DBA专题
DBA授课
DBA公开课
DBA训练营三天
01.Mysql基础入门-数据库简介
02.Mysql基础入门-部署与管理体系
03.MySQL主流版本版本特性与部署安装
04.Mysql-基础入门-用户与权限
05 MySQL-SQL基础2
06 SQL高级开发-函数
07 MySQL-SQL高级处理
08 SQL练习 作业
09 数据库高级开发2
10 Mysql基础入门-索引
11 Mysql之InnoDB引擎架构与体系结构
12 Mysql之InnoDB存储引擎
13 Mysql之日志管理
14 Mysql备份,恢复与迁移
15 主从复制的作用及重要性
16 Mysql Binlog Event详解
17 Mysql 主从复制
18 MySQL主从复制延时优化及监控故障处理
19 MySQL主从复制企业级场景解析
20 MySql主从复制搭建
21 MySQL高可用-技术方案选型
22 MySQL高可用-MHA(原理篇)
23 MySQL MHA实验
24 MySQL MGR
25 部署MySQL InnoDB Cluster
26 MySQL Cluster(MGR)
27 MySQL ProxySQL中间件
相信可能就有无限可能
-
+
首页
14 Mysql备份,恢复与迁移
# 1.MySQL备份与工具介绍 ## 1.0.造个数 ```sql #安装 shell> wget https://github.com/akopytov/sysbench/archive/1.0.zip -O "sysbench-1.0.zip" shell> unzip sysbench-1.0.zip shell> cd sysbench-1.0 shell> yum install automake libtool -y shell> ./autogen.sh shell> ./configure --prefix=/usr/local/sysbench/ --with-mysql --with-mysql-includes=/usr/local/mysql/include --with-mysql-libs=/usr/local/mysql/lib shell> make & make install shell> /usr/local/sysbench/bin/sysbench --version #如果提示错误 /usr/local/sysbench/bin/sysbench: error while loading shared libraries: libmysqlclient.so.20: cannot open shared object file: No such file or directory shell>export LD_LIBRARY_PATH=/usr/local/mysql/lib/ #你的mysql-lib库 #利用压测工具造数 mysqladmin create sbtest -uqianlong -p123456 -h127.0.0.1 测试准备: 20个并发连接,10张表 每个表填充1000W条数据 最大请求时间120s /usr/local/sysbench/bin/sysbench /chj/class/dowland/sysbench-1.0/src/lua/oltp_read_write.lua --db-driver=mysql --mysql-host=172.21.188.37 --mysql-port=3306 --mysql-user=qianlong --mysql-password=123456 --mysql-db=sbtest --tables=10 --table-size=10000000 --threads=20 --time=600 --report-interval=10 prepare ``` ```sql #创建用户 CREATE USER 'dba_backup'@'%'IDENTIFIED BY "dba_backUP123"; GRANT all ON *.* TO 'dba_backup'@'%' ; #备份权限说明 逻辑备份工具:mysqldump,mysqlpump,mydumper等等 权限:SELECT 作用:查询表中数据 权限:SHOW VIEW 作用:查看创建视图的语句 权限:TRIGGER 作用:备份触发器 权限:EVENT 作用:备份事件(定时任务) 权限:lock tables 作用:备份时锁表,产生一致性备份 权限:reload 作用:show processlist,show engine innodb status,查 看线程,查看引擎状态 权限:replication client作用: show master/slave status;查看事务日志执行状态与位置 show binary logs;查看当前保存的事务日志列表与文件大小 权限:super 作用:关闭线程,不受最大连接线程数限制的VIP连接通道,阻断刷新线程的命 令,不受离线模式影响 #MySQL5.7 CREATE USER 'dba_backup'@'localhost'IDENTIFIED BY "dba_backUP123"; grant reload,lock tables,replication client,create tablespace,process,supe r,select,event,trigger,show view on *.* to 'dba_backup'@'localhost'; #MySQL8.0 CREATE USER 'dba_backup'@'localhost' IDENTIFIED WITH mysql_native_password BY "dba_backUP123"; grant BACKUP_ADMIN,PROCESS,select,RELOAD, LOCK TABLES, replication client on *.* to 'dba_backup'@'localhost'; ``` ## 1.1.备份工作介绍 ```sql #备份的必要性 - 数据库是企业核心资产,备份在发生故障和灾害时候,能够保存重要核心资产-数据 - 数据库的备份是一个长期过程,恢复在事故后发生,恢复看成备份的逆过程。 - 数据备份与恢复场景(仅生产实用场景) 1. 数据库实例损坏(数据不可用) 2. 数据实例节点服务器磁盘损坏(binlog备份或者主从) 3. 业务系统逻辑错乱导致数据错乱,恢复点位+数据清洗(binlog2sql或备份+binlog) 4. 人为删库,删表.(开发人员只有增删改查,业务开发leader,create drop) 5. 主从搭建 6. 数据库升级 7. MySQL集群拆分(业务拆分) - DBA备份要做什么 - 设计备份策略 - 全量备份一天(物理备份)+增量备份6天+binlog(弃用) - mysql集群轻量(一个实例1-2个库) 物理全备份(逻辑备份)+binlog(主从) - 定期故障演练与故障恢复 - 周四有一次小的故障演练 - 测试自动化脚本和备份是否可用 - 恢复机上做 - 一个季度有大的故障演练 - 多部门联合(混沌工程:破坏).B端业务(对公司内部) C端业务(对用户) - 确保多集群备份任务执行成功率 - 备份时间: 00:00-08:00 - 1-30套集群:一个备份节点(串行化跑10个备份任务) - 30-1000:并行化执行备份 - 每个备份节点备份实例数据,备份结果反馈回去 - 传输到存储服务器 - 1000套实例以上(一个服务器上5-15实例mysql) - 中心机备份任务分发备份任务到任务节点 - 每个任务节点备份数据,备份结果反馈回去 - 记录每天备份结果 - 处理失败备份 - 调整备份时间 - 压缩存储文件 - 上传分布式存储(HDFS,对象存储) #备份场景 1. 冷备:数据库完全停止服务进行完整数据库备份,基本不存在冷备场景 1.1.优点: - 非常快(只需拷贝物理文件) - 轻易归档与恢复冷备时间点位,物理手段维护了数据一致性 - 维护难度低 1.2.缺点 - 只能提供到“某一时间点上”的恢复。 - 数据库备份必须是关闭状态(现在基本无此线上业务场景) - 备份与恢复粒度较粗,只能按照实例级别恢复 2. 热备:数据库实例不停机,捕获一致性点位(某一时刻(事务)的数据库数据)+增量数据(MySQL通常为Binlog) 2.1.优点: - 不中断数据库服务,备份与恢复均可在实例运行时进行 - 备份粒度和恢复粒度到表级别甚至where条件级别 - 可达到事件级别恢复(某一事件点位) 2.2.需要考虑之处 - 要考虑备份时间与备份流量对线上业务影响,备份和恢复期间对IO等系统资源消耗情况的把控,是否可以做到限速. - 备份失败则恢复不可用 - 维护难度高,多集群状态下要有完整的备份工具与备份逻辑支持 - 备份策略与制定要符合公司业务场景,如何灵活地设置备份策略,比如备份周期和备份时间点的选择,是否可以在从库备份,备份上传到何处,选择什么压缩方式? - 备份是否成功,如果失败如何重试备份任务. - 备份数据定期清理 - 最近30天 - 每个月保留一天,近三年 - 核心业务:永久保留(每天) - 服务器(30T,RAID10)存放仅30天,所有数据都要上传分布式存储HDFS. 3.双活(Active-Active):两个数据中心.一主+一个备份.为了防止整个数据中心(IDC发生灾害或者网络整体切断),直接影响C端用户体验而建设(典型场景就是银行) - 主数据中心用来承担用户的业务 - 备份数据中心是为了备份主数据中心的数据,配置等 - 一个完整的双活,包括基础设施、中间件、单元化服务与数据等各个方面 - 同城双活,异地双活 #备份文件与方式 1.逻辑备份 - 概念:将数据备份成SQL语句组成的文件(数据的在Mysql中的schema逻辑结构) - 组成:逻辑数据库结构(Create Database,Create Table)+数据(INSERT语句或分隔文本文件) - 特点: - 备份通过查询MySQL服务器或者数据库表结构和数据实现 - 优点: - 恢复数据简单 - 灵活性高(库表级别) - 与存储引擎无关,高度可移植性 - 避免数据损坏 - 缺点 - 备份与恢复数据较慢 - 备份文件比物理备份大很多 - 对实例影响比物理备份大 - 工具或者文本文件 - select..INTO OUTFILE/load data(大量数据灵活导入与导出) - mysqldump(常规备份手段) - mydumper+loader(常规备份手段) - mysqlpump(不常用) 2.物理备份 2.1.快照备份 - 概念:所有数据放在同一个分区,针对分区进行快照备份 - 特点:只能存储在本地磁盘,本地磁盘故障,则快照备份数据丢失 - 归纳:属于基础服务运维人员手段,DBA不用 2.2.工具备份(这里仅讨论InnoDB存储引擎) - 概念:利用InnoDB存储引擎的crash-recovery功能,先复制物理文件,在根据log进行redo和undo恢复,保证数据一致性 - 特点:备份恢复速度快,比逻辑备份更安全,一般做实例级别备份 CMDB(元信息管理平台),适合30G以上实力备份恢复。 - 工具 - 生产中仅推荐Percona的xtrabackup(2.3以上版本) - MySQL Enterprise Backup - mysqlbackup - xtarbackup ``` # 2.MySQL逻辑备份工具与方法 ## 2.1.mysqldump简介与参数介绍 ### 2.1.1.