DBA专题
DBA授课
DBA公开课
DBA训练营三天
01.Mysql基础入门-数据库简介
02.Mysql基础入门-部署与管理体系
03.MySQL主流版本版本特性与部署安装
04.Mysql-基础入门-用户与权限
05 MySQL-SQL基础2
06 SQL高级开发-函数
07 MySQL-SQL高级处理
08 SQL练习 作业
09 数据库高级开发2
10 Mysql基础入门-索引
11 Mysql之InnoDB引擎架构与体系结构
12 Mysql之InnoDB存储引擎
13 Mysql之日志管理
14 Mysql备份,恢复与迁移
15 主从复制的作用及重要性
16 Mysql Binlog Event详解
17 Mysql 主从复制
18 MySQL主从复制延时优化及监控故障处理
19 MySQL主从复制企业级场景解析
20 MySql主从复制搭建
21 MySQL高可用-技术方案选型
22 MySQL高可用-MHA(原理篇)
23 MySQL MHA实验
24 MySQL MGR
25 部署MySQL InnoDB Cluster
26 MySQL Cluster(MGR)
27 MySQL ProxySQL中间件
相信可能就有无限可能
-
+
首页
05 MySQL-SQL基础2
表中解释 ```sql 管理供应商-Vendors 管理产品目录Products 管理顾客列表Customers 录入顾客订单Orders、OrderItems ``` # 1.DQL-(SELECT)基础2 ## 1.0.SQL执行顺序 书写顺序 -- 书写顺序: select->distinct->from->join->on->where->group by->having->order by->limit 必须字段:select、from -- 可选字段:distinct、join、on、where、group by、having、sum、count、max、avg、order by、limit 执行顺序 ```sql from->on->join->where->group by(开始使用select中的别名,后面的语句中都可以使用别名)->sum、count、max、avg->having->select->distinct->order by->limit ``` ## 1.1.SELECT-基础查询 ```sql #查询单个列,从products表中查询prod_name column,生产中使用指定表名 select prod_name from products; mysql> select prod_name from sql_practice.products; #检索多个列 select prod_id,prod_name,prod_price from products; #检索所有列,此处的*是通配符 生产禁用 select * from products; #查找不重复的行记录,distinct是关键字,放在column name前面 ##不能部分使用distinct。 select distinct(vend_id),distinct(prod_price) from products; 不可用 select vend_id from products; select distinct(vend_id) from products; #返回部分结果 select prod_name from products limit 5; #从行5开始(第一行 行号为0),返回之后的5行结果 6-10行 select prod_name from products limit 5,5; select prod_name from products limit 0,1; select prod_name from products limit 1,1; #limit另一种写法 MySQL支持,offset代表从行5(第6行)开始,取5行 mysql> select prod_name from products limit 5 offset 5; ``` - 关键字(keyword):指电脑语言中预先定义的,有特别意义或者功能的标识符,也叫保留字。 - Mysql keyword大全  ## 1.2.ORDER-排序检索数据 - 子句(clause):SQL语句子句组成,分成可选可必选 select ..from一般是必选,order by可选 - order by - 按单列或多列对结果集排序。 - 按升序或降序对不同列进行结果集排序。 - 按照16进制字节码 字节码排序 ```sql #语法 SELECT column1, column2,... FROM tbl ORDER BY column1 [ASC|DESC], column2 [ASC|DESC],... #按照prod_name 正序排序 mysql> select prod_name from products order by prod_name; #desc 降序排序 mysql> select prod_name from products order by prod_name desc ; #16进制排序 mysql>select prod_name,hex(prod_name) from products order by prod_name ; #多字段asc排序 mysql> select prod_price,prod_name from products order by prod_price,prod_name ; mysql> select prod_price,prod_name,hex(prod_price),hex(prod_name) from products order by prod_price,prod_name ; #多个字段先正序,后降序 mysql> select prod_price,prod_name,hex(prod_price),hex(prod_name) from products order by prod_price asc,prod_name desc ; ``` ## 1.3.WHERE-过滤数据 ### 1.3.0.单个where条件过滤数据 - 检索表中特定条件的行,指定过滤条件也就是**谓词** ```sql #语法 单表:select column_name1,column_name2... from table_name where column_name1='xxx' and .... or ..; #1.查询单个值,等值查询 mysql> select prod_name,prod_price from products where prod_name='fuses'; #2.查询价格小于10美元的产品,范围大于 mysql> select prod_name,prod_price from products where prod_price < 10; #3.查询价格小于等于10美元的产品 mysql> select prod_name,prod_price from products where prod_price <= 10; #4.不匹配检查,列出不是由供应商1003制造的所有产品,要优化的 mysql> select vend_id,prod_name from products where vend_id <>1003; mysql> select vend_id,prod_name from products where vend_id !=1003; #5.范围值检查,检查某个范围区间的值,between...and,检索价格5美元和10美元之间的产品 mysql> select vend_id,prod_name,prod_price from products where prod_price between 5 AND 10; #6.空值检查NULL,当一个字段无值(no value),成为空值NULL,与0,空字符串或者空格不一样 mysql> select vend_id,prod_name,prod_price from products where prod_price IS NULL; mysql> select cust_id from customers where cust_email is NOT NULL; #MySQL8排序规则utf8mb4_0900_ai_ci属于utf8mb4_unicode_ci一种,tidb的默认字符区分大小写 - uft8mb4 表示用 UTF-8 编码方案,每个字符最多占 4 个字节 - 0900 指的是 Unicode 校对算法版本 - ai 指的是口音不敏感。排序时 e,è,é,ê 和 ë 之间没有区别 - ci 表示不区分大小写。排序时 p 和 P 之间没有区别。 - 如果需要重音灵敏度和区分大小写,可以使用 utf8mb4_0900_as_cs 代替。 ```  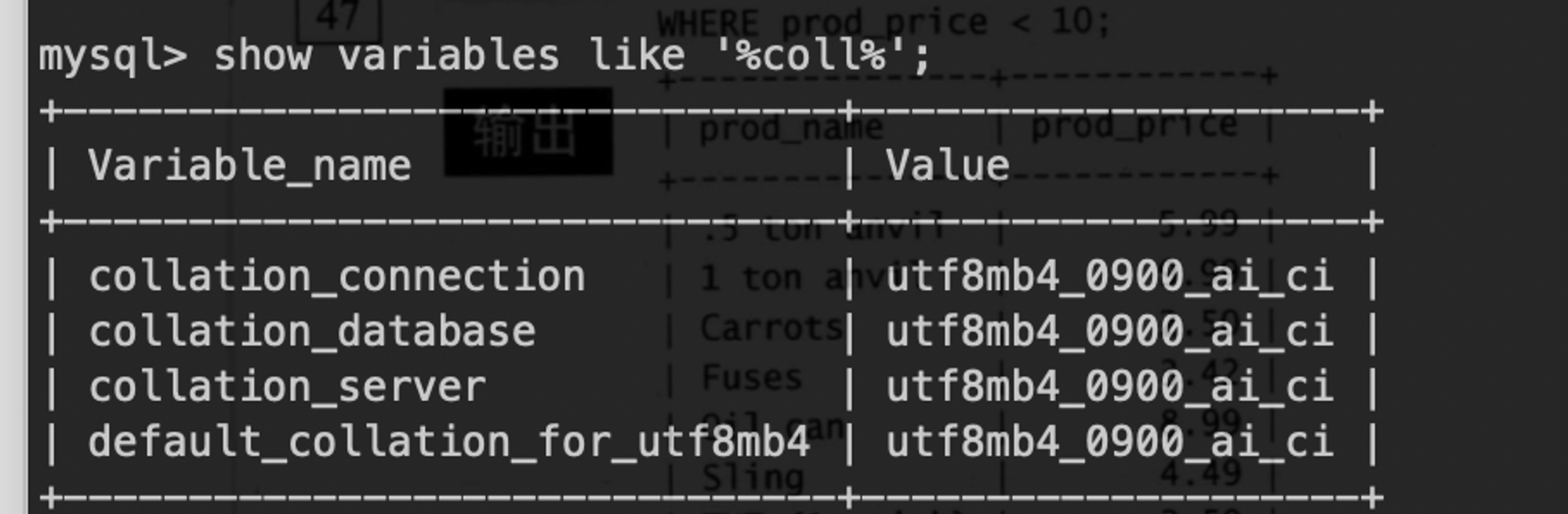 ### 1.3.1.组合数据过滤-组合where子句 - 定义:MySQL允许多个where子句,用AND或者OR子句方式使用 - 操作符(operator):用来联结或者改变WHERE子句中的子句关键字,也称为逻辑操作符(logical operator) **1.AND操作符** - 检索多个条件同时满足的行 ```sql #检索供应商1003制造并且价格小于等于10美元的产品.用AND关键字连接他们 mysql> select prod_id,prod_name,prod_price from products where vend_id = 1003 AND prod_price <=10; ``` **2.OR操作符** - 检索MySQL任一匹配一个条件的行 ```sql #检索制造商1002和1003的产品id,名字和价格 mysql> select vend_id,prod_id,prod_name,prod_price from products where vend_id = 1002 OR vend_id =1003; ``` **3.计算次序** - WHERE包含多个 AND和OR ```sql #操作符AND比OR具有更高的优先处理级别,这里执行顺序是 产品大于10美元并且id=1003 或者 1002的数据 mysql> select vend_id,prod_id,prod_name,prod_price from products where vend_id = 1002 OR vend_id =1003 AND prod_price>=10; #加上()确定操作符的分组,DBMS优先括号内条件 mysql> select vend_id,prod_id,prod_name,prod_price from products where (vend_id = 1002 OR vend_id =1003) AND prod_price>=10; ``` **4.IN操作符** - IN操作符制定条件分为,范围每个条件进行匹配,用逗号分隔的清单,枚举 - IN和OR具有相同功能,比起OR优点 - 没有索引情况下,IN执行效率比OR快很多(O(logn)和O(n)),有索引MySQL会优化执行计划基本一致 - IN可以包含其他SELECT语句,更加动态,业务尽量禁止 - IN更直观一些,计算次序容易管理 ```sql #检索供应商1002和1003制造的商品 mysql> SELECT prod_name,prod_price from products where vend_id in (1002,1003) order by prod_name; ``` **5.NOT操作符** - 功能:否定之后跟的任何条件 ```sql #列出除1002,1003之外所有供应商制造产品,这里用between and mysql> SELECT prod_name,prod_price from products where vend_id not in (1002,1003) order by prod_name; ``` ### 1.3.2.通配符进行过滤-LIKE - **已知过滤**:明确知道已知值进行检索。 - **未知过滤**(模糊搜索):知道一部分已知值从而进行相关条件检索需要和**通配符**进行配合构建**搜索模式** - **通配符**:用来匹配值一部分的特殊字符 - **搜索模式**(search pattern):由 已知值,通配符或者两者构成的搜索条件 - 必须使用LIKE 操作符 告诉MySQL搜索模式利用通配符而不是直接相等匹配 - **一般来说生产使用通配符情况很少** **1.% 通配符** - 代表字符出现任意次数(0,1,多个) - NULL值不能匹配 ```sql #找出所有以词 jet起头的产品, mysql> select prod_id,prod_name from products where prod_name like 'jet%'; #可以两端一起使用 搜索模式%anvil% 匹配任何位置包含文本anvil的值,生产禁止 OLTP mysql> select prod_id,prod_name from products where prod_name like '%anvil%'; ``` **2.