DBA专题
DBA授课
DBA公开课
DBA训练营三天
01.Mysql基础入门-数据库简介
02.Mysql基础入门-部署与管理体系
03.MySQL主流版本版本特性与部署安装
04.Mysql-基础入门-用户与权限
05 MySQL-SQL基础2
06 SQL高级开发-函数
07 MySQL-SQL高级处理
08 SQL练习 作业
09 数据库高级开发2
10 Mysql基础入门-索引
11 Mysql之InnoDB引擎架构与体系结构
12 Mysql之InnoDB存储引擎
13 Mysql之日志管理
14 Mysql备份,恢复与迁移
15 主从复制的作用及重要性
16 Mysql Binlog Event详解
17 Mysql 主从复制
18 MySQL主从复制延时优化及监控故障处理
19 MySQL主从复制企业级场景解析
20 MySql主从复制搭建
21 MySQL高可用-技术方案选型
22 MySQL高可用-MHA(原理篇)
23 MySQL MHA实验
24 MySQL MGR
25 部署MySQL InnoDB Cluster
26 MySQL Cluster(MGR)
27 MySQL ProxySQL中间件
相信可能就有无限可能
-
+
首页
19 MySQL主从复制企业级场景解析
# 1.延时复制 ## 1.1.延时复制 - 架构图 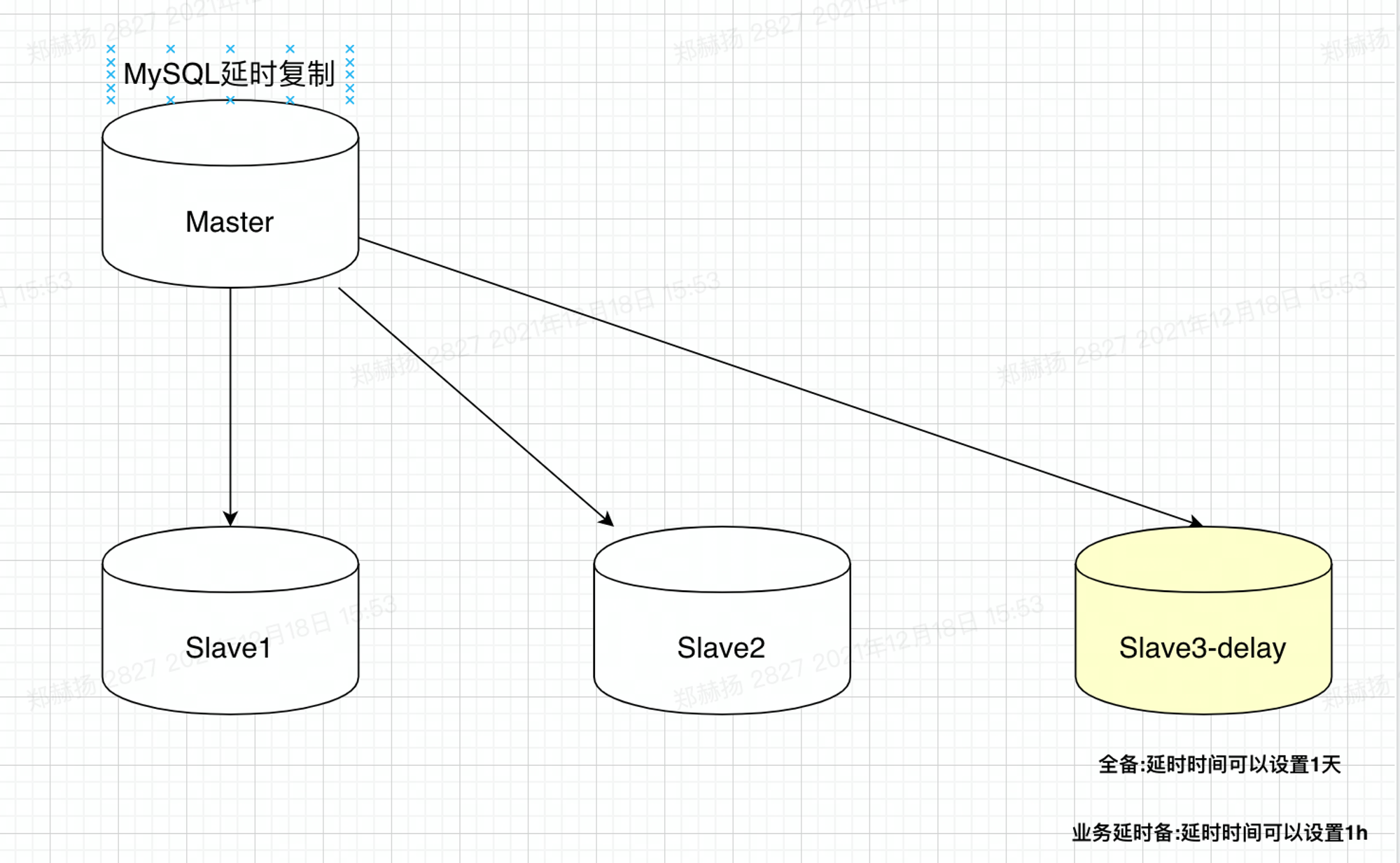 ### 1.1.1介绍 ```sql # 简介 - 通过配置,让slave延时sql线程的回放动作时间 - 设置从库sql_thread延时回放,指定晚于主库执行event时间(秒/小时/天),相当于主库任何DML/DDL都在延时时间后再从库回放 # 场景 1.便于数据恢复 - 主库业务或者DBA误操作,直接删库删表删数据(逻辑损坏),一般设置延时一小时(节省IO/BI数据分析) 2.惰性备份 - 比如延时一天备份(适合不宜每天全备的大数据量级场景) #缺点 资源利用率低,如果延时一小时可用来做BI节点 ``` ### 1.1.2.从库延时设置 ```sql #开启步骤 1.正常主从搭建 2.stop slave 停止从库 3.change master to master_delay = 3600; 延时一小时 4.start slave; 5.show slave status\G SQL_Delay:3600 查看从库状态 #验证,观察 create table app_user_new like app_user; insert into app_user_new select * from app_user; #取消延时 1.stop slave 暂停主从总库 2.change master to master_delay = 0; 关闭延时 3.start slave ``` ### 1.1.3.