简介 ```sql 1.简介 - 最广泛的mysql官方备份工具,逻辑备份出SQL语句 - 支持远程备份 - 当数据为浮点类型时,会出现精度丢失 - 备份的过程是串行化的,不支持并行备份 - 也可以导出CSV,分割文本形式,但是基本不用(给开发,测试) - 适用于100G以下实例(现在50G一下,50G以上都用物理备份),备份快,恢复慢(一般是备份的5-10倍时间) - 备份方式非常灵活 - 一致性备份和非一致性备份(数据库备份时候整体是否在一个快照状态,InnoDB MVCC) - 备份整个实例,单个库,单个表,甚至某个表的where条件筛选数据 - 备份表结构或者仅备份数据 2.需求权限 备份对象 权限 table SELECT view SHOW VIEW trigger TRIGGER event EVENT 储存过程、函数 SELECT mysql.proc 转储用户 SELECT "mysql"系统库 (无-single-transaction) LOCK TABLES 3.使用限制 (1)默认不备份INFORMATION_SCHEMA, performance_schema, sys,需要显示指定 (2)mysqldump不会转储InnoDB CREATE TABLESPACE语句。 (3)mysqldump不会备份 NDB cluster ndbinfo信息数据库。 (4)在启用了GTID的数据库中使用mysqldump,备份GTID信息,无法恢复到没有启用GTID的数据库中。 (5)mysqldump是单线程,当数据量大时备份时间长,在备份过程中对非事务表(MyISAM)长期锁表对业务造成影响(SQL形式的备份数据恢复时间也较长)。 (6)参数 --lock-all-tables,--flush-privileges分别会在备份时进行 flush tables 和 flush privileges 操作,会产生GTID,备份从库时请注意 (7)在对数据库进行完全备份前,需要收集数据库相关信息(存储引擎、字符集等),确保备份内容完整,以下为收集语句: -- 查看表相关信息 select table_schema,table_name,table_collation,engine,table_rows from information_schema.tables where table_schema NOT IN ('information_schema' , 'sys', 'mysql', 'performance_schema'); mysql> select table_schema,table_name,table_collation,engine,table_rows -> from information_schema.tables -> where table_schema NOT IN ('information_schema' , 'sys', 'mysql', 'performance_schema'); +--------------+------------+--------------------+--------+------------+ | TABLE_SCHEMA | TABLE_NAME | TABLE_COLLATION | ENGINE | TABLE_ROWS | +--------------+------------+--------------------+--------+------------+ | aa | a1 | utf8mb4_0900_ai_ci | InnoDB | 0 | | school | Course | utf8mb4_0900_ai_ci | InnoDB | 2 | | school | SC | utf8mb4_0900_ai_ci | InnoDB | 18 | | school | Student | utf8mb4_0900_ai_ci | InnoDB | 12 | | school | Teacher | utf8mb4_0900_ai_ci | InnoDB | 2 | | school | app_user | utf8mb3_general_ci | InnoDB | 993126 | | test | t1 | utf8mb4_0900_ai_ci | InnoDB | 16 | +--------------+------------+--------------------+--------+------------+ 7 rows in set (0.02 sec) -- 查看是否存在存储过程、触发器、调度事件等 select count(*) from information_schema.events; select count(*) from information_schema.routines; select count(*) from information_schema.triggers; -- 查看字符集信息 show variables like 'character%'; (8)mysqldump在执行-all-databases不会备份mysql.proc下的系统自身的存储过程,导致导入到新机器后,部分sys下的视图没法正常使用;这是一个BUG,并且只存在于MySQL5.7。 4.备份导入(恢复)参前注意事项 (1)参数检查 autocommit:必须开启,不然会导致数据库hang住 wait_timeout \ interactive_timeout:建议调大,设置过小,且导入时间长,会导致还没导入完,会话超时断开连接,导致任务失败。 set session wait_timeout=28800; \ set session interactive_timeout=28800; max_allowed_packet = 128M #防止包过大而失败 mysqldump: Error 2020: Got packet bigger than 'max_allowed_packet' bytes when dumping table `operlog` at row: 264227 mysqldump [xxxx] --max_allowed_packet=256M > dump.sql mysql [xxxx] --max_allowed_packet=256M < dump.sql (2)检查SQL文件中所要DROP 的表是否是自己预期内的 less all_db_with_data.sql | grep -E "^DROP TABLE IF EXISTS|^USE" (3)使用PV工具监控文件导入过程,精准估算剩余时间及完成时间 #参数说明: #-W:在需要密码输入时有用,可等待密码输出完成,再开启监控进度条 #-L:限流,将传输限制在每秒最大字节的范围内(大小可自定义,单位可变) shell> pv -W -L 2M all_db_with_data.sql | mysql -uops -p -h -P Enter password: 588MiB 0:04:54 [ 2MiB/s] [======================================================>] 100% 3.参数与命令行格式 mysqldump --help mysqldump [参数] 数据库名 [表名] > /backup/库名_202111051106/库名.sql ``` - 与mysqlpump的一些变化  ### 2.1.2.参数 [1.](http://1.Ss)连接参数 ```sql -u 用户名 -p, --password 密码 -P, --port 端口 -h, --host 网址 ``` 2.DDL参数 ```sql 1.--add-drop-database default: false 在创建每个数据库语句之前编写一个DROP(if exists)数据库语句. 2.--add-drop-table default:true 在创建每个表前添加一个 DROP(if exists) table 语句 ----【体现在导入的SQL文件中】 3.--add-drop-trigger default:false 在每个创建触发器语句之前编写一个DROP触发器语句。 4.--all-tablespaces , -Y default:false 将创建NDB表使用的任何表空间所需的所有SQL语句添加到表dump文件中。在mysqldump的输出中没有包含此信息。这个选项目前只与NDB集群表相关,MySQL 5.7不支持NDB集群表。 5.--no-create-db , -n default:false 如果给定“--databases”或“--all-databases”选项,则禁止输出中包含CREATE DATABASE语句。 如果未指定 -B 或 -A 选项,则输出中也没有 CREATE DATABASE 语句。 6.--no-create-info , -t default:false 不导出表结构:无 create table 语句。 但是此选项可以导出创建日志文件组或表空间的语句;您可以为此使用--no-tablespaces选项来禁止导出。 7.--replace default:false 用replace 替换SQL文件中的 insert 8.--force, -f default:false 忽略所有error,此选项比--ignore-error 优先级高。 9.--default-character-set=charset_name 使用charset_name作为默认字符集,mysqldump默认使用utf8. ``` 3.Replication参数 ```sql 1.--apply-slave-statements 对使用--dump-slave选项生成的SQL文件中,会在change master to 语句之前添加 stop slave 语句,并在输出末尾添加 start slave 语句。 2.--delete-master-logs 在主复制服务器上,执行完dump操作之后,会向服务器发送 PURGE BINARY LOGS 语句清除binlog。此选项自动启用--master-data 3.--dump-slave 会在dump后的SQL文件中,添加 change master to 语句,该语句指定被转储从的binlog文件名和位置。 从SHOW SLAVE STATUS输出中读取Relay_Master_Log_File和Exec_Master_Log_Pos的值,分别用于MASTER_LOG_FILE和MASTER_LOG_POS。这些是主服务器的文件名和位置,从服务器开始复制。 4.--master-data dump输出包含CHANGE MASTER TO语句,标记dump源的二进制日志坐标 值默认1,语句不会被写成注释并且在dump被载入时生效。 值默认2,CHANGE MASTER TO 语句会被写成一个SQL comment(注释),从而只提供信息; 5.--set-gtid-purged=ON/OFF 默认ON,备份文件最后.SET @@GLOBAL.GTID_PURGED='xx';执行,跳过主库已经执行的事务。 --set-gtid-purged=OFF,不强行指定跳过. #更应该在构建主从主动指定 ``` 4.Format参数 ```sql 1.--hex-blob 使用十六进制表示法转储二进制列 2.