下划线 _ 通配符** - 匹配单个字符(一个字符 不能多也不能少) ```sql mysql> select prod_id,prod_name from products where prod_name like '_ ton anvil'; ``` ### 1.3.3.正则表达式进行过滤 - MySQL仅支持正则中的很小一部分子集功能 - 生产业务一般不会使用正则 - 其余场景大家可以自行探索 ```sql #检索 prod_name包含文本1000的所有行 mysql> select prod_id,prod_name from products where prod_name REGEXP '1000' order by prod_name; #OR匹配 mysql> select prod_id,prod_name from products where prod_name REGEXP '1000|2000' order by prod_name; ``` ## 1.4.select函数-计算字段 - 存储表中数据一般不是业务直接使用的,需要检索出进行转换,计算或者格式化后的数据。 - 如果业务牛X,业务层可以全部实现(比如超高流量的核心流水库) QPS过1W/ - 要知道的总数,平均数或者其他计算 - 一个字段里面同时显示两个column_name(公司名+公司地址) ### 1.4.1.使用方式前置 **1.拼接字段-concat** - 讲多个字段的值拼接到一起,组成新计算列 ```sql CONCAT(str1,str2,…) #可以拼接符号,这里拼接了 vend_name,(,vend_country,)四个元素 mysql> select concat(vend_name,'(',vend_country,')') from vendors order by vend_name; #删除右侧多余空格 select concat(RTrim(vend_name),'(',RTrim(vend_country),')') from vendors order by vend_name; ``` **2.使用别名** - 别名(alias):是一个字段或者值得替换名, as 关键字 - 可以给新的计算列起名 - 也可以叫做导出列(derived column) ```sql #给新计算列起别名,SQL创建一个新的计算字段,到业务端显示也是如此。 mysql> select (concat(RTrim(vend_name),'(',RTrim(vend_country),')')) as vend_title from vendors order by vend_name; ``` ### 1.4.2.执行算数计算 ```sql #计算订单表中的物品总价 mysql> select prod_id,quantity,item_price,quantity*item_price as total_price from orderitems where order_num=20005; #MySQL支持其他操作符(+ - * /) ``` ## 1.5.分组查询-Group by AND HAVING ### [1.5.1.Group](http://1.5.1.Group) by - 什么是分组查询:查询结果按照1或者多个字段分组,字段值相同的为一组(按照某一列进行分类) - 特性 ```sql - 除聚集计算,每个SELECT语句列都要出现在group by中,不然会造成数值缺失 - NULL作为一个分组返回 - Group by出现在 where子句之后,order by 之前 - 先分组在聚合,没有聚合取每组第一条记录 ``` ```sql -- 举个例子 -- 提供返回供应商1003总共的产品数目 mysql> select count(*) as num_prods from products where vend_id = 1003; #1.返回每个供应商的产品数目 -- SELECT指定两个列 vend_id包含供应商ID,num_prods为聚合计算字段,group by 按照vend_id排序并分组数据,对每个vend_id的num_prods计算一次 mysql> select vend_id,count(*) as num_prods from products group by vend_id; #2.