企业级从库延时恢复数据场景 - 流程 ```sql #场景 主库数据逻辑损坏(drop table,database,delete操作),利用延时从库恢复数据 #处理思路 ##业务切换流量,mysql切换主从,适合单实例单库场景 0.数据库数据逻辑损坏 1.业务层:切换到延时从库(shan'bi) 数据库:查看逻辑损坏操作GTID/点位 set gitd_next='误操作事务前一个' 从库设置read_only,通知业务暂停写入(正确做法是业务由MQ层,存储消费延时) 2.关闭主从延时:延时从库开始追主 3.从库追上误操作时间点后,延时从--->主库(stop slave;reset slave all;) 4.关闭read_only,主库流量写入,业务恢复 ##单实例多库多写入流量场景 0.数据库数据逻辑损坏 1.业务层:允许业务延时,该库业务读流量切换到延时从库,写流量写入MQ层 数据库层:找到误操作gtid/点位,stop slave until+关闭从库延时 2.主库开始恢复数据 主库全量数据(从延时从库抽取)+增量数据(从relay log or binlog提取) 3.业务恢复,消费写流量,读流量切回 4.延时从库延时恢复 ``` - 步骤(实验步骤) ```sql 1.数据库逻辑损坏(假设误删除一张表) create table user_delay like user; show master status; | mysql-bin.000002 | 3586982 | | | 196c4617-3fa0-11ec-9cce-fa202013137b:1-1181, ddd2aab7-24ae-11ec-8406-fa202013137b:1-72978, e7e868e0-3faf-11ec-b6e6-fa202013137b:1-12 | show master status; +------------------+----------+--------------+------------------+--------------------------------------------------------------------------------------------------------------------------------------+ | mysql-bin.000002 | 3587170 | | | 196c4617-3fa0-11ec-9cce-fa202013137b:1-1181, ddd2aab7-24ae-11ec-8406-fa202013137b:1-72978, e7e868e0-3faf-11ec-b6e6-fa202013137b:1-13 | 2.延时从库恢复数据 stop slave; change master to master_delay = 0; START SLAVE UNTIL SQL_BEFORE_GTIDS ='e7e868e0-3faf-11ec-b6e6-fa202013137b:12'; show slave status\G #数据恢复到误删前一刻 3.恢复数据或者延时从库节点提为新主 3.1.恢复数据 mysqldump数据到主库恢复即可 3.2.延时节点提为新主 #关闭只读 set read_only=0; #直接解散主从关系 stop slave;reset slave all; 4.业务写流量域名映射切换,show processlist观察是否正常 方案补充:延时从库恢复数据,如果不用START SLAVE UNTIL 则顺序步骤 1.停止延时从库 2.获取此时点位信息和逻辑损坏之前点位信息 show master status; show relaylog events in 'xxxrelay-bin.009472' 3.从relaylog中截取 mysqlbinlog --start-position --stop-position xxxrelay-bin.009472>/tmp/relay.sql 4.恢复数据 stop slave; set sql_log_bin=0; source /tmp/relay.sql; set sql_log_bin=1; #生产环境此种方法仅合适流量较小实例,如果流量较大,或者业务发现时间误操作时间较长(实际经验除非敏感业务可能要小时级别的数据误操作发现),则此方案效率较低 ``` - 课上提问 ```sql 1.恢复过程中,不能写入吗?如果没有mq - 跟业务沟通,分情况讨论 - drop table. - API接口写入报错 - 有update(数据错乱) - 可以写入 - 插入类 insert 2.