--xml 转储为xml格式 ``` 5.Filtering参数 ```sql 1.--all-databases , -A dump 所有数据库。 2.-database ,-B dump 指定数据库 ,可以指定一个或多个。 3.--tables dump 多个表mysqldump将该选项后面的所有名称参数都视为表名。 4.--events ,-E dump 服务器事件。须有event权限。 5.--ignore-table=db_name.tal_name 不dump给定的表,必须使用数据库名和表名指定给定的表。若要忽略多个表,请多次使用此选项。这个选项也可以用来忽略视图。 6.--no-data , -d 不导出数据 7.--triggers 导出表的触发器,默认启动。可以用 --skip-triggers 禁用。 8.--where='' , -w '' 只dump由where选择的行,如果条件中包含特殊字符,须在条件周围加上引号。 9.--insert-ignore 出现主键重复但使用了ignore则错误被忽略,数据不变。 10.--opt 提供了快速dump操作,默认开启。可通过 --skip-opt 关闭。 11.--add-drop-database 每个数据库创建之前添加drop数据库语句。 12.--add-drop-table 每个数据表创建之前添加drop数据表语句。(默认不指定为on,使用--skip-add-drop-table取消选项) 13.--no-create-info, -t 只导出数据,而不添加CREATE TABLE 语句。 ``` 6.Transactional参数 ```sql 1.--flush-logs , -F 在开始dump前,flush 一个新的binlog file。适用于逻辑备份恢复方便增量备份 2.--single-transaction #重要 innodb表不锁表和行,形成一致性快照。 3.--compact 优化备份文件。此选项启用-skip-add-drop-table、-skip-add-locks、-skip-comments、-skip-disable-keys和-skip-set-charset选项,禁用。 4.--fields-terminated-by 导出文件中忽略给定字段。与--tab选项一起使用,不能用于--databases和--all-databases选项 --fields-enclosed-by 输出文件中的各个字段用给定字符包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项 --fields-optionally-enclosed-by 输出文件中的各个字段用给定字符选择性包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项 --fields-escaped-by 输出文件中的各个字段忽略给定字符。与--tab选项一起使用,不能用于--databases和--all-databases选项 输出文件的每行用给定字符串划分。 --lines-terminated-by ``` ### 2.1.3.mysqldump备份场景 1.非一致性备份与一致性备份 - 非一致性备份 ```sql 备份命令: mysqldump -uroot -p -h -P3306 trsen > /data/backup/user_`date +%Y%d%m`_0.sql 原理解析(仅从备份逻辑看) 0.连接数据库建立connect 1.获取当前GTID信息 2.查看需要备份的DB和table 3.对表加read lock 4.show create table 备份表结构和数据(循环至整个DB表备份结束) 5.释放read lock 缺陷: 1.备份数据不一致 2.备份锁表时间时长和备份内容成正比 3.适合非事务引擎的一致性备份 生产不可用,这种在备份对表加锁,备份完释放,叫做温备 ``` 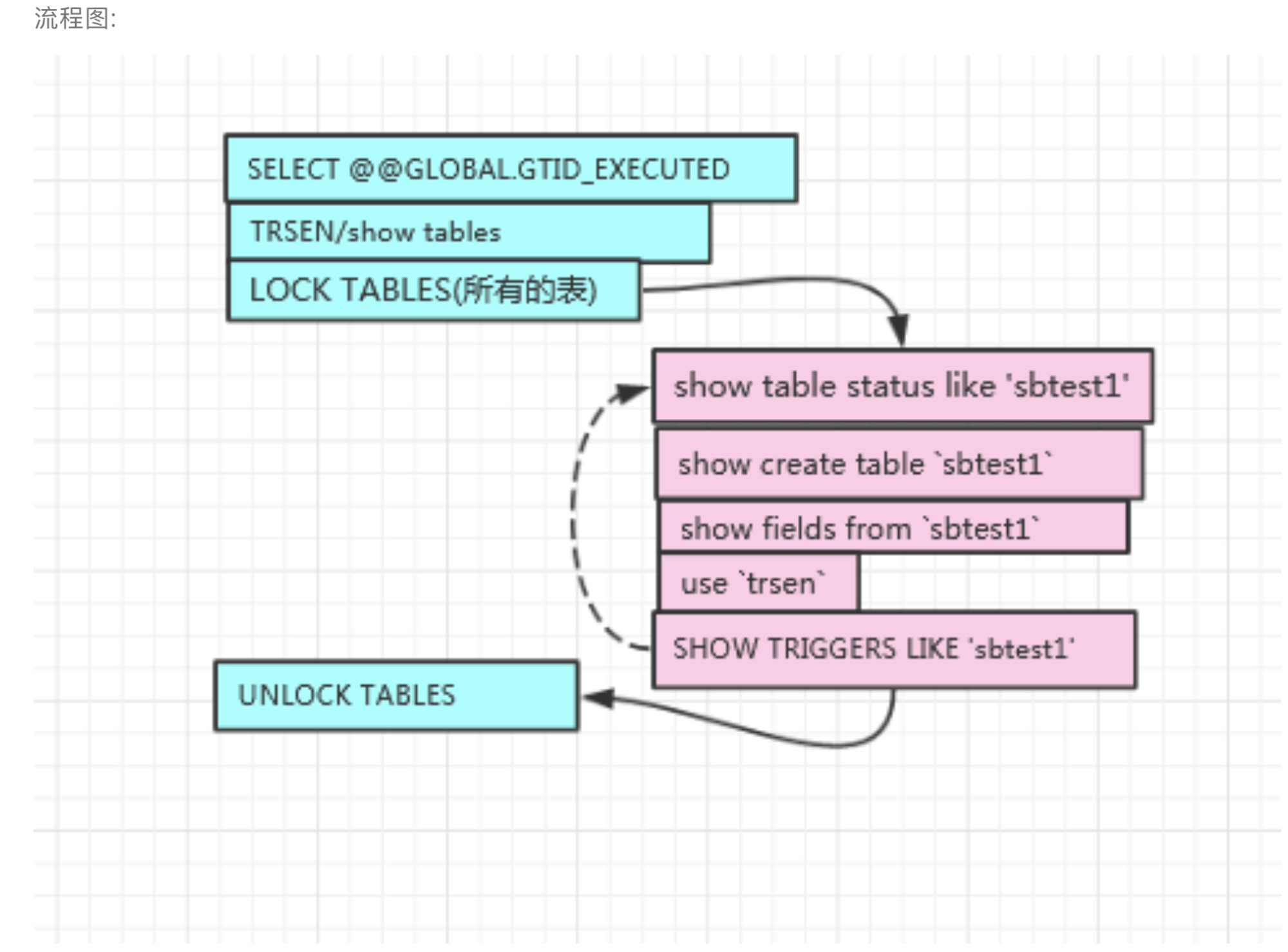 - 一致性备份 ```sql 命令: mysqldump -uqianlong -p123456 -h127.0.0.1 -P3306 --master-data=2 --single-transaction -B school > /chj/class/backup/school_`date +%Y%d%m`/school_`date +%Y%d%m`_2.sql 原理解析(仅从备份逻辑看) 0.连接数据库建立connect 1.Flush table(无- -master-data无此步骤):检查是否能进行加锁一致性备份,减少FTWRL锁表时间。有则等之,无则进行加FTWRL(确保如update事务执行后立马加锁) 关闭所有打开的表,强制关闭所有正在使用的表,并且将所有更新的数据刷新到磁盘,这个时间不会锁表。 2.FLUSH TABLES WITH READ LOCK——>如果不加参数--master-data就无此步骤 执行flush tables操作,并且加一个全局读锁. 3.设置RR事务隔离级别,准备快照后一致性读 4.START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */:开启一个一致性快照的事务,—single-transaction决定 ###概念补充 官方解释: The WITH CONSISTENT SNAPSHOT modifier starts a consistent read for storage engines that are capable of it. This applies only to InnoDB. The effect is the same as issuing a START TRANSACTION followed by a SELECT from any InnoDB table. 开启事务对所有表执行一次select操作,保证任意时间点执行 select * from tables得到数据和执行START TRANSACTION WITH CONSISTENT SNAPSHOT时的数据一致。 5.SHOW MASTER STATUS:获取GTID,MASTER_LOG_FILE和MASTER_LOG_POS。 6.UNLOCK TABLES:释放FTWRL加的global read lock 7.做还原点SAVEPOINT 8.查看所有库表信息 9.利用show create table xxx;+select * from table_a进行备份(循环备份至结束)生成insert语句,每个表备份结束时回退到还原点SAVEPOINT(ROLLBACK TO SAVEPOINT sp),提高DDL并发 SELECT /*!40001 SQL_NO_CACHE */ * FROM `sbtest1` ;SQL_NO_CACHE的作用是查询结果不会缓存到查询缓存中。 10.释放掉还原点 结论: 1.锁表时间短(FTWRL后获取一致性点位立即释放,是一个瞬间过程) 2.一致性备份(针对InnoDB获取快照) 3.备份能否有效执行,取决于flush tables(释放所有正使用的表,也就是等事务结束) 4.对于非事务引擎,不会进行一致性备份(没有MVCC) 5.mysqldump的本质其实是通过select * from tab来获取表的数据。 6.mysqldump只适合放在业务低峰期执行,备份中DML过多,undo表空间变大。 ``` 流程图: 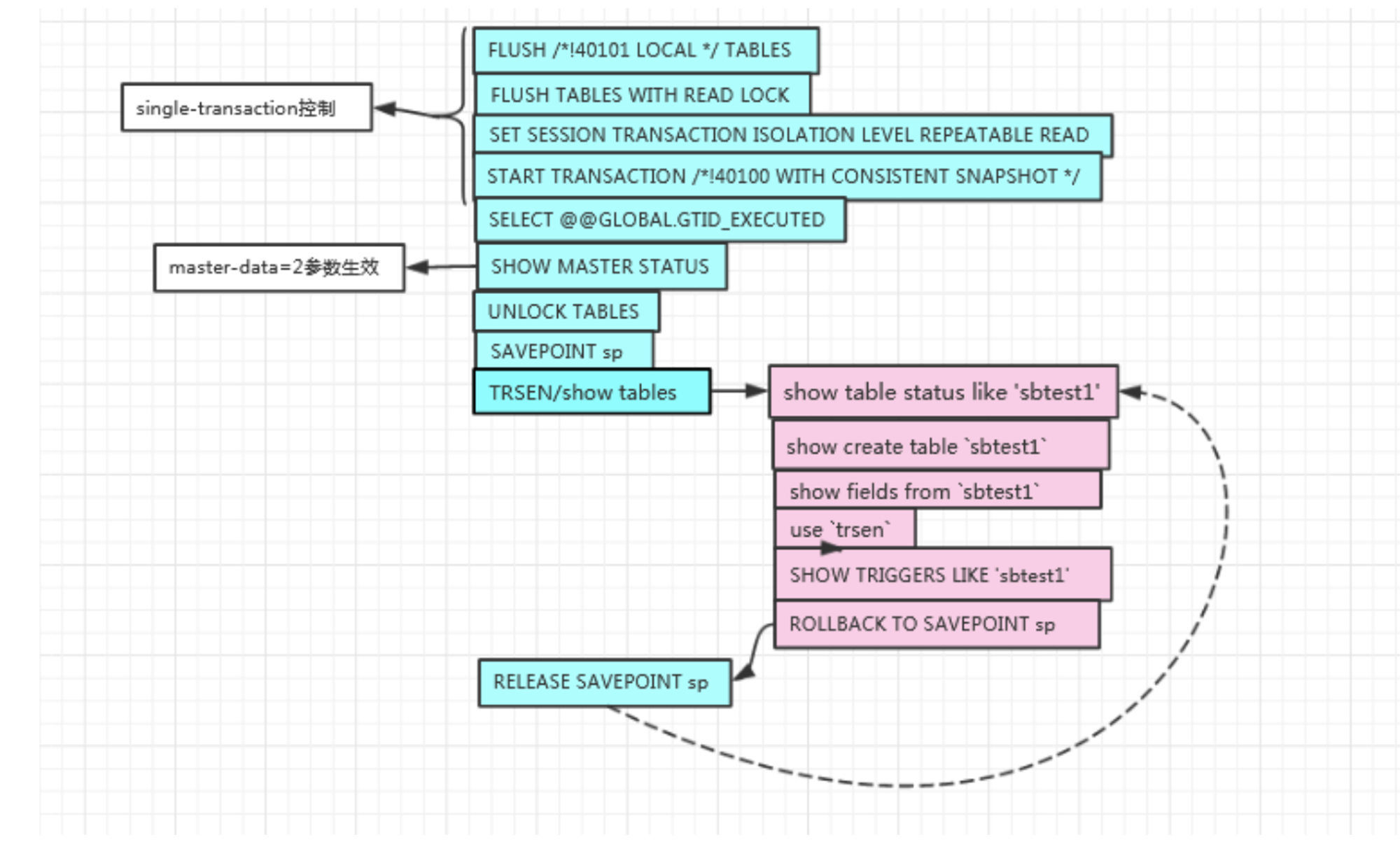 - 备份截图 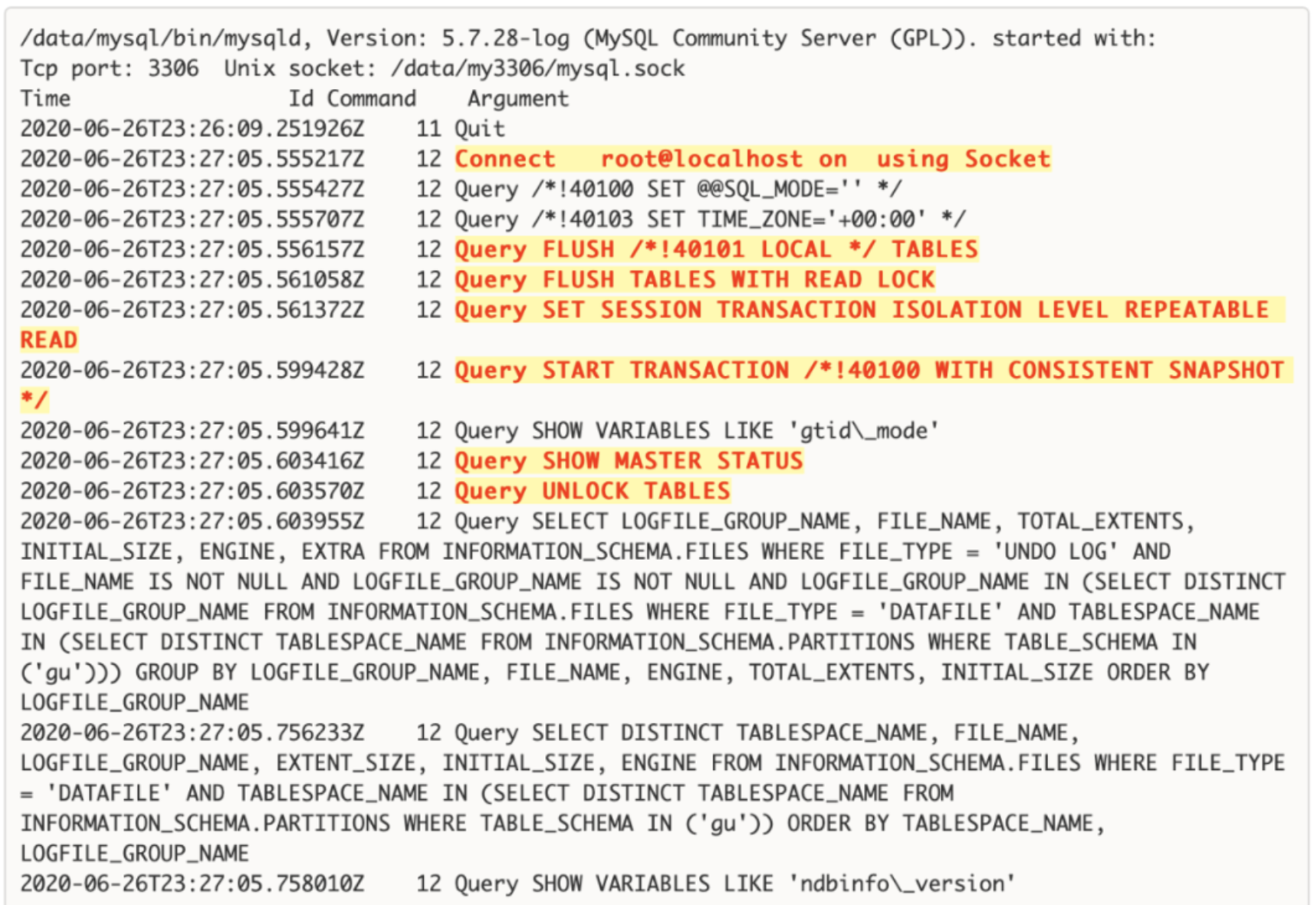 - innodb表执行流程 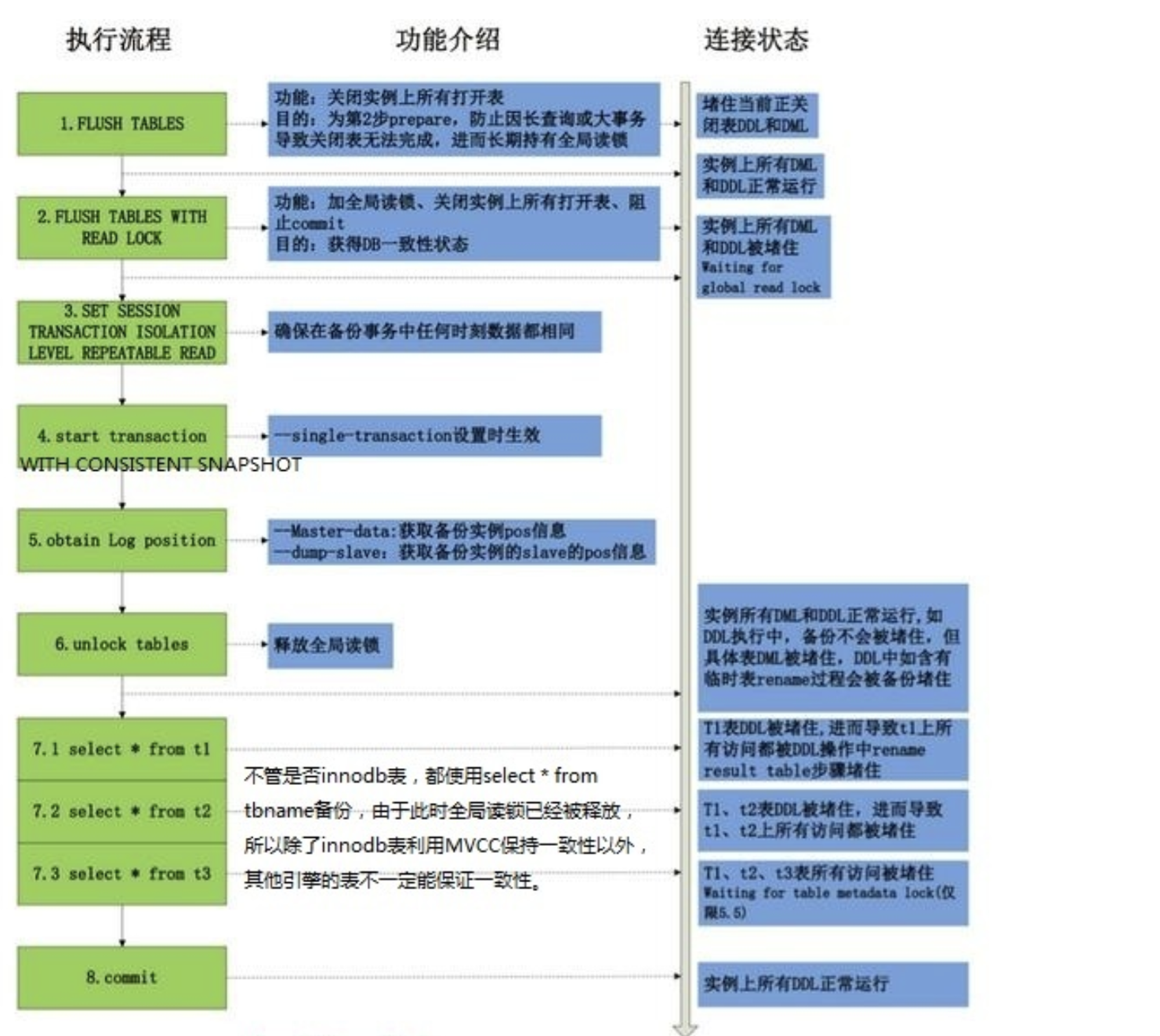 2.备份命令 ```sql 1.生产单库备份命令 mkdir -p /chj/class/backup/mysql57_`date +%Y%d%m`/ mysqldump -uqianlong -p123456 -h127.0.0.1 -P3306 --default-character-set=utf8mb4 --single-transaction --master-data=2 --triggers --events --routines -B sbtest --set-gtid-purged=off >/chj/class/backup/mysql3306_`date +%Y%d%m`/sbtest.sql 应用场景: ①版本升级 ②跨数据库类型做迁移 ③阿里云迁移到腾讯云 配合dts去实现的 --set-gtid-purges=off:默认为on会记录binlog,off不记录Binlog且设置SET @@GLOBAL.GTID_PURGED='',表明事务已经执行过 2.整实例备份(不推荐使用,5.7这个有bug会导致mysql.proc无法使用) mysqldump -uroot -ppassword -h127.0.0.1 -P3306 --default-character-set=utf8mb4 --single-transaction --set-gtid-purged=OFF --all-databases --master-data=2 --triggers --events --routines (--flush-logs可选参数) >/data/backup/mysql3306_`date +%Y%d%m`/backup_db01.sql 3.备份单表 mysqldump -uqianlong -p123456 -h127.0.0.1 -P3306 --default-character-set=utf8mb4 --single-transaction --master-data=2 --triggers --events --routines -B sbtest --tables sbtest5 --set-gtid-purged=off >/chj/class/backup/mysql3306_`date +%Y%d%m`/sbtest.sql 4.按条件备份数据库(如果多表备份,则所有表column必须都有where列不然报错,如果类型不同,不会报错,但是不符合条件数据不会备份) mysqldump -uqianlong -p123456 -h127.0.0.1 -P3306 --default-character-set=utf8mb4 --single-transaction --master-data=2 --triggers --events --routines -B sbtest --tables sbtest5 --set-gtid-purged=off --where='id<101' >/chj/class/backup/mysql3306_`date +%Y%d%m`/sbtest.sql 5.只导出表结构 mysqldump -uqianlong -p123456 -h127.0.0.1 -P3306 -d --single-transaction --set-gtid-purged=OFF --master-data=2 --triggers --events --routines -B shcool > /chj/class/backup/school.sql 6.