聚集函数group_concat(),每个供应商id的产品列表 mysql> select vend_id,group_concat(prod_name) as num_prods from products group by vend_id; ``` ### 1.5.2.过滤分组-Having - 用来分组查询后制定一些条件来输出查询结果 - having的作用和where一样,但having只能用于group by - 和Where的区别 ```sql 1.having是在分组后对数据进行过滤,where是在分组前对数据进行过滤 2.having后面可以使用分组函数(统计函数),where后面不可以使用分组函数 3.where没有分组概念,过滤的是行,having是对分组后的数据处理 4.having支持所有where的操作符 ``` - 举例 ```sql #1.按照顾客id分组,计算每个顾客下单的数量,并筛选下单多余2个的顾客数据. mysql> select cust_id,count(*) as orders from orders group by cust_id having count(*) >=2; #from orders-->cust_id-->select count(*)-->取gorup by 列作为第一个值,-->having(下了两单的) #2.和Where语句搭配使用,选出价格大于10和生产产品数量多余2件的供应商.() mysql> select vend_id,count(*) as num_prods from products where prod_price >=10 group by vend_id having count(*) >=2; -- from --->where >10--->group by id(分组)-->select count(*)聚合-->select vend_id-->having·选出 大于2件的 ``` - Group by和 order by的区别 ```sql order by 1.对column 数据进行排序 2.任意列都可以使用 3.不一定必须出现 group by 1.对column进行分组 2.SELECT中必须跟group by选择的列完全一致. 3.与聚集函数一起使用,必须出现,除非只计算count(*)这种情况 ``` - 业务SQL中 group_by与order_by通常一起出现 ```sql #1.按照订单号分组,得出总价大于等于50元的订单的订单号和价格,并对价格排序 mysql> select order_num,SUM(quantity*item_price) as total_price from orderitems group by order_num having sum(quantity*item_price)>=50 order by total_price; ``` 单条SQL-SELECT语句顺序 ```sql 子句 解释 是否必须 SELECT 选择的列 是 FROM 检索数据表 从表中选数据 WHERE ``` 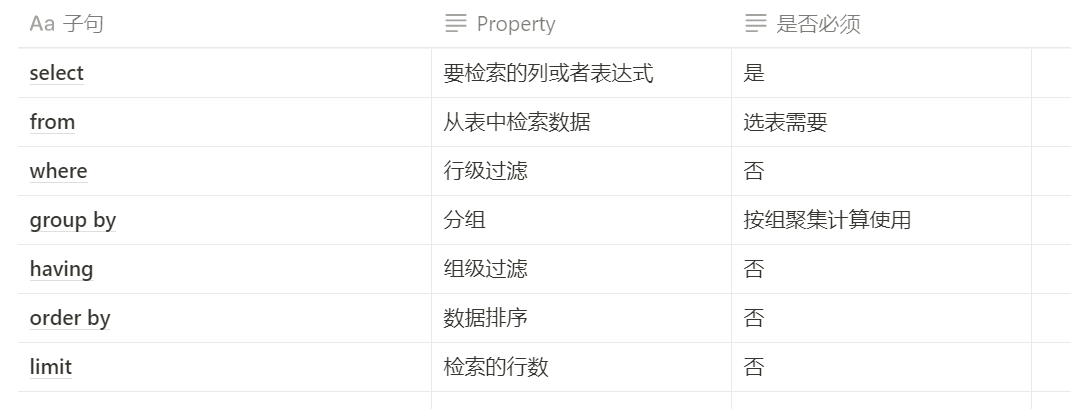 ## 1.6.使用子查询(subquery) - 概念:子查询指一个**查询语句**嵌套在另一个查询语句内的查询,可以是多个 - 分类 - 标量子查询 - 关联子查询 ### 1.6.1.标量子查询(过滤) ```sql #1.列出订购物品TNT2(orders)的所有客户(customers), -- 客户信息在customers中 -- 订单信息在orders中 -- 相信每个订单信息在orderitems -- 步骤 (1)检索(找到)包含TNT2订单编号 select order_num from orderitems where prod_id='TNT2'; (2)检索(1)中订单编号下的所有客户ID select cust_id from orders where order_num in (20005,20007); (3)讲(1)(2)组合,先执行子查询返回订单号,然后值传递给外面where语句 SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id='TNT2'); (3)检索前一步骤返回的所有客户的ID信息 select cust_name,cust_contact from customers where cust_id in (10001,10004); (4)讲3带入In结果中 SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id='TNT2')); ``` ### 1.6.2.