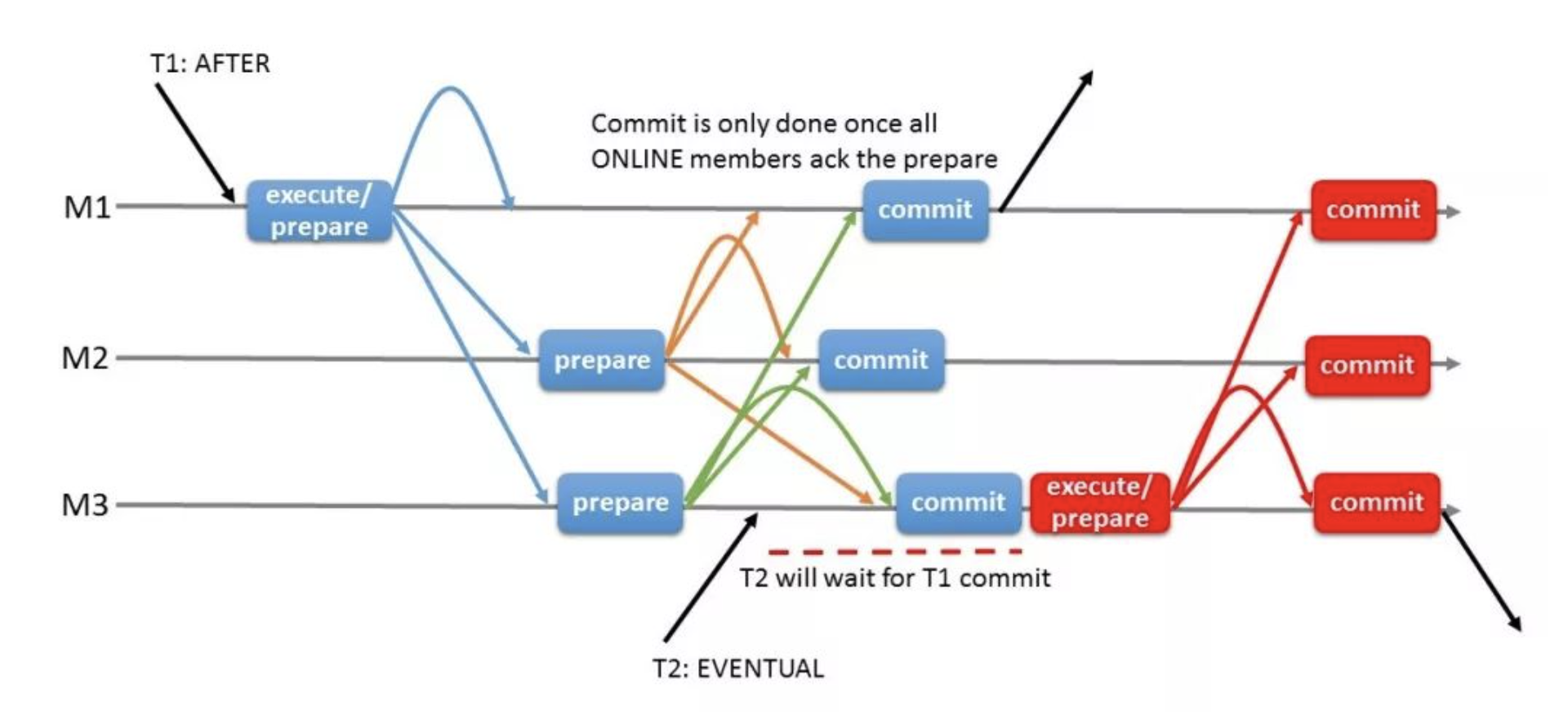 - BEFORE_AND_AFTER ```bash 开启该级别等事务(T2),需要等待前序事务的回放完成(T1);同时后序事务(T3)等待该事务的回放完成; 场景: 有一个读为主的集群,有RW的事务既要保证读到最新的数据,又要保证这个事务提交后,被其他后序事务读到;在这种情况下可选择BEFORE_AND_AFTER。 ``` 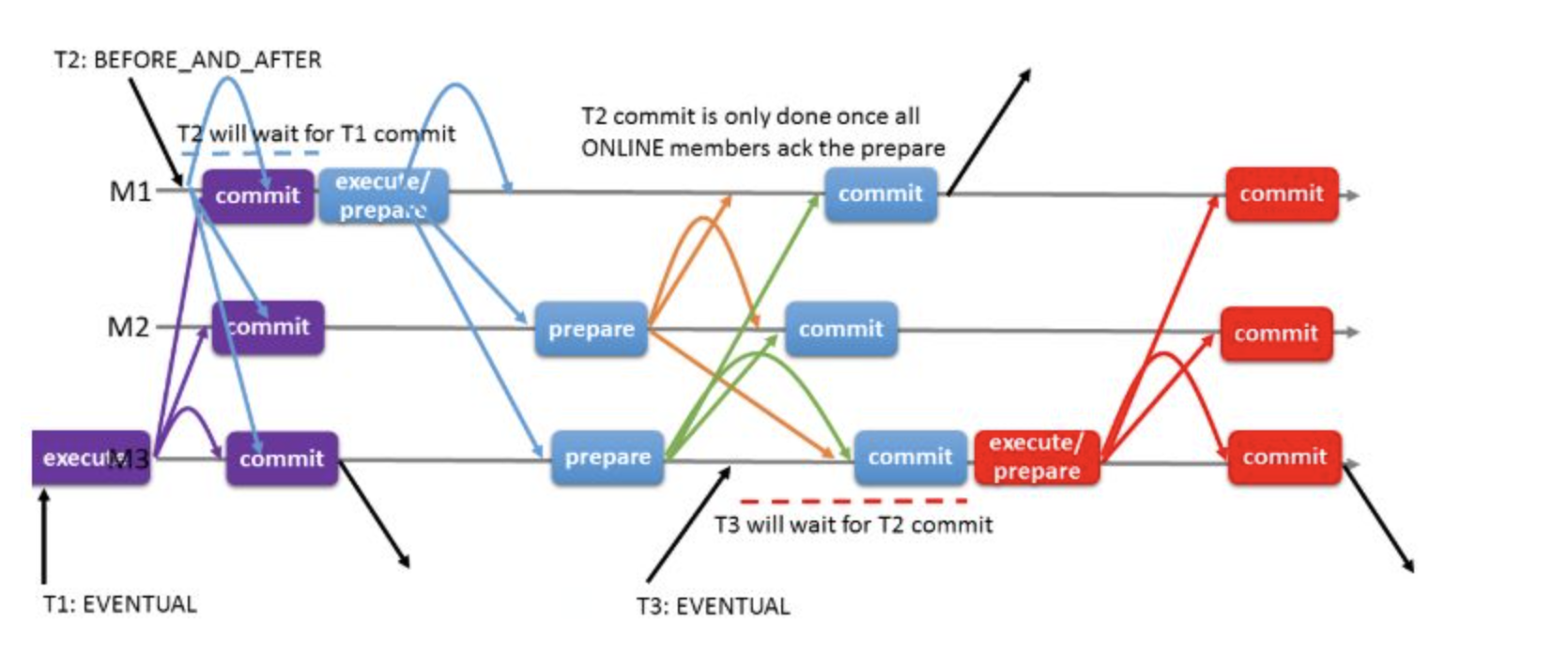 - BEFORE_ON_PRIMARY_FAILOVER ```bash 开启该级别等事务(T2),需要等待前序事务的回放完成(T1);同时后序事务(T3)等待该事务的回放完成; ``` 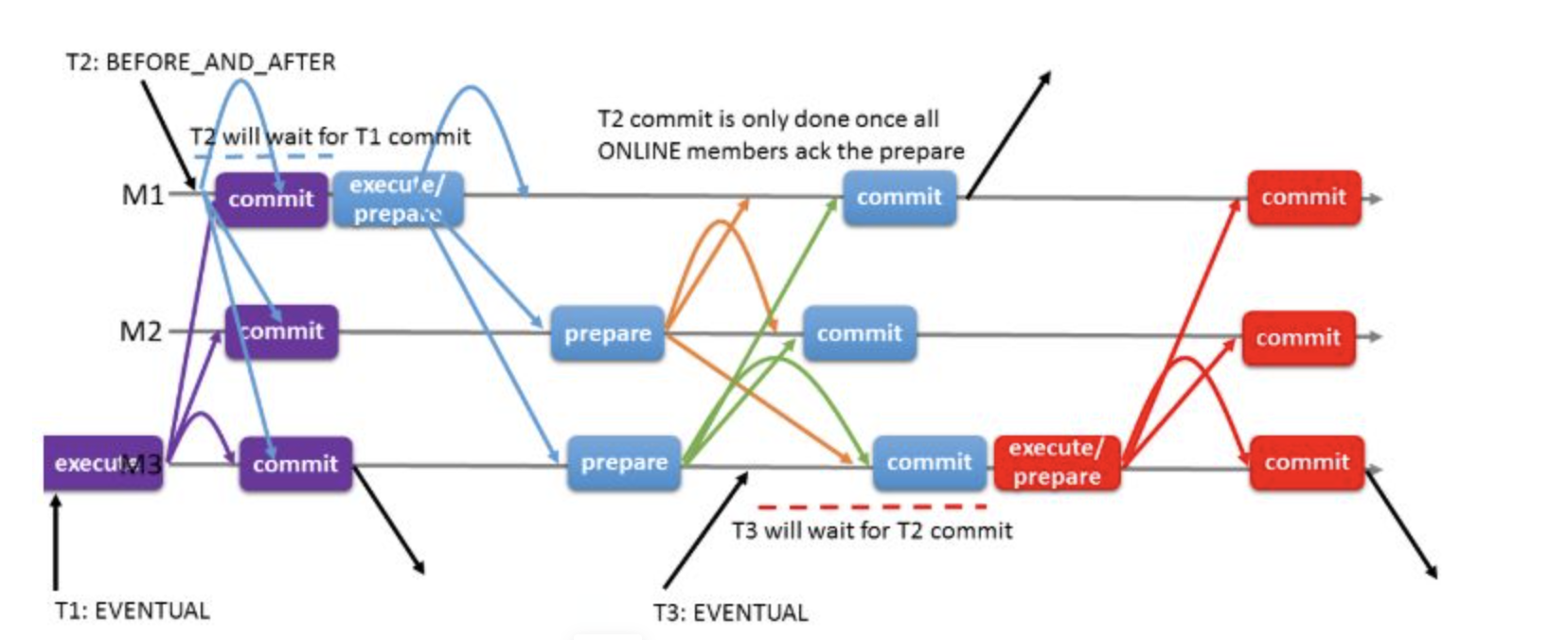 - 主节点故障转移,从节点切换成主节点前,处理积压事务 ```bash #方案1 不管积压事务,处理堆积事务+旧事物,可能读取旧版本数据 #方案2 访问限制,积压事务处理完成处理新事务 ``` - 一致性级别选择建议 ```bash 一致性级别选择建议 对于绝大多数场景,使用默认的 EVENTUAL 等级就足够了;尤其是在使用单主模式时,如果需要实时读取事务数据,只需向Primary节点发起请求即可。 进一步,如果担心Primary节点切换时会读取到旧事务数据,可以提高到 BEFORE_ON_PRIMARY_FAILOVER 级别。 更进一步,如果希望在Secondary节点也能及时读取到最新事务数据,以此提高读扩展能力,可以提高到 BEFORE 级别。 更高的一致性级别就不再建议使用了,潜在的风险以及bug比较多。 P.S,各个节点的一致性级别最好都设置成一样,并且在运行过程中也不要修改其session级选项值,避免造成不可预料的影响。 ``` # 8.MGR性能优化与最佳实践 ```bash 1. 性能瓶颈 在MGR架构中,可能存在众多可能会影响整体性能,包括本地节点中常见的一些性能瓶颈点,也可能包括MGR层产生的。 一般而言,造成MGR性能瓶颈的原因可能有以下几种情况: 集群中,个别节点存在性能瓶颈。 不恰当的流控阈值,导致性能受限。 官方版本流控算法缺陷,导致性抖动大。 大事务造成延迟,甚至节点退出。 网络成为瓶颈,导致消息延迟大。 其他MySQL常见性能瓶颈导致。 接下来,我们针对以上几种情况,分别进行瓶颈分析并给出优化建议。 2. 优化建议 2.1 本地节点存在性能瓶颈 在MGR中,可能各个节点服务器配置等级各不相同,所能承载的业务压力也不同。因此,各节点可能会分别产生不同的事务延迟,或者等待被应用的事务堆积越来越多。 