只备份数据 mysqldump -uops -p -h127.0.0.1 -P4444 --default-character-set=utf8mb4 --single-transaction --master-data=2 --flush-logs --set-gtid-purged=off --hex-blob --no-create-info --databases employees > /tmp/backup/employees_only_data.sql 7.备份恢复 #1.命令行灌入 mysqldump -uqianlong -p123456 -h127.0.0.1 -P3306 --default-character-set=utf8mb4 --single-transaction --master-data=2 --triggers --events --routines -B test --tables t1 --set-gtid-purged=off >/chj/class/backup/t1.sql #1.命令行文件 mysql -uqianlong -p123456 -h127.0.0.1 -P3306 test </chj/class/backup/t1.sql #2.流式导入 mysqldump -uqianlong -p123456 -h127.0.0.1 -P3306 --single-transaction --set-gtid-purged=OFF --master-data=2 --triggers --events --routines -B school > mysql -uqianlong -p123456 -h127.0.0.1 -P3306 #3.命令行交互 source /chj/class/backup/t1.sql; #2.source use test; source /chj/class/backup/t1.sql; #3.监控恢复进度 shell> pv -W -L 2M /chj/class/backup/school.sql| mysql -uqianlong -p123456 -h127.0.0.1 -P3306 school Enter password: 588MiB 0:04:54 [ 2MiB/s] [======================================================>] 100% ``` ## 2.2.**mydumper&myloader** ### 2.2.1.介绍 ```sql 1.介绍 C++开发的多线程的MySQL一致性逻辑备份工具。 github地址:https://github.com/maxbube/mydumper 官方文档:https://centminmod.com/mydumper.html 特性: - 逻辑性的分库分表备份可操作性强 - 支持多线程备份和恢复,并发执行(比mysqldump快5-10) - 支持一致性备份 - 文件切块(tidb4.0之前用mydumper作为备份工具) - 支持导出binlog - 支持文件压缩 2.工具命令 mydumper 备份导出 myloder 恢复导入 ``` ### 2.2.2.安装 ```sql 方式一.官网 方式二.TiDB官网 wget https://download.pingcap.org/tidb-enterprise-tools-nightly-linux-amd64.tar.gz tar xf tidb-enterprise-tools-nightly-linux-amd64.tar.gz cp ./* /usr/bin/ ``` ### 2.2.3.参数及格式说明 ```sql -B, --database 备份库 -T, --tables-list 备份表 -o, --outputdir 输出备份目录 -s, --statement-size 生成插入语句的字节数, 默认 1000000 -r, --rows 分成行块表,默认开启 -F, --chunk-filesize 每个备份文件快大小,默认MB -c, --compress 输出压缩文件 -e, --build-empty-files 表无数据,也产生空文件 -x, --regex 支持正则 -i, --ignore-engines 忽略 -N, --insert-ignore INSERT IGNORE输出插入SQL -m, --no-schemas 不导出表结构 -d, --no-data 不导出数据 -G, --triggers Dump triggers -E, --events Dump events -R, --routines Dump stored procedures and functions -W, --no-views Do not dump VIEWs -k, --no-locks 不加锁,会导致不一致状态 -l, --long-query-guard 长查询,默认60s -K, --kill-long-queries Kill长查询 (instead of aborting) -D, --daemon 启动守护进程 -I, --snapshot-interval dump快照时间, default 60秒 -L, --logfile 日志文件 -w, --where where条件 -h, --host The host to connect to -u, --user Username with the necessary privileges -p, --password User password -P, --port TCP/IP port to connect to -S, --socket UNIX domain socket file to use for connection -t, --threads 并发线程数, default 4 #重要参数 -t 根据CPU和生产高低峰情况合理分配 -L 日志推荐输出到文件,方便后续验证结果和排错 -o 备份文件目录 -v 方便查看备份进度,建议输出到log file中 -F 切割成制定大小64MB或者128MB -u 用户名 -p 密码 -h IP -P 端口 #备份流程 1.主线程 FLUSH TABLES WITH READ LOCK,阻止 DML 语句写入,保证数据的一致性 2.读取当前时间点的二进制日志文件名和日志写入的位置和gtid并记录在 metadata 文件中. 3.N个(线程数能够指定,默认是 4 ) dump 线程开启开启读一致的事物 START TRANSACTION WITH CONSISTENT SNAPSHOT ; 4.dump non-InnoDB tables , 首先导出非事物引擎的表(如果指定--trx-consistency-only)则忽略 5.主线程 UNLOCK TABLES 非事物引擎备份完后,释放全局只读锁 6.dump InnoDB tables ,事务备份InnoDB 表 7.事物结束 #备份文件说明 - 先执行一个备份命令 mydumper -h 172.21.188.37 -P 3306 -u qianlong -p 123456 -t 8 -F 8 -B sbtest -T sbtest3 -o /chj/class/backup/sbtest/ - 备份文件说明 metadata:元数据 记录备份开始和结束时间,以及binlog日志文件位置。 table data:每个表一个文件 table schemas:表结构文件 binary logs: 启用--binlogs选项后,二进制文件存放在binlog_snapshot目录下 daemon mode:在这个模式下,有五个目录0,1,binlogs,binlog_snapshot,last_dump。 备份目录是0和1,间隔备份,如果mydumper因某种原因失败而仍然有一个好的快照, 当快照完成后,last_dump指向该备份。 ``` 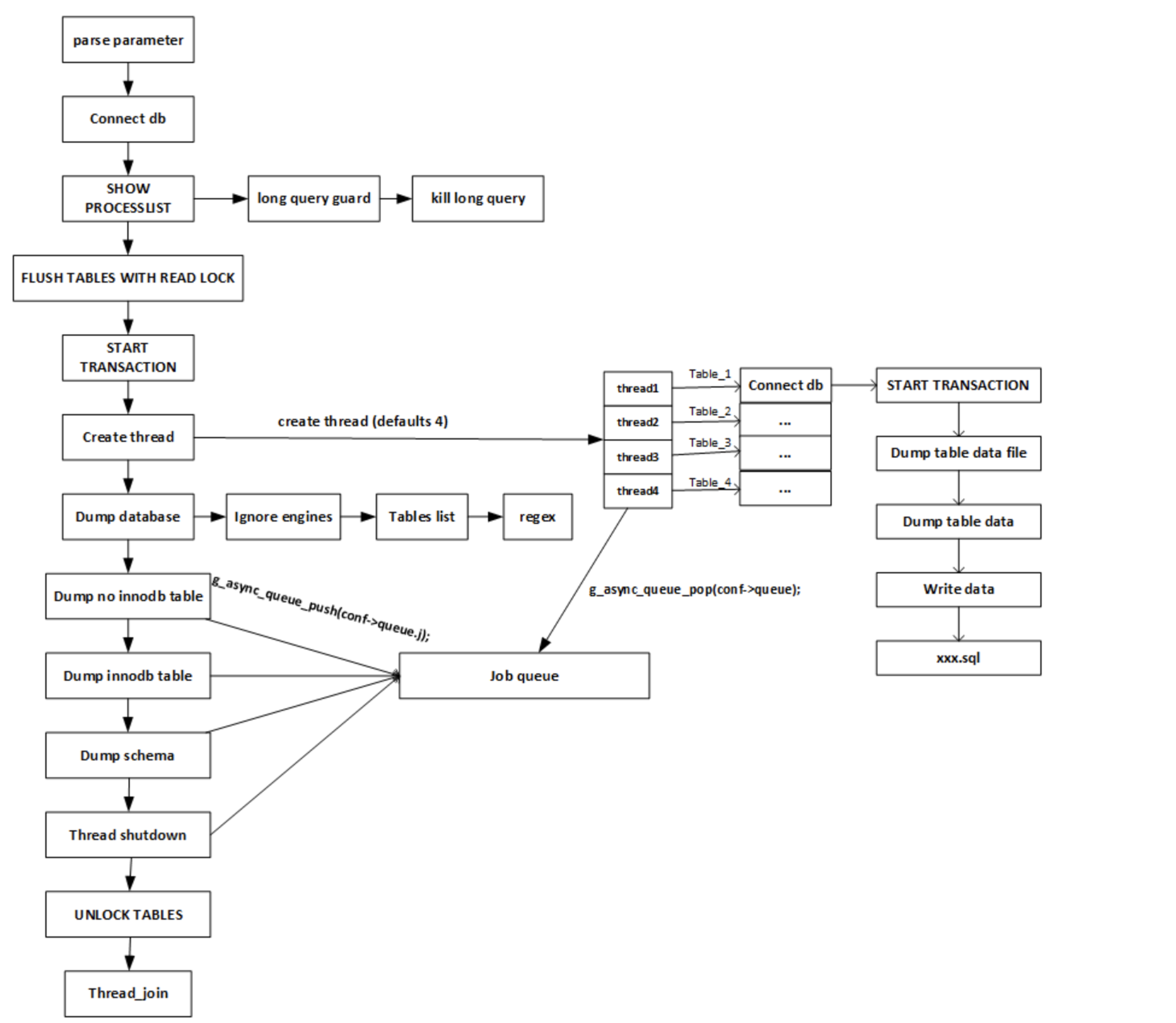 实例使用 ```sql #单库单表备份 mydumper -h 172.21.188.37 -P 3306 -u qianlong -p 123456 -t 8 -F 64 --trx-consistency-only -v 3 -G -E -R -B sbtest -T sbtest3 -L /chj/class/backup/sbtest3/mydumper.log -o /chj/class/backup/sbtest3 #单库单表 -w 过滤备份 mydumper -h 172.21.188.37 -P 3306 -u qianlong -p 123456 -t 8 -F 64 --trx-consistency-only -v 3 -G -E -R -B sbtest -T sbtest3 -w 'id<10' -L /chj/class/backup/sbtest/mydumper.log -o /chj/class/backup/sbtest/ #数据导入 loader -h 172.21.188.37 -P 3306 -u qianlong -p 123456 -t 8 -L /chj/class/backup/loader.log -d /chj/class/backup/sbtest3 ``` ## 2.3.mysqlpump > https://dev.mysql.com/doc/refman/5.7/en/mysqlpump.html ### 2.3.1.基本介绍 ```sql 1.介绍 MySQL5.7之后多了一个备份工具:mysqlpump。它是mysqldump的一个衍生. 特点: - 硬伤: - 单表粒度备份.如果4线程,备份库一张表,只有一个线程备份表,跟mysqldump一致 - 1个库,99个小表,1个大表.卡在大表备份进度上 - 并行备份数据库和数据库中的对象的,加快备份过程。队列+线程,允许有多个队列--parallel-schemas?),每个队列下有多个线程(N?),一个队列可以绑定1个或者多个数据库(逗号分隔) - 更好的控制数据库和数据库对象(表,存储过程,用户帐户)的备份。 - 备份用户账号作为帐户管理语句(CREATE USER,GRANT),而不是直接插入到MySQL的系统数据库。 - 备份出来直接生成压缩后的备份文件。 - 备份进度指示(估计值)。 - 重新加载(还原)备份文件,先建表后插入数据最后建立索引,减少了索引维护开销,加快了还原速度。 - 备份可以排除或则指定数据库。 2.参数 绝不部分与mysqldump一样 不一样的参数 1.--add-drop-user:在CREATE USER语句之前增加DROP USER,注意:这个参数需要和--users一起使用,否者不生效。 2.--compress-output:默认不压缩输出,目前可以使用的压缩算法有LZ4和ZLIB。 3.--default-parallelism:指定并行线程数,默认是2,如果设置成0,表示不使用并行备份。注意:每个线程的备份步骤是:先create table但不建立二级索引(主键会在create table时候建立),再写入数据,最后建立二级索引。 4.--defer-table-indexes:延迟创建索引,直到所有数据都加载完之后,再创建索引,默认开启。若关闭则会和mysqldump一样:先创建一个表和所有索引,再导入数据,因为在加载还原数据的时候要维护二级索引的开销,导致效率比较低。