关联子查询 - 涉及外部查询的子查询 - 关联子查询 - 首先依靠子查询中的关联语句,从主查询中选取关联属性的第一个值,进入子查询中, - 然后将子查询结果返回主查询,依次类推,直到主查询中关联属性的值选取完毕。 - 额外:还可以出现在update,insert,delete中 ```sql #1.找到customers中每个客户订单总数(订单与客户ID存在orders中) -- SQL对每个客户,统计orders表中订单总数(counts) SELECT cust_name, cust_state, (SELECT count(*) AS orders FROM orders WHERE orders.cust_id = customers.cust_id) AS orders -- order.cust_id=10001 FROM customers ORDER BY cust_name; -- 执行步骤 (1)orders.cust_id = customers.cust_id确定关联属性 (2)从主查询中选取关联属性第一个值,customers.cust_id进入子查询,此时变成 SELECT count(*) AS orders FROM orders where orders !=2 ; (3)执行(2)子查询,返回主查询进行结果筛选,符合条件的select 检索出此行数据 (4)取customers.cust_id第二值 依次类推. ``` 关于子查询 ```sql 1、多表查询时要使用完全限定表名 A.a B.b 2、业务使用子查询不是最优方案可以让业务进行优化 3、子查询可以用在 select 与from 之间,也可以用在where 子句后 5、查询顺序从内到外 ``` # 2.表连接-join(重要) > join 是SELECT执行最重要的操作. - ER图:实体-联系图(Entity Relationship Diagram),现实世界的概念模型 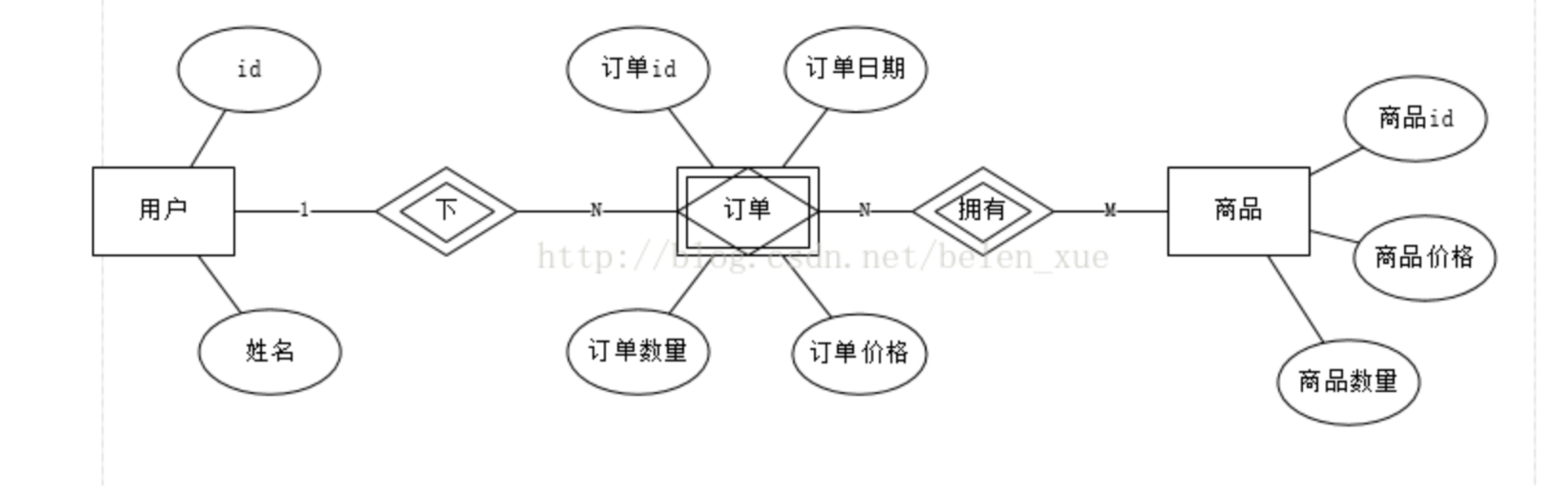 - 关系表:把信息拆成多个表,一类数据一个表,表之间通过关系互相关联,放在一张表里面会出现非常多的冗余数据. - join: - 一条select 存储在多张表的数据检索出来 - 相当于两张表横向拼接在一起,第一个表的每一行与第二个表每一行配对,根据条件过滤 - join分为内连接,外连接,右连接,左连接,自然连接,CROSS JOIN - 驱动表选择原则:在对最终结果集没影响的前提下,优先选择结果集最少的那张表作为驱动表 - 未使用索引关联:Simple Nested-Loop join 和Block Nested-Loop join两种算法 - SNLJ,简单嵌套循环连接: 外层表行数*内层表行数 - BNLJ,缓存块嵌套循环连接: 缓存多条数据,参与查询的列缓存到Join Buffer 里,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了内层循环的次数 - join buffer:缓存驱动表的列 ## 2.1.创建联结 - 示例 ```sql #两个表通过where 子句联结,匹配两张表vend_id相同的列. SELECT vend_name, prod_name, prod_price FROM vendors,products WHERE vendors.vend_id = products.vend_id ORDER BY vend_name,prod_name; -- 执行步骤 (1)首先两张表进行笛卡尔积配对(第一个表行数*第二个表行数),通过vend_id列 联结在一起 select * FROM vendors,products WHERE vendors.vend_id = products.vend_id ; (2)select选出vend_name,prod_name,prod_price 从1的结果集中 (3)order by排序 ``` ## 2.2.