这种情况下,最有效的办法就是提升该节点的服务器配置级别,提高业务承载能力。同时,也要检查MySQL配置选项,是否有设置不合理的地方,并且可以考虑将选项 innodb_flush_log_at_trx_commit 和 sync_binlog 都设置为 0,以降低该节点的磁盘I/O负载,提升事务应用效率。 在GreatSQL中,还可以设置选项 group_replication_single_primary_fast_mode = 1(要求所有节点都这么设置),启用快速单主模式,提升MGR事务应用效率。 2.2 不恰当的流控 在 14.流量控制(流控) 这节内容中我们讲过,MySQL的流控机制有明显的缺陷,实际流控效果很有限,并且还可能会起到反作用,因此不建议启用MySQL的流控机制。即设置选项 group_replication_flow_control_mode = DISABLED。 在GreatSQL中,除了关闭流控外,只需设置选项 group_replication_flow_control_replay_lag_behind = 600,控制MGR主从节点复制延迟阈值,当MGR主从节点因为大事务等原因延迟超过阈值时,就会触发优化后的新的流控机制。 2.3 大事务造成延迟 当Primary上有大事务产生时,很容易造成Secondary在应用大事务过程中存在延迟。 因此,要尽量避免执行大事务。可以将大事务拆分成多个小事务,例如当执行load data导入大批数据时,就可以将导入文件切分成多个小文件。 此外,还可以适当调低 group_replication_transaction_size_limit 阈值,限制事务大小。 还可以通过监控事务状态,防止有个别事务运行时间过久: #活跃时间最长的事务 SELECT * FROM information_schema.innodb_trx ORDER BY trx_started ASC LIMIT N; #等待时间最长的事务 SELECT * FROM sys.innodb_lock_waits ORDER BY wait_age_secs DESC LIMIT N; #特别关注的大事务 SELECT * FROM information_schema.innodb_trx WEHRE trx_lock_structs >= 5 OR -- 超过5把锁 trx_rows_locked >= 100 OR -- 超过100行被锁 trx_rows_modified >= 100 OR -- 超过100行被修改 TIME_TO_SEC(TIMEDIFF(NOW(),trx_started)) > 100; -- 事务活跃超过100秒 当然了,上述这些监控SQL的阈值可根据实际情况自行适当调整。 