关闭使用参数:--skip--defer-table-indexes。 5.--exclude-databases:备份排除该参数指定的数据库,多个用逗号分隔。类似的还有--exclude-events、--exclude-routines、--exclude-tables、--exclude-triggers、--exclude-users。 6.--include-databases 指定备份数据库,多个用逗号分隔,,使用方法同exclude-databases 7.--skip-dump-rows :只备份表结构,不备份数据 mysqldump是 --no-data 8.--users:备份数据库用户,备份的形式是CREATE USER...,GRANT...,只备份数据库账号可以通过如下命令 举例: mysqlpump --exclude-databases=mysql,sys #备份过滤mysql和sys数据库 mysqlpump --exclude-tables=sbtest1,sbtest5 #备份过滤所有数据库中rr、tt表 mysqlpump -B sbtest --exclude-tables=sbtest1,sbtest5 #备份过滤sbtest库中的sbtest1、sbtest表 ``` ## 2.4. select..into outfile,load data & mysqlimport ### 2.4.1.介绍 ```sql 1. 高效读取文本数据到制定库表中 2. 适合异构迁移(可以灵活制定数据导入) 场景: - 大数据结果集导入. - 测试造数 3.工具分类 - select ..into outfile导出工具 - load data & mysqlimport导入工具 ``` - select into...outfile语法 ```sql > help select; Name: 'SELECT' Description: Syntax: SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [MAX_STATEMENT_TIME = N] [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] select_expr [, select_expr ...] [FROM table_references [PARTITION partition_list] [WHERE where_condition] [GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]] [HAVING where_condition] [ORDER BY {col_name | expr | position} [ASC | DESC], ...] [LIMIT {[offset,] row_count | row_count OFFSET offset}] [PROCEDURE procedure_name(argument_list)] [INTO OUTFILE 'file_name' [CHARACTER SET charset_name] export_options | INTO DUMPFILE 'file_name' | INTO var_name [, var_name]] [FOR UPDATE | LOCK IN SHARE MODE]] ``` - load data infile语法 ```sql #load data 需要有处理文件的权限, GRANT FILE ON *.* TO user@host; LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name' [REPLACE | IGNORE] INTO TABLE tbl_name [PARTITION (partition_name,...)] [CHARACTER SET charset_name] [{FIELDS | COLUMNS} [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char'] ] [LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ] [IGNORE number {LINES | ROWS}] [(col_name_or_user_var,...)] #关键字解释 LOW_PRIORITY | CONCURRENT:若指定LOW_PRIORITY,则该LOAD DATA 语句的真正执行将推迟到没有客户端在读取所设计的表时(只对只支持表锁的引擎有效); LOCAL:若未指定该关键字,则说明文件在MySQL所在机子上,文件由MySQL服务器去读取,此时如果后面指定为文件路径为相对路径,1.如果路径以./开头,那么路径是相对于MySQL的data目录的,2.如果路径不是以./开头,那么路径是相对于默认数据库的目录的;若指定了该关键字,则说明文件在客户端机子上,文件由客户端去读取并通过网络发送给MySQL服务器 REPLACE | IGNORE :当插入的行遇到UNIQUE字段重复时,若指定为REPLACE,则用该行替换原来的行;若指定为IGNORE,则忽略改行 PARTITION (partition_name,...):将数据插入指定分区 CHARACTER SET:若不指定字符集,MySQL默认使用character_set_database变量指定的字符集去读取文件,若文件字符集不同,则应指定该关键字 FIELDS TERMINATED BY:字段值的分隔符,若不指定则默认为 '\t' FIELDS ENCLOSED BY:字段值的包括符,若不指定则默认为 '' FIELDS ESCAPED BY:字段值的转义字符,若不指定则默认为'\\' LINES TERMINATED BY:指定行分隔符,若不指定则默认为为系统的默认行分隔符(‘\r\n‘ on windows,'\n' on linux) LINES STARTING BY:若指定该值为xxx,则MySQL会自动去掉xxx及其前面的字符,若某行不包含xxx,则改行将被忽略,若不指定默认为'',比如执行以下语句: ``` - mysqlimport ```sql 介绍:LOAD DATA INFILE SQL语句工具化,由 SELECT into outfile 导出的文件,也可以由 mysqlimport 导入。 mysqlimport -u root -pPassword [--local] dbname filename.txt [OPTION] 其中,“Password”参数是root用户的密码,必须与-p选项紧挨着;“--local”是在本地计算机中查找文本文件时使用的(指定 --local 后,文本文件可以放在任何地方进行导入,否则只能放在mysql的data目录下);“dbname”参数表示数据库的名称;“filename.txt”参数指定了文本文件的路径和称,文件里的数据插入到文件名去掉后缀后剩余名字对应的表中;“OPTION”为可选参数选项,其常见的取值有: --fields-terminated-by=字符串:设置字符串为字段之间的分隔符,可以为单个或多个字符。默认值为制表符“\t”。 --fields-enclosed-by=字符:设置字符来括住字段的值,只能为单个字符。 --fields-optionally-enclosed-by=字符:设置字符括住CHAR、VARCHAR和TEXT等字符型字段,只能为单个字符。 --fields-escaped-by=字符:设置转义字符,默认值为反斜线“\”。 --lines-terminated-by=字符串:设置每行数据结尾的字符,可以为单个或多个字符,默认值为“\n”。 --ignore-lines=n:表示可以忽略前n行。 ``` ```sql #1.完全导出和导入 #举例: 1.导出数据 select * from test.t1 into outfile "/tmp/test.txt"; ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement show global variables like '%secure_file_priv%'; - 查看 secure_file_priv 的值,默认为NULL,表示限制不能导入导出。 - secure_file_priv参数用于限制LOAD DATA, SELECT …OUTFILE, LOAD_FILE()传到哪个指定目录 - secure_file_priv 参数是只读参数,不能使用set global命令修改。 - my.cnf 加入参数 2.导入数据 truncate t1; load data infile '/tmp/test.txt' into table t1; #2.设置字段顺序导出和导入 desc app_user; select id,email,name,phone,gender,password,age,create_time,update_time from app_user into outfile "/tmp/app_user.txt" system head 10 /tmp/app_user.txt; truncate app_user; load data infile "/tmp/app_user.txt" into table app_user(id,email,name,phone,gender,password,age,create_time,update_time); #导出到execl #方法1 mysql -uroot -p"oldboyedU" -S /data/3306/data/mysql.sock a1 -e 'select * from t1' > aa.xls #方法2 select * from t1 into outfile "test.xls" ``` # 3.MySQL物理备份工具-Xtrabackup ## 3.1.介绍与工作流程 ```sql #介绍 1.Percona XtraBackup(简称PXB)是 Percona 公司开发的一个用于 MySQL 数据库物理热备的备份工具,支持 MySQl(Oracle)、Percona Server 和 MariaDB 2.- PXB8.0.以上版本版本,需要使用PXB 8.0.12+以上版本。 - 5.7一下版本用 使用PXB2.4,2.3都可 3.xtrabackup包含两个主要的工具,即xtrabackup和innobackupex,二者区别如下: - xtrabackup:备份innodb和xtradb两种引擎的表,而不能备份myisam引擎的表; - innobackupex:封装了xtrabackup的Perl脚本,支持同时备份innodb和myisam,但在对myisam备份时需要加一个全局的读锁。且myisam不支持增量备份。 4.实际利用InnoDB Crash Recovery机制 5.主要特性 - 热备 - 增量备份MySQL - 流压缩传输其他服务器 - 在线移动表 - 轻易创建主从 - 备份MySQL服务不会增大服务器负载 #备份方式 全量备份:快速恢复数据,占据空间过多,备份时间长 增量备份:基于上次全量或者增量,对数据库修改进行备份,省空间,省备份速度,但是恢复慢,且复杂 日志备份:针对Mysql二进制日志,结合使用,使数据库恢复到任意位置 #innobackupex基本参数介绍 ##官网参数指南 https://www.percona.com/doc/percona-xtrabackup/2.4/innobackupex/innobackupex_option_reference.html 1.