内连接 - 第二种格式,也是我们通常使用的,将两张表关联起来的数据连接后返回 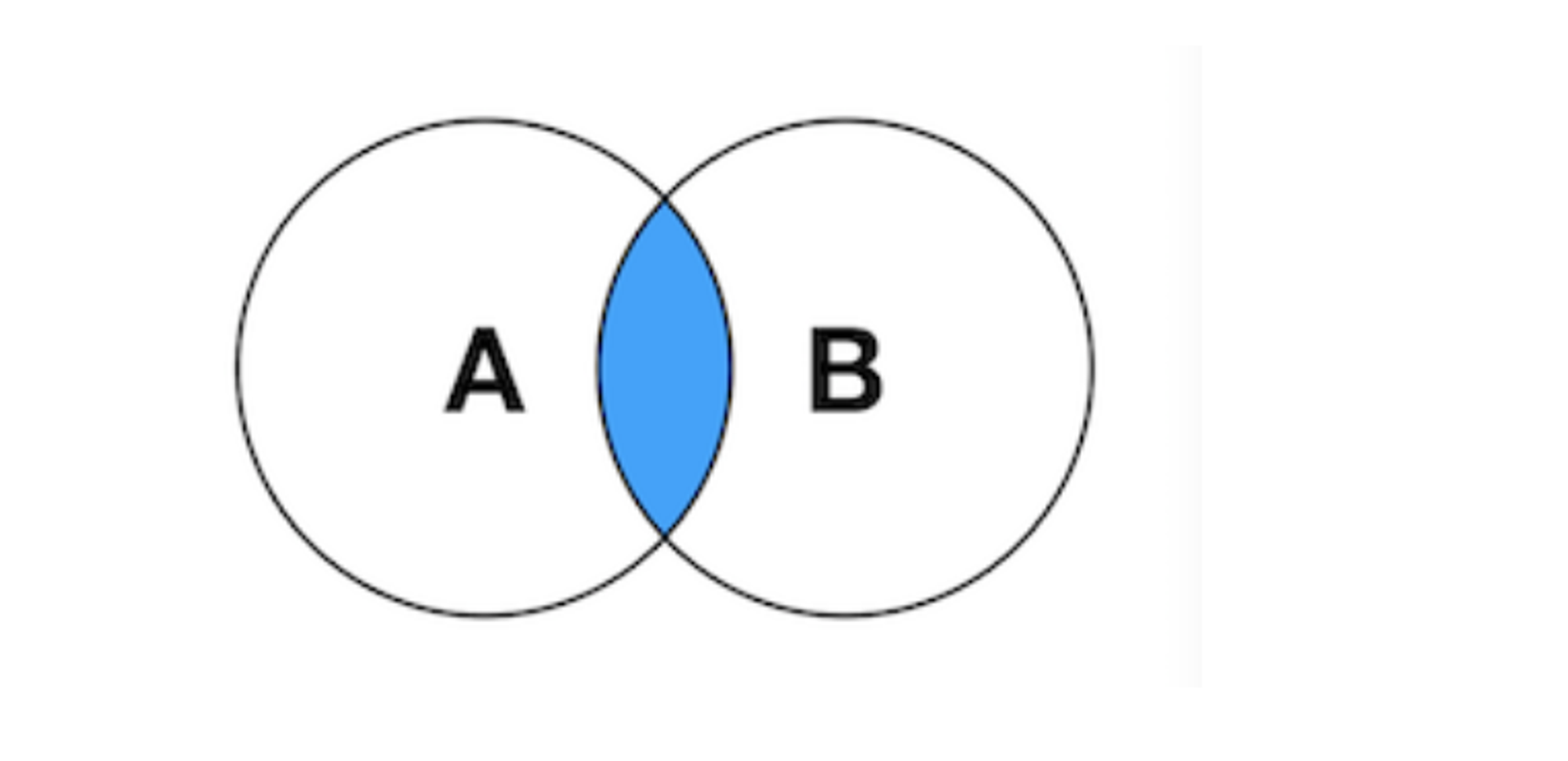 ```sql #可连接多个表 select col1,col2 from a inner join b on a.col = b.col ; SELECT vend_name, prod_name, prod_price FROM vendors INNER JOIN products ON vendors.vend_id = products.vend_id; ``` ## 2.3.自连接 - 两个相同的表进行join - 注意使用别名处理两张表 ```sql #查找产品ID为DTNTR生产厂商,生产的其他物品id和name #1.子查询 select prod_id,prod_name from products where vend_id = (select vend_id from products where prod_id = 'DTNTR') #2.自连接(效率比子查询快) select p1.prod_id,p2.prod_name from products p1 inner join products p2 on p1.vend_id = p2.vend_id where p1.prod_id='DTNTR'; ``` ## 2.4.外连接 - 包含没有关联行的数据,包含左连接,右连接,全连接 - 必须只用RIGHT或者LEFT指定包含所有行的表,outer可以省略 - 左连接 - 左连接查询会返回左表(表 A)中所有记录,不管右表(表 B)中有没有关联的数据。 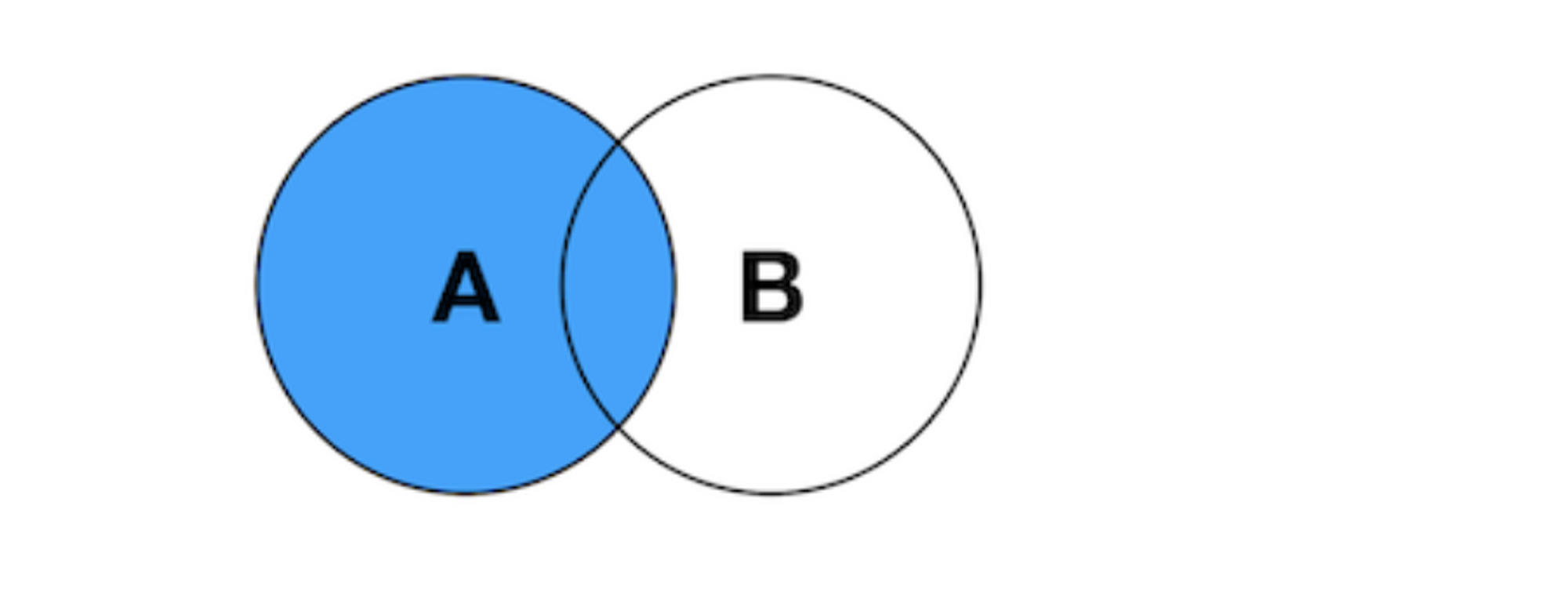 ```sql #1.检索所有客户,包括没下订单的客户 SELECT customers.cust_id, orders.order_num FROM customers left outer JOIN orders ON customers.cust_id = orders.cust_id; ``` - 右连接 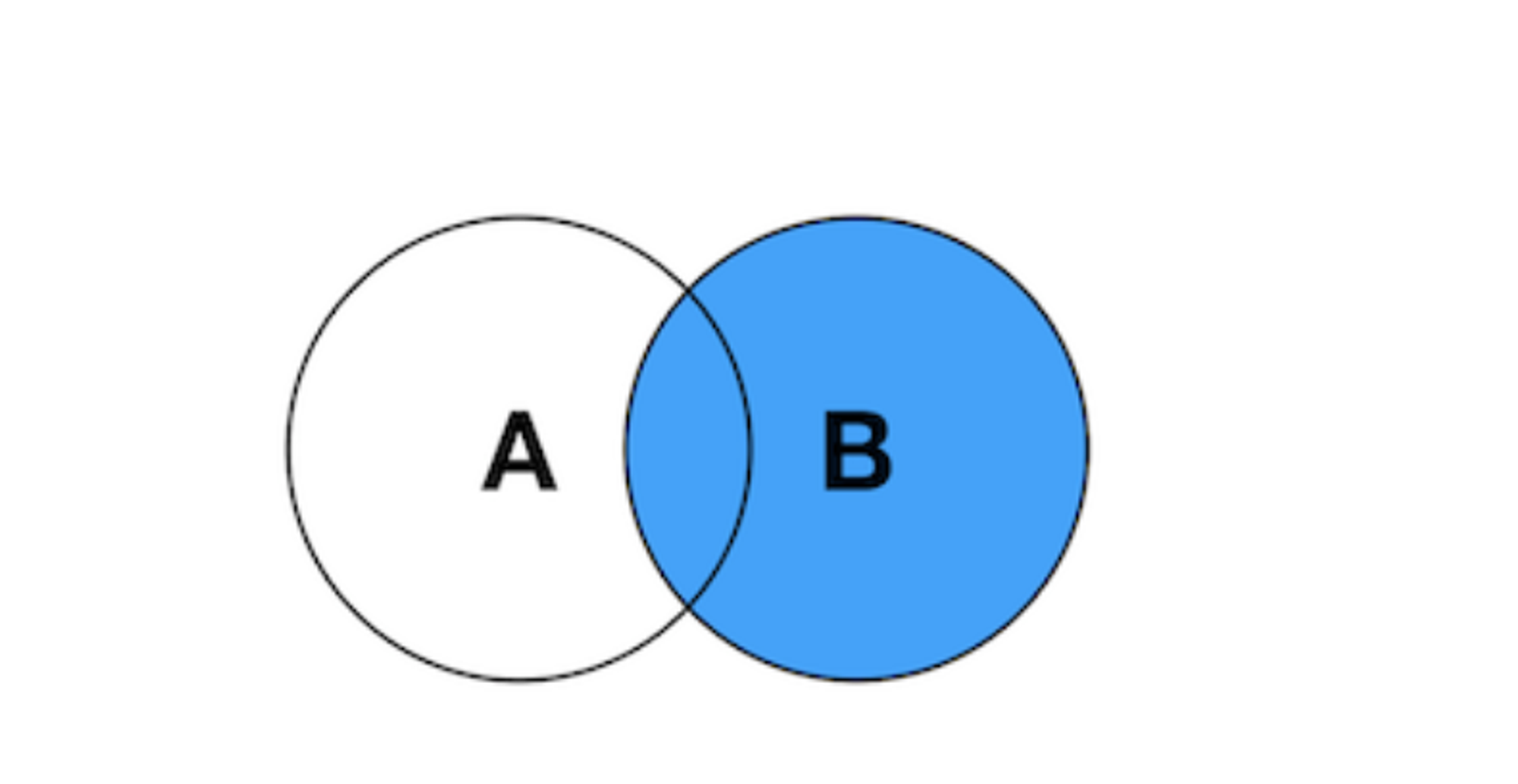 ```sql SELECT customers.cust_id, orders.order_num FROM customers right outer JOIN orders ON customers.cust_id = orders.cust_id; ``` - 全连接:返回左右表里的所有记录(MySQL默认不支持) - all outer join ```sql #一种方法 SELECT customers.cust_id,orders.order_num FROM customers,orders; #左外连接+ union+右外连接 SELECT customers.cust_id, orders.order_num FROM customers right outer JOIN orders ON customers.cust_id = orders.cust_id UNION SELECT customers.cust_id, orders.order_num FROM customers left outer JOIN orders ON customers.cust_id = orders.cust_id; ``` # 笛卡尔乘积 (A*B) 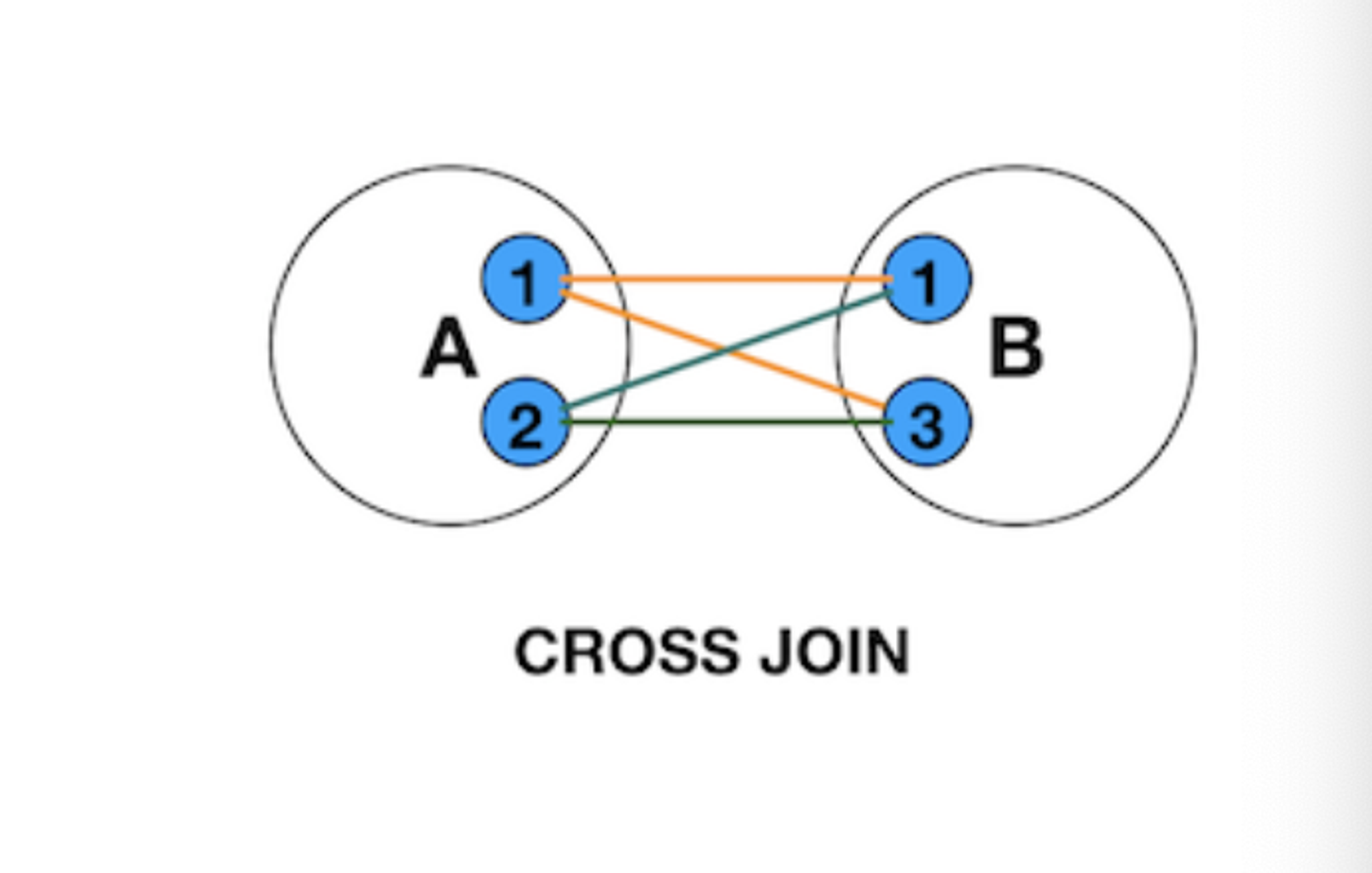 ```sql SELECT customers.cust_id, orders.order_num FROM customers cross JOIN orders; ``` - 延伸用法:   # 3.组合查询-union - 概念:执行多条select语句作为单个结果集返回. - UNION中的每个SELECT语句必须具有相同的列数 - 这些列的数据类型必须兼容:类型不必完全相同,但是必须可以隐式转换。 - 每个SELECT语句中的列也必须以相同的顺序排列 ```sql 语法1:检索不同的值 SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2; 语法2:检索所有值 SELECT column_name(s) FROM table1 UNION ALL SELECT column_name(s) FROM table2; #1.union与union all select vend_id,prod_id,prod_price from products where prod_price <=5 union select vend_id,prod_id,prod_price from products where vend_id in (1001,1002); ``` - order by 排序使用 - 只能使用一条子句 - 必须出现在最后一条select后面 ```sql #1.union与union all select vend_id,prod_id,prod_price from products where prod_price <=5 union select vend_id,prod_id,prod_price from products where vend_id in (1001,1002) order by vend_id,prod_price; ``` - 全文本搜索(略):ES或者monodb更合适 ```sql longtext 几百字 ,where 'abc' ``` - 虚拟表: - 就是实际上并不存在(物理上不存在),但是逻辑上存在 - 分类 - 临时表 - 内存表 - 视图 ```sql #1.临时表,建立在系统临时文件夹中的表。 特性: (1)临时表的数据和表结构都储存在内存之中,退出时,其所占的空间会自动被释放。(如果太大 则会在 /tmp 目录下物理文件) (2)当前连接可见,当这个连接关闭的时候,会自动drop (3)同一个query语句中,你只能查找一次临时表 CREATE TEMPORARY TABLE tmp_table SELECT * FROM table_name ``` from->on->join->where->group by(开始使用select中的别名,后面的语句中都可以使用别名)->sum、count、max、avg->having->select->distinct->order by->limit - SQL执行顺利-内部逻辑 ```sql 从这个顺序中我们不难发现,所有的 查询语句都是从from开始执行的,在执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。 第一步:首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表 vt1(选择相对小的表做基础表)。 第二步:接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2 。 第三步:如果是outer join 那么这一步就将添加外部行,left outer jion 就把左表在第二步中过滤的添加进来,如果是right outer join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3 。 第四步:如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3。 第五步:应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4, 第六步:group by 子句将中的唯一的值组合成为一组,得到虚拟表vt5。 第七步:应用cube或者4rollup选项,为vt5生成超组,生成vt6. 第八步:应用having筛选器,生成vt7。having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。 第九步:处理select子句。将vt7中的在select中出现的列筛选出来。生成vt8. 第十步:应用distinct子句,vt8中移除相同的行,生成vt9。 第十一步:应用order by子句。按照order_by_condition排序vt9,此时返回的一个游标,而不是虚拟表。sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式。排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,最后,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。 第十二步:应用top选项。此时才返回结果给请求者即用户。 ```
李延召
2024年3月19日 09:09
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码