2.网络存在瓶颈 一般来说,最好是在局域网内运行MGR,甚至在同一个VLAN里运行,使得网络质量尽量有保证。 如果怀疑是因为网络质量比较差导致MGR性能问题的话,可以通过设置选项 group_replication_request_time_threshold 记录那些因为网络延迟较大导致的MGR性能瓶颈(这个选项在GreatSQL中才有,MySQL不支持)。这个选项的单位是毫秒,如果是在局域网内,可以设置为10-50(毫秒)左右;如果是网络质量较差或者跨公网的环境,可以设置为100-10000(即100毫秒 - 10秒)之间。 ``` - 优化 ```bash 节点配置一致, 各个节点负载均衡 建议单主模式,主节点仅负责实时读写事务(mysql router) 网络优化(万兆网络) 启动消息压缩 杜绝大事务-标准 select * from innodb_trx where trx_tables_locked>=5 or #超过5把锁 trx_rows_locked >=1000 or trx_rows_modified>=1000 or TIME_TO_SEC(TIMEDIFF(NOW(),trx_started)) >100 ; #事务执行超过100m ``` - 参数选项 ```bash #单主模式 group_replication_single_primary_mode =ON #事务大小默认10M,调低 group_replication_transaction_size_limit 150000000 #默认10M,大事务拆成小包,记性paxos传输 group_replication_communication_max_message_size #关闭引导,防止集群分裂 group_replication_bootstrap_group #一致性保证 group_replication_consistency - 在主节点读写使用默认 - 多节点读写分离,不希望读取旧数据使用 BEFORE #网络分区,等时长后状态变Error 默认0 group_replication_unreachable_majority_timeout #故障进入只读模式(小于多数派节点) group_replication_exit_state_action ``` - 潜在风险 ```bash - 不同版本不混用 - 多主模式同时 select for update导致死锁 - 对同一个表的DDL和DML在不同节点进行 - 不要跑大事务 ``` - MGR参数设置建议与约束 ```bash 1.