--apply-log - 对备份的redo log进行crash recovery应用,恢复备份期间增量数据. - 创建新的事物日志,从innodbackupex备份的backup-my.cnf. 2.--backup-locks - 使用备份锁(比FTWRL轻,不会刷新打开所有innodb表文件),而不用FTWRL锁. - 默认启动,禁用--no-backup-locks(也就是开源5.7还是用FTWRL) 3.--compress - 压缩InnnoDB备份 4. --compress-threads=# - 压缩的工作线程数 5.--copy-back和--move-back - 保留备份文件和直接mv备份文件(会很快) 6.--databases=LIST - 制定备份库,不是很好用(推荐Mysql轻量级全备) 7.--decompress - 解压缩 .qp的备份文件 - 需要安装qpress程序 8、--defaults-file=[MY.CNF] - 制定备份文件的Mysql配置(备份和恢复都需要) 9.--kill-long-queries-timeout=SECONDS - 如果60s,则60s内不会阻止业务的查询或者DML - 超过60s,强行杀掉上FTWRL锁 10.--kill-long-query-type=all|select¶ - 制定杀掉什么类型的查询 11.--ftwrl-wait-timeout=SECONDS - 如果FTWRL等待查询超过参数,则备份终止 - 代表有大事务,如果不是DDL那肯定要优化业务了 12.--no-lock - 如果不关心备份的二进制日志位置可以使用 - 对MyISAM不在保持一致性数据 13. --no-timestamp - 不要带时间戳的目录 14.--parallel=NUMBER-OF-THREADS - 备份线程数,文件级别,多个 .ibd文件并行复制。 15.--rsync¶ - 优化本地文件传输(使用rsync复制所有非InnoDB文件,而不是每个文件单独CP) - 不能与--stream使用 16.--slave-info¶ - 下从节点备份很有用,打印主节点的一致性点位 17. --stream - 流式备份,支持tar和xbstream 18.--throttle=#¶ - 带宽限制 19.--tmpdir=DIRECTORY¶ - 流式备份使用,本地备份到tmpdir然后流式复制到崖村恒主机 20.--use-memory=# - 指定备份CR使用的内存量 ``` ## 知识补充:FTWRL全局只读锁 ```sql 1.概述FTWRL(flush tables with read lock) - 主要备份工具使用(mysqldump+PXB),Mysql8.0版本一下 - 对事务表(InnoDB)和非事务表加 table级别的S锁,获取一致性点位和数据 - 需要持有两把全局MDL锁,和关闭刷新所有表对象,容易导致数据库hang住 - 如果主库,则业务无法正常访问.从库,SQL线程卡主,主从延时 2.主要步骤 - 上全局读锁(lock_global_read_lock) - DML操作堵塞(Waiting for global read lock),innodb有MVCC机制,因为可以读到老版本数据 - 等待大查询结束,关闭表,此时等待(Waiting for table flush) - 清理表缓存(close_cached_tables) - 对MyISAM需要表的缓存落盘 - InnoDB有redolog无需这样 - 上全局COMMIT锁(make_global_read_lock_block_commit) - 是对InnoDB引擎有意义的一步,获取一致性点位(前两个步骤主要是为了MySIAM数据一致) - 阻塞正在执行的事务进行commit(大事务提交出现Waiting for commit lock) 3.一个简单场景,三个会话访问,A执行大查询访问表a,备份B正处于上全局读锁阶段,C在最后访问T表 - 三个会话顺序执行,B等A释放,C因为B等待 - B和C都出现waiting for table flush 最后总结一下 FTWRL堵塞了什么 1.DDL/DML/FOR UDPATE, 阻塞global S锁。 2.阻塞commit 3.不阻塞select(但是select长语句查询会占用表的缓存版本,FTWRL需要等待释放), - 如果kill select 则正常备份 - 如果kill掉 FTWRL (则缓存版本突进+1,但没有占用table缓存),这时候再有select 打开表判断table缓存版本和全局缓存是否一致,发现不一致,等待(后续该表所有SELECT/DML/DDL堵塞,Waiting for table flush),死局 ``` ## 3.2.备份流程 ```sql #备份流程(详细) 1.innobackupex在执行后会fork一个xtrabackup的进程,然后就等待xtrabackup的ibd数据文件。 2.xtrabackup在备份innoDB相关数据会启动俩个线程进行备份, - redo log 复制线程: - 负责拷贝redo log信息。 - redo线程只有一个,在ibd拷贝线程之前启动,在ibd拷贝线程结束后结束。 - xtrabackup进程开始执行后,先启动redo拷贝线程,从最新的checkpoint点开始顺序拷贝redo日志; - ibd复制线程:拷贝ibd文件 3.xtrabackup拷贝完成ibd后,通知innobackupex(通过创建文件),同时自己进入等待(redo线程仍然进行拷贝); 4.innobackupex收到xtrabackup通知后,执行FLUSH TABLES WITH READ LOCK(FTWRL),获取一致性点位,开始拷贝非ibd文件可选copy或者rsync方式俩种,拷贝非 InnoDB 文件过程中,因为数据库处于全局只读状态,如果在业务的主库备份的话,要特别小心,非 InnoDB 表(主要是MyISAM)比较多的话整库只读时间就会比较长,这个影响一定要评估到。 5.当 innobackupex 拷贝完所有非 InnoDB 表文件后,通知 xtrabackup(通过删文件) ,同时自己进入等待(等待另一个文件被创建) 6.xtrabackup 收到 innobackupex 备份完非 InnoDB 通知后,就停止 redo 拷贝线程,然后通知 innobackupex redo log 拷贝完成(通过创建文件); 7.innobackupex 收到 redo 备份完成通知后,就开始解锁,执行 UNLOCK TABLES; 8.最后 innobackupex 和 xtrabackup 进程各自完成收尾工作,如资源的释放、写备份元数据信息等,innobackupex 等待 xtrabackup 子进程结束后退出。 总结: - 备份过程,需要redo log,备份中产生的数据变化,恢复通过redo log+记录LSN进行CR. - xtrbackup备份MyISAM时候上的FTWRL锁,杀伤非常强大,锁定实例所有带X锁的读,DML和DDL(冻结LSN,不推进为最终一致的lsn,记录此位置).备份MyISAM表完成后才unlock tables锁。 - 这个锁的锁定时间取决于非InnoDB表的大小 - 解决备份FTWRL防止数据库夯住: 1.从参数解决 (1)设置这个锁超时参数,备份可以反复重试,线上业务更重要 ()设置kill query参数:回滚(杀掉)阻碍获得锁的事务(mdl和DDL). 2.换锁 - Percoa对MySQL Server层做了改进(使用LOCK TABLES FOR BACKUP和lock binglog for backup),MySQL8.0也是新增这个锁 - 这个锁对非InnoDB表上全局读锁,对InnoDB表上备份锁 - 对InnoDB表不刷新表,强制关闭表,DML没问题会阻止DDL(也就说不影响业务) --no-backup-locks 比FTWRL清理的锁 ,不用打开innodb表 参数--no-backup-locks - mysql8.0以上 备份就是LOCK INSTANCE FOR BACKUP,如果PXB判断Mysql版本有这个锁则自动使用此锁 3.采用—no-lock 不锁了 不保证MySIAM一致性 4.备份前做一个检查 - 数据库是否有大事务DML或DDL - 检查是否有MySIAM业务或者大表(消灭掉,都用InnoDB引擎这个时间就很短) 5.在从库上备份 - 加参数 - 从库唯一的DML就是同步主库,因为这时候主从同步也会延时,考虑进去 6.替换MySQL Server层 - 阿里的Mysql替代RDS使用(LOCK TABLES FOR BACKUP获取一致性数据和LOCK BINLOG FOR BACKUP获取一致性点位) - 使用Percona的MySQL版本 - 使用MySQL8.0以上版本(不稳定,暂时不推荐) - 替换MySQL5.7的Server层(需要有数据库研发支持) #参数说明 apply-log: #生产特别注意 一定要注意DML QPS的流量变化(redo线程),线上mysql业务流量过大 redo备份线程,永远在追数据的数据变化。业务低峰. ``` 详细流程: 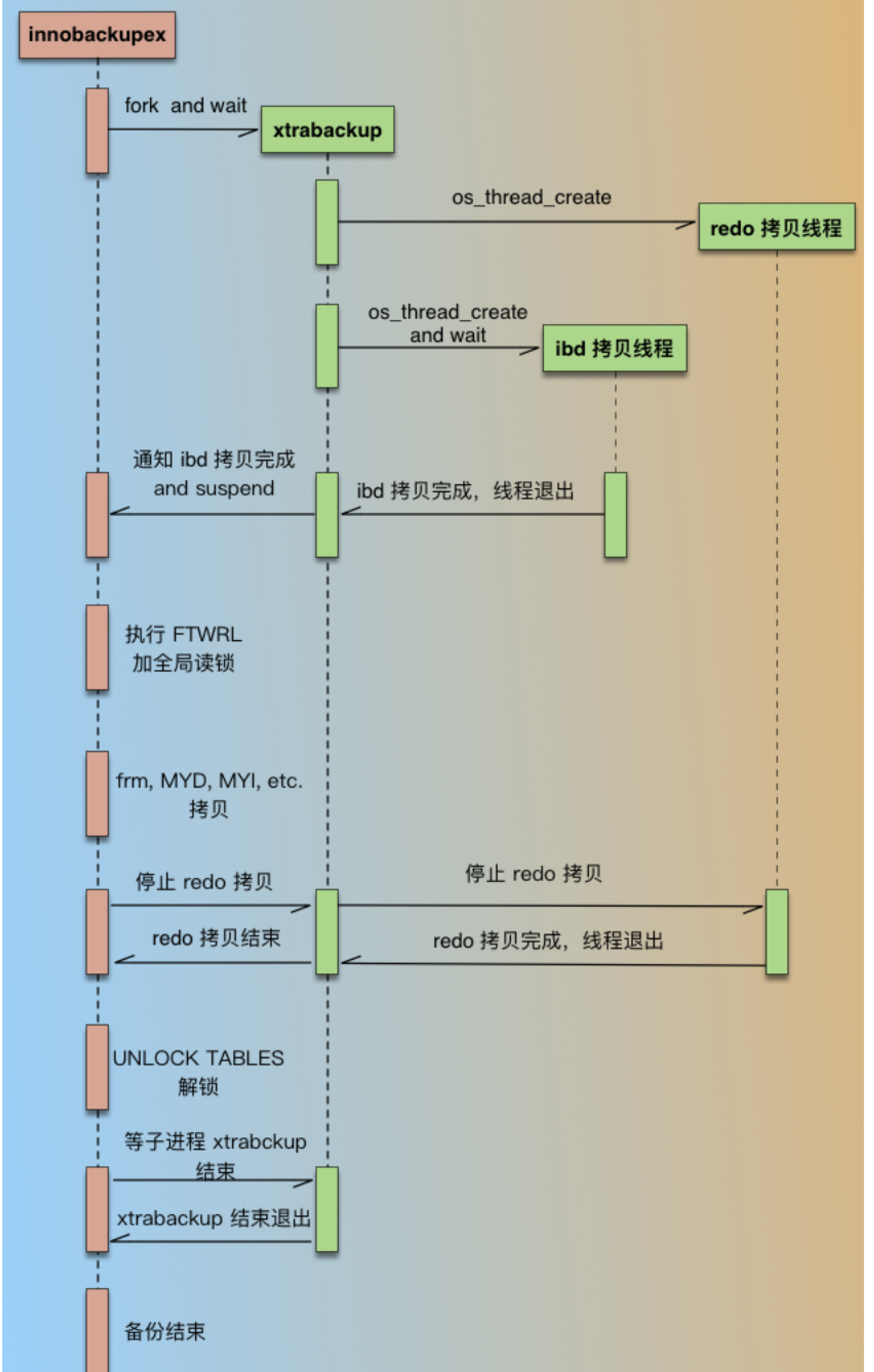 简易版全量备份流程: ```sql #备份流程(简易) 1 首先会启动一个xtrabackup_log后台检测的进程,实时检测mysql redo的变化,一旦发现redo有新的日志写入,立刻将日志写入到日志文件xtrabackup_log中 2 复制innodb的数据文件和系统表空间文件idbdata1到对应的以默认时间戳为备份目录的地方 3 复制结束后,执行flush table with read lock操作 4 复制.frm .myd .myi文件 5 并且在这一时刻获得binary log 的位置 6 将表进行解锁unlock tables 7 停止xtrabackup_log进程 ``` 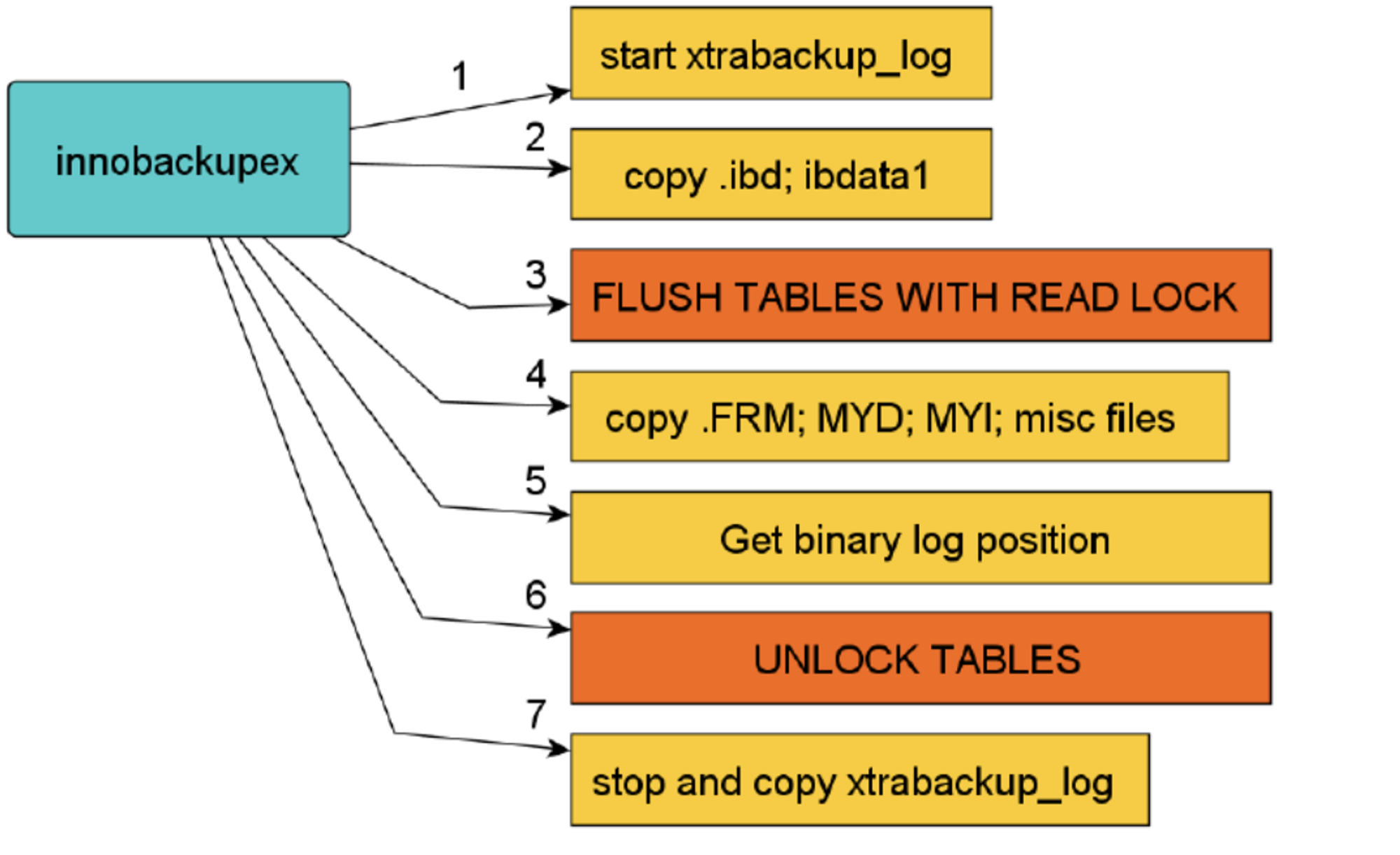 增量备份流程 ```sql 增量备份主要是通过拷贝innodb中有变更的页(指的是LSN大于xtrabackup_checkpoints中的LSN号)。增量备份是基于全备的,第一次增量备份的数据是基于上一次全备,之后的每一次增倍都是基于上一次的增倍,最终达到一致性的增倍,增倍的过程中,和全备很类似,区别在于第二步 ``` 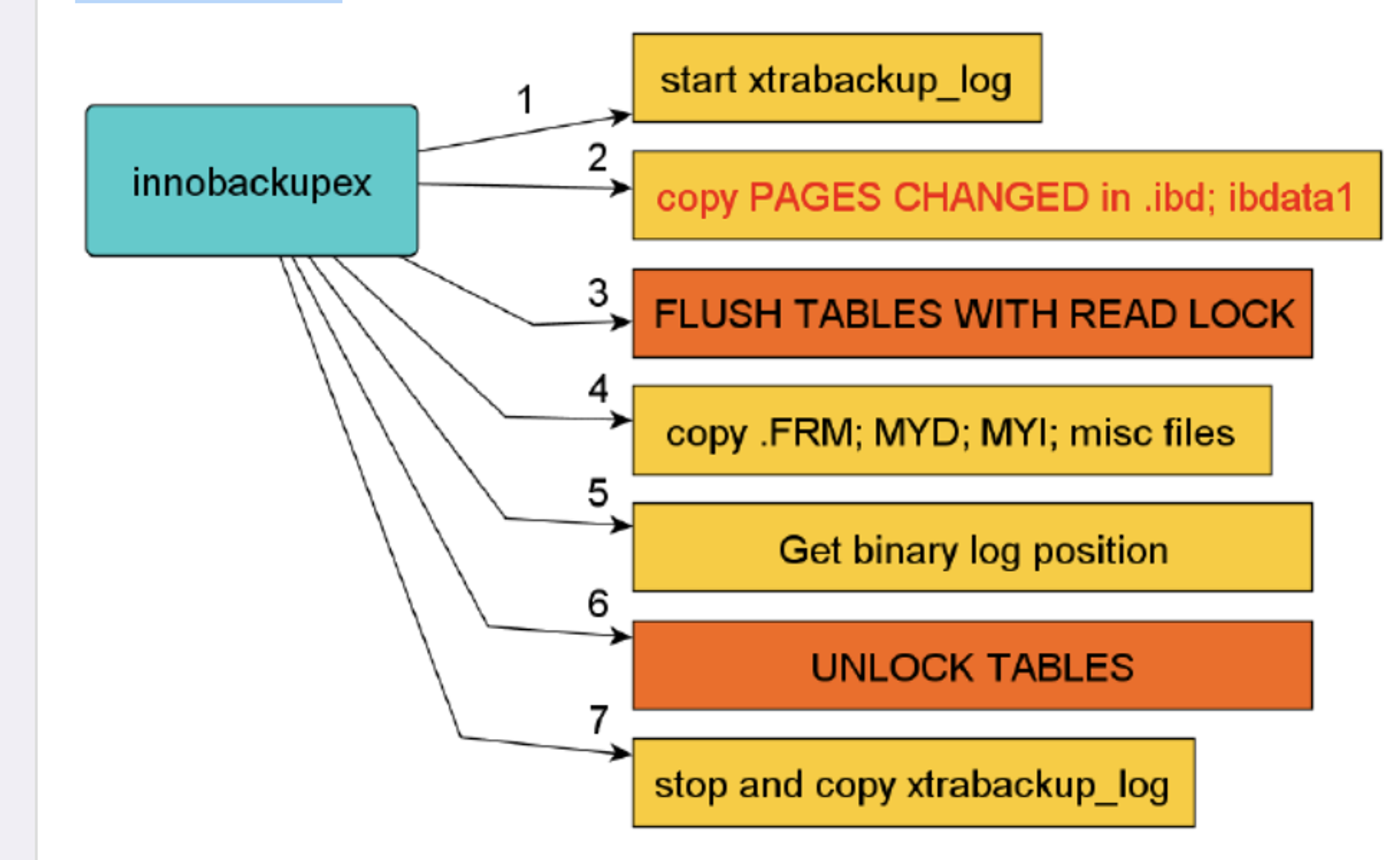 ## 3.3. 恢复流程 全量恢复流程 ```sql 1.prepare阶段:PXB使用复制redo log信息对数据文件进行CR,备份InnoDB表达到最终一致 2.数据恢复阶段: - innodbackupex读取my.cnf配置文件变量(目录,路径等) - 复制MyISAM表,InnoDB表索引文件,最后复制日志文件 - 文件复制保留文件属性,在启动数据库服务器之前,修改文件所有权 - 可以使用move-back,与copy-back区别,移动到目标位置(删除备份文件) ``` ## 3.4.