参数 #建议只用单主模式 loose-group_replication_single_primary_mode=ON #不要启用引导模式 loose-group_replication_bootstrap_group=OFF #默认值150MB,但建议调低在20MB以内,不要使用大事务 loose-group_replication_transaction_size_limit = 10M #大消息分片处理,每个分片10M,避免网络延迟太大 loose-group_replication_communication_max_message_size = 10M #节点退出后的默认行为,将本节点设置为RO模式 loose-group_replication_exit_state_action = READ_ONLY #超过多长时间收不到广播消息就认定为可疑节点,如果网络环境不好,可以适当调高 loose-group_replication_member_expel_timeout = 5 #建议关闭MySQL流控机制 loose-group_replication_flow_control_mode = "DISABLED" #AFTER模式下,只要多数派达成一致就可以,不需要全部节点一致 loose-group_replication_majority_after_mode = ON #是否设置为仲裁节点 loose-group_replication_arbitrator = 0 #启用快速单主模式 loose-group_replication_single_primary_fast_mode = 1 #当MGR层耗时超过100ms就记录日志,确认是否MGR层的性能瓶颈问题 loose-group_replication_request_time_threshold = 100 #记录更多日志信息,便于跟踪问题 log_error_verbosity=3 2.MGR使用约束与限制 所有表必须是InnoDB引擎。可以创建非InnoDB引擎表,但无法写入数据,在利用Clone构建新节点时也会报错(在GreatSQL中,可以设置选项 enforce_storage_engine = InnoDB 只允许使用InnoDB引擎,而禁用其他引擎)。 所有表都必须要有主键。同上,能创建没有主键的表,但无法写入数据,在利用Clone构建新节点时也会报错。 尽量不要使用大事务,默认地,事务超过150MB会报错,最大可支持2GB的事务(在GreatSQL未来的版本中,会增加对大事务的支持,提高大事务上限,但依然不建议运行大事务)。 如果是从旧版本进行升级,则不能选择 MINIMAL 模式升级,建议选择 AUTO 模式,即 upgrade=AUTO。 由于MGR的事务认证线程不支持 gap lock,因此建议把所有节点的事务隔离级别都改成 READ COMMITTED。