备份与恢复命令使用 ```sql #创建用户 CREATE USER 'dba_backup'@'%'IDENTIFIED BY "dba_backUP123"; GRANT all ON *.* TO 'dba_backup'@'%' ; #下载与安装 shell> wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm shell> yum localinstall percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm # mysql8.0案例 - mysql 8.0 的版本= Percona-XtraBackup-8.0.35 - 因为8.0修改了redo Percona-XtraBackup暂时不识别 root@db01:~# wget https://downloads.percona.com/downloads/Percona-XtraBackup-8.0/Percona-XtraBackup-8.0.35-30/binary/debian/jammy/x86_64/percona-xtrabackup-80_8.0.35-30-1.jammy_amd64.deb root@db01:~# dpkg -i percona-xtrabackup-80_8.0.35-30-1.jammy_amd64.deb root@db01:~# xtrabackup --defaults-file=/data/mysql3306/etc/my.cnf --host=127.0.0.1 --port=3306 --user=dba_backup --password=dba_backUP123 --backup-lock-timeout=1 --parallel=8 --use-memory=2G --backup --target-dir=/data/backup8/ #注意 xtrabackup 版本要跟mysql8 版本一致。如果不一致需要增加如下参数 --no-server-version-check 最好保持一致 ---------------忽略-------------------- 更改认证方式 报错:caching_sha2_password.so 1。需要下载so文件 2。更改用户的认证方式为 mysql_native_password alter user 'dba_backup'@'%' identified with mysql_native_password by 'dba_backUP123'; ----------------------------------- 重要参数 --parallel=8 并行备份 --backup-lock-timeout 能够在存在备份锁等待的情况下 超过参数指定时间后,放弃备份任务,优先保障实例上面SQL命令的执行。 --kill-long-queries-timeout 能够在有Long-quer阻塞的情况下 杀掉长查询的session,优先保障备份任务的执行。 #普通本地磁盘全备 mysql 5.7 innobackupex --defaults-file=/chj/class/data/mysql57/etc/my.cnf --host=172.21.188.37 --port=3306 --user=qianlong --password=123456 --no-timestamp --parallel=8 --use-memory=2G /chj/class/backup/backup_3306 --parallel=8 并行备份 #产生文件 backup-my.cnf:备份需要的my.cnf选项,主要innodb参数恢复 xtrabackup_checkpoints:备份类型和备份状态及备份LSN信息,增量备份特别依赖 xtrabackup_binlog_info:binlog点位he gtid信息 xtrabackup_logfile: 记录 --apply-log操作使用数据(ib_logfile0)。如果apply-log时间长,则文件很大 #需要备份权限 - RELOAD,lock tables:备份使用FTWRL和flush engine logs,开始复制数据.在backup locks,需要自行LOCK TABLES for bcakup 和 lock binlog for backup.除非备份执行--no-lock - REPLICATION CLIENT:备份二进制日信息 ``` - 全量数据恢复 ```sql #恢复 prepare innobackupex --apply-log /chj/class/backup/backup_3306 #恢复 拷贝数据文件 innobackupex --defaults-file=/chj/class/data/mysql57/etc/my.cnf --move-back /chj/class/backup/backup_3306 #mysql8 xtrabackup --prepare --target-dir=/data/backup8/ xtrabackup --defaults-file=/data/my8.0.cnf --copy-back --target-dir=/data/backup8/ chown -R mysql:mysql /chj/* mysqld --defaults-file=/chj/class/data/mysql57/etc/my.cnf --user=mysql & #增量数据恢复(体验作业,实际生产环境不推荐) ##最佳场景 1.单库数据恢复 2.快速构建主从 ``` **备份流程** ```sql 1.创建备份 xtarb innobackupex --defaults-file=/etc/my.cnf --host=127.0.0.1 --port=3306 --user=dba_backup --password=dba_backUP123 --no-timestamp --parallel=8 --use-memory=2G /data/backupmysql 2> backupmysql.log 2.进行redo log的应用 innobackupex --apply-log 3.压缩 tar -zcf 4.策略 要不要本地保留最近一份的 5.上传到 s3 hdfs cpef nfs ftp等等 ``` Xtrabackup(PXB)是Percona公司CTO Vadim参与开发的一款基于InnoDB的在线热备工具,属于物理备份数据工具; 具有开源、免费、支持在线热备、备份恢复速度快、占用磁盘空间小等特点,并且支持不同情况下的多种备份形式。 官方软件下载链接:https://www.percona.com/downloads/ 对于数据库8.0.20版本,需要使用PXB 8.0.12+以上版本,对于数据库8.0.11~8.0.19,可以使用PXB 8.0正式版本; PXB 8.0只能备份MySQL 8.0版本数据,不能备份低版本数据信息;如果想备份数据库服务低版本程序数据,需要下载使用PXB 2.4版本; xtrabackup包含两个主要的工具:xtrabackup和innobackupex - xtrabackup 只能备份InnoDB和XtraDB两种类型的数据表,而不能备份MyISAM类型数据表; - innobackupex 是一个封装了xtrabackup的perl脚本,支持同时备份InnoDB和MyISAM,但对MyISAM备份时需要加全局读锁; 由于PXB属于第三方软件工具程序,因此需要进行单独下载安装: ```sql # 进行软件程序上传 [root@xiaoQ ~]# cd /usr/local/ [root@xiaoQ-01 local]# rz -y [root@xiaoQ-01 local]# ll percona-xtrabackup-80-8.0.13-1.el7.x86_64.rpm -r-------- 1 root root 13097340 11月 27 02:08 percona-xtrabackup-80-8.0.13-1.el7.x86_64.rpm # 进行软件程序安装 [root@xiaoQ-01 local]# yum install -y percona-xtrabackup-80-8.0.13-1.el7.x86_64.rpm -- 利用yum方式安装本地的rpm包程序,可以有效解决软件依赖的问题; ``` Xtrabackup(PXB)属于物理备份工具(针对数据文件进行备份),具体备份逻辑如下:(支持增量备份数据) - 在数据库服务运行期间,通过拷贝数据文件(实质拷贝的是数据页),进而实现数据备份目的; - 在进行数据文件拷贝的同时,会将备份期间的变化redo日志信息同时进行备份(拷贝); Xtrabackup(PXB)属于物理备份工具(针对数据文件进行备份),具体恢复逻辑如下: - 在进行数据恢复时,模拟了InnoDB Crash recovery(CR)的运行过程,需要将备份进行处理,才能进行数据恢复; - 在进行数据恢复时,对于备份进行处理操作,特指的就是前滚操作(redo)和回滚操作(undo),从而解决数据恢复一致性问题; **Xtrabackup数据备份方式01:实现全量备份** ```sql # 全量备份操作: [root@xiaoQ-01 ~]# mkdir /data/backup/full -p -- 进行物理备份的目标目录不能存在数据信息,需要指定一个空目录进行备份 [root@xiaoQ-01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=192.168.30.101 --user=root --password=123456 --port=3306 --backup --target-dir=/data/backup/full 或者使用参数--datadir替换掉参数--defaults-file [root@xiaoQ-01 ~]# xtrabackup --datadir=/data/3306/data --user=root --password=123456 --port=3306 --backup --target-dir=/data/backup/full -- backup参数信息表示进行全备操作 # 物理备份命令执行输出信息说明: 221127 02:46:11 >> log scanned up to (277574297) -- 记录日志位置点信息,表示进行拷贝数据的checkpoint的SN号码,相当于磁盘当前数据页的SN号码; Using undo tablespace './undo_001'. Using undo tablespace './undo_002'. Opened 2 existing undo tablespaces. 221127 02:46:11 [01] Copying ./ibdata1 to /data/backup/full/ibdata1 221127 02:46:11 [01] ...done 221127 02:46:11 [01] Copying ./sys/sys_config.ibd to /data/backup/full/sys/sys_config.ibd 221127 02:46:11 [01] ...done 221127 02:46:11 [01] Copying ./mysql.ibd to /data/backup/full/mysql.ibd ... 省略部分信息... -- 进行相关数据文件、日志文件、共享表空间文件、数据表空间文件等文件的拷贝,并且拷贝过程是不会进行锁表操作的; -- 数据表空间信息备份完毕后,会有提示字段信息,并且此时会锁定binlog日志文件,并将binlog日志文件复制到备份目录; -- 在进行binlog日志文件备份时,会生成xtrabackup_binlog_info文件信息,用于记录物理备份后的二进制日志位置点; -- 二进制日志文件备份完毕后,会释放binlog日志文件锁定状态,并再次检查checkpoint的SN号码,确认redo日志是否变化; [root@xiaoQ-01 backup]# ll /data/backup/full/ -- 可以看到将原有数据库的数据目录信息,已经基本迁移到指定的物理备份目录中; ``` Xtrabackup数据备份工具在热备操作后产生的特殊数据文件说明: | 序号 | 文件名称 | 解释说明 | | ---- | ---------------------- | ------------------------------------------------------------ | | 01 | xtrabackup_binlog_info | 表示用于存储备份时的binlog位置点信息 | | 02 | xtrabackup_checkpoints | 表示用于记录备份时的数据页LSN信息,主要用于接下一次备份,需要保证连续性; | | 03 | xtrabackup_info | 表示整体物理备份信息的总览 | | 04 | xtrabackup_logfile | 表示存储在备份数据期间产生的新的的redo日志的信息; | | 05 | xtrabackup_tablespaces | 表示用于存储表空间的其余信息 | **Xtrabackup数据恢复方式01:全量备份恢复** 模拟进行数据库数据破坏性操作: ```sql [root@xiaoQ ~]# pkill mysqld [root@xiaoQ ~]# rm -rf /data/3306/data/* [root@xiaoQ ~]# rm -rf /data/3306/logs/* [root@xiaoQ ~]# rm -rf /data/3306/binlog/* ``` 进行数据库数据恢复的操作过程: ```sql [root@xiaoQ ~]# xtrabackup --prepare --target-dir=/data/backup/full ...忽略部分信息... Shutdown completed; log sequence number 19214860 221127 16:31:58 completed OK! -- 表示模拟CR过程,将redo日志进行前滚,undo日志进行回滚,让恢复数据信息保持一致性状态 [root@xiaoQ ~]# xtrabackup --copy-back --target-dir=/data/backup/full -- 将进行物理备份后的数据,再次进行还原恢复到备份前的目录中(拷贝回数据) [root@xiaoQ ~]# chown -R mysql.mysql /data/* [root@xiaoQ ~]# /etc/init.d/mysqld start -- 重新设置数据目录权限,并重新启动恢复数据库业务 ``` **Xtrabackup数据备份方式02:实现增量备份** xtrabackup物理备份数据时,实现增量备份原理分析: - 增量备份的实质是,基于上一次备份LSN变化过的数据页,进行相应的备份操作,从而可以不断实现增量备份操作; - 在备份同时产生的新的变更,会将redo日志信息备份; - 第一次增量备份时依赖于全量备份的,将来的恢复操作也要合并到全备中,再进行统一恢复; > 说明:利用XPK增量备份数据,主要目的是减少频繁全备数据的时间开销,可以将每天增量的数据进行更快速的备份 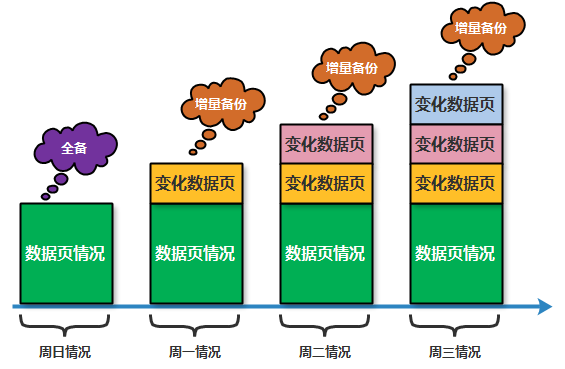 ```sql # 增量备份准备: [root@xiaoQ-01 ~]# mkdir /data/backup/full -p -- 提前准备好全量备份的目录; [root@xiaoQ-01 ~]# mkdir /data/backup/inc -p -- 提前准备好增量备份的目录; # 进行备份操作: [root@xiaoQ-01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=192.168.30.101 --user=root --password=123456 --port=3306 --backup --parallel=4 --target-dir=/data/backup/full -- 进行全量备份操作,并且开启并发线程备份功能(--parallel=4),从而提高备份效率(建议4~8个) mysql> create database pxb; mysql> use pxb mysql> create table t1(id int); mysql> insert into t1 values(1),(2),(3); mysql> commit; -- 模拟登陆数据库,进行相关操作,实现增量备份的效果 [root@xiaoQ-01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=192.168.30.101 --user=root --password=123456 --port=3306 --backup --parallel=4 --target-dir=/data/backup/inc --incremental-basedir=/data/backup/full -- 进行增量备份操作 # 可以进行继续备份操作(了解) [root@xiaoQ-01 ~]# mkdir /data/backup/inc02 -p -- 提前准备好增量备份的增量备份目录; mysql> create database pxb02; mysql> use pxb02 mysql> create table t1(id int); mysql> insert into t1 values(1),(2),(3); mysql> commit; -- 模拟登陆数据库,进行相关操作,实现增量备份的效果 [root@xiaoQ-01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=192.168.30.101 --user=root --password=123456 --port=3306 --backup --parallel=4 --target-dir=/data/backup/inc02 --incremental-basedir=/data/backup/inc -- 进行增量备份操作的下一次增量备份 ``` **Xtrabackup数据恢复方式02:增量备份恢复** 模拟进行数据库数据破坏性操作: ```sql [root@xiaoQ ~]# pkill mysqld [root@xiaoQ ~]# rm -rf /data/3306/data/* [root@xiaoQ ~]# rm -rf /data/3306/logs/* [root@xiaoQ ~]# rm -rf /data/3306/binlog/* ``` 进行数据库数据恢复的操作过程: ```sql # 准备相关备份日志信息 [root@xiaoQ ~]# xtrabackup --prepare --apply-log-only --target-dir=/data/backup/full -- 准备全量备份的日志; [root@xiaoQ ~]# xtrabackup --prepare --apply-log-only --target-dir=/data/backup/full --incremental-dir=/data/backup/inc -- 准备增量备份的日志,并且将增量备份合并到全量备份中; [root@xiaoQ ~]# xtrabackup --prepare --target-dir=/data/backup/full -- 在全量和增量数据合并后,在整体做日志信息的准备; # 进行数据备份拷回操作 [root@xiaoQ ~]# xtrabackup --datadir=/data/3306/data --copy-back --target-dir=/data/backup/full 或者 [root@xiaoQ ~]# xtrabackup --copy-back --target-dir=/data/backup/full -- 将进行物理备份后的数据,再次进行还原恢复到备份前的目录中(拷贝回数据) # 重新启动恢复业务功能 [root@xiaoQ ~]# chown -R mysql.mysql /data/* [root@xiaoQ ~]# /etc/init.d/mysqld start -- 重新设置数据目录权限,并重新启动恢复数据库业务 ``` ## 3.5.流式备份,压缩备份和从节点备份(主从后案例待补充) # 4. MySQL备份策略企业级规范(思维导图版),大项目,后期待补充 ```sql #总体目标 符合业务场景,恢复数据交付标准. 备份粒度:全量/单库(逻辑备份)/整实例(物理备份) #1.备份策略 小规模集群: mysqldump or mydumper-->小规模集群 在一台存储服务器-->低峰按库级别备份即可。 备份binlog 业务低峰期备份:8小时 如:/backup/mysql3306/{schema_a,schema_b} /backup/mysql3307/{schema_a,schema_b} 中等规模集群: mydumper或者xtrabackup,做一个备份脚本,定时备份 几台存储服务器,一起备份. 备份binlog 大规模集群:1000mysql实例以上 1.全是物理备份(xtrabackup)+核心业务库(不会很大,mydumper),全量 2.备份保留时间:HDFS永久保留,存储机(30T)保留1个月. 3.备份表结构 #数据恢复怎么做 - 需求资源:每天全量+增量(binlog) 即可 - 恢复场景: - 闪回部分数据:mysql2binlog-->解析增量数据即可 - 删表删库: - 全量备份新起一个实例+增量(binlog,恢复到删表drop前一个位置) - 全量备份新起一个实例(物理备份)+增量(主从点位去做,同步到删表前一个位置)-->数据库地址给业务验证-->如果OK全量导入线上 - 新起一个实例-->导入表结构+applog后的备份ibd文件-->替换表空间(discard/import tablespace)+主从(过滤复制)gtid到主库的删表前点位. #策略建议 1.备份什么:数据,binlog,表结构 2.备份策略:全量+物理备份+核心库(逻辑备份) 3.存储周期:存储节点30天+HDFS永久 4.恢复场景:少量数据恢复(mysql2binlog) 删库删表恢复(全量+增量) ```
李延召
2024年3月28日 22:23
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码