基于相同的原因,MGR集群中也不要使用 table lock 及 name lock(即 GET_LOCK() 函数 )。 在多主(multi-primary)模式下不支持串行(SERIALIZABLE)隔离级别。 不支持在不同的MGR节点上,对同一个表分别执行DML和DDL,可能会造成数据丢失或节点报错退出。 在多主(multi-primary)模式下不支持多层级联外键表。另外,为了避免因为使用外键造成MGR报错,建议设置 group_replication_enforce_update_everywhere_checks=ON。 在多主(multi-primary)模式下,如果多个节点都执行 SELECT ... FOR UPDATE 后提交事务会造成死锁。 不支持复制过滤(Replication Filters)设置。 看起来限制有点多,但绝大多数时候并不影响正常的业务使用。 此外,想要启用MGR还有几个要求: 每个节点都要启用binlog。 每个节点都要转存binlog,即设置 log_slave_updates=1。 binlog format务必是row模式,即 binlog_format=ROW。 每个节点的 server_id 及 server_uuid 不能相同。 在8.0.20之前,要求 binlog_checksum=NONE,但是从8.0.20后,可以设置 binlog_checksum=CRC32。 要求启用 GTID,即设置 gtid_mode=ON。 要求 master_info_repository=TABLE 及 relay_log_info_repository=TABLE,不过从MySQL 8.0.23开始,这两个选项已经默认设置TABLE,因此无需再单独设置。 所有节点上的表名大小写参数 lower_case_table_names 设置要求一致。 最好在局域网内部署MGR,而不要跨公网,网络延迟太大的话,会导致MGR性能很差或很容易出错。 建议启用writeset模式,即设置以下几个参数 slave_parallel_type = LOGICAL_CLOCK slave_parallel_workers = N,N>0,可以设置为逻辑CPU数的2倍 binlog_transaction_dependency_tracking = WRITESET slave_preserve_commit_order = 1 slave_checkpoint_period = 2 ```
李延召
2024年5月14日 13:59
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码