误删时间久了 如何定位误删前的gtid点 - 业务发现问题,要事故时间点(报警) - 时间点位,mysqlbinlog --start-time --end-time |grep 'table_a' - binlog2sql--指定时间段 table的操作 3.延时从库设置为master后,原master变为从库后同步数据么? - 看代价,业务稳定行恢复后新建立主从方式灵活 - 原Master已经是错误操作-->修补数据-->reset master-->保持某个点位与新master数据一致-->建立主从(自动化工具拉去备份建立主从) 4.如果过了延时复制时间才发现表数据别删除呢? --->mysql误删除数据怎么办 - DML-->binlog2sql回滚 - 大量级(拉去全量备份+binlog增量)恢复数据 ``` ## 1.2.过滤复制 - 架构 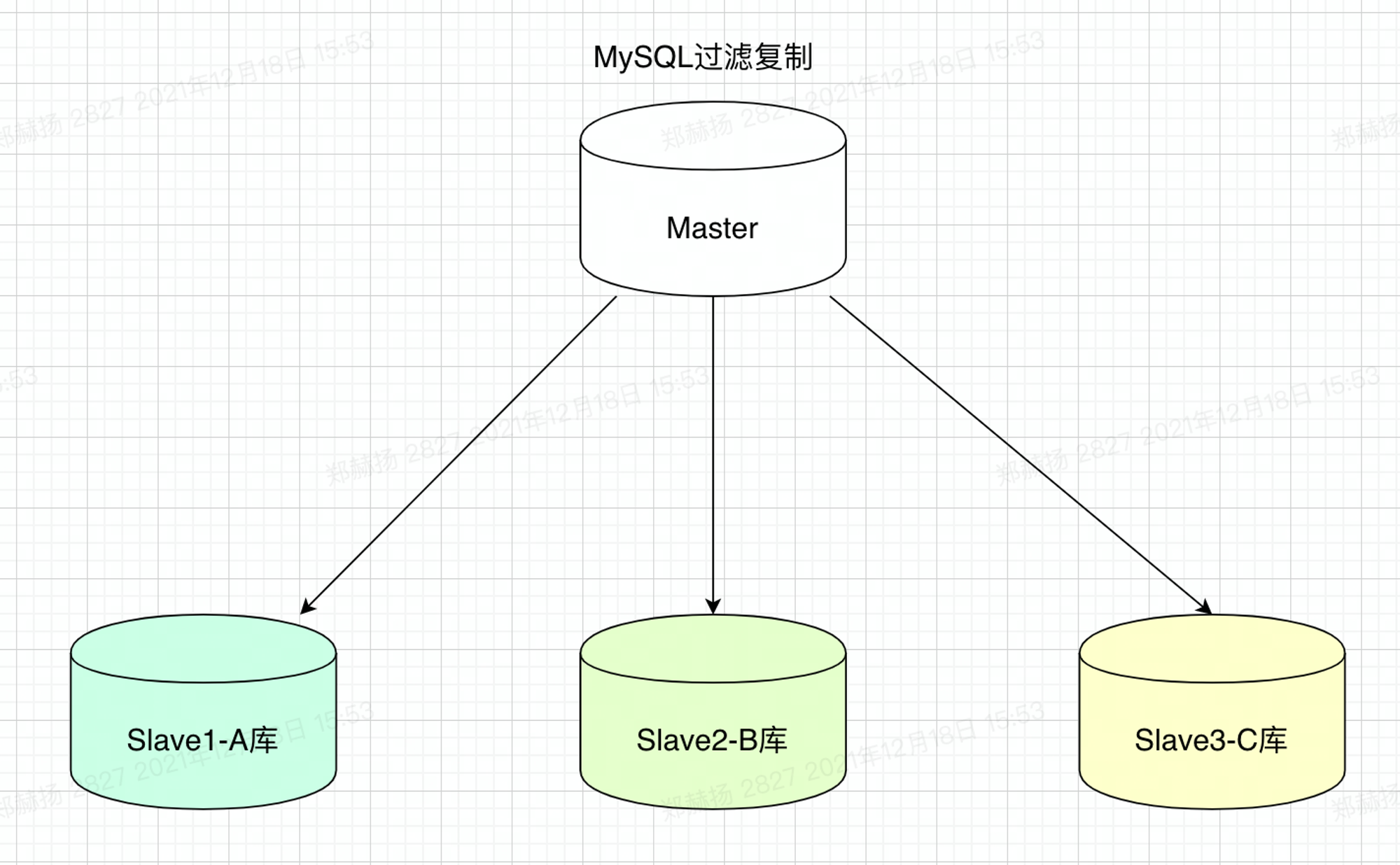 ### 1.2.1.介绍 ```sql #1.介绍 5.7支持动态修改,之前版本需要重启数据库 官方文档:https://dev.mysql.com/doc/refman/5.7/en/change-replication-filter.html #2.命令 STOP SLAVE SQL_THREAD; CHANGE REPLICATION FILTER REPLICATE_DO_DB = (test); START SLAVE SQL_THREAD; CHANGE REPLICATION FILTER REPLICATE_DO_DB = (); #3.参数 --replicate-do-db #指定复制的库 --replicate-ignore-db #指定忽略的库 --replicate-do-table #指定复制的表 schame_a.table_a --replicate-wild-do-table #复制指定的A.b%(支持通配符) --replicate-ignore-table #忽略指定表 --replicate-wild-ignore-table #忽略指定的表(支持通配符) #4.场景 推荐场景:单实例多库拆分单实例单库,不适宜长久运行 #待整理 https://www.cnblogs.com/chenjunwu/p/14298061.html ``` ### 1.2.2.过滤规则深入讲解 - table level-row模式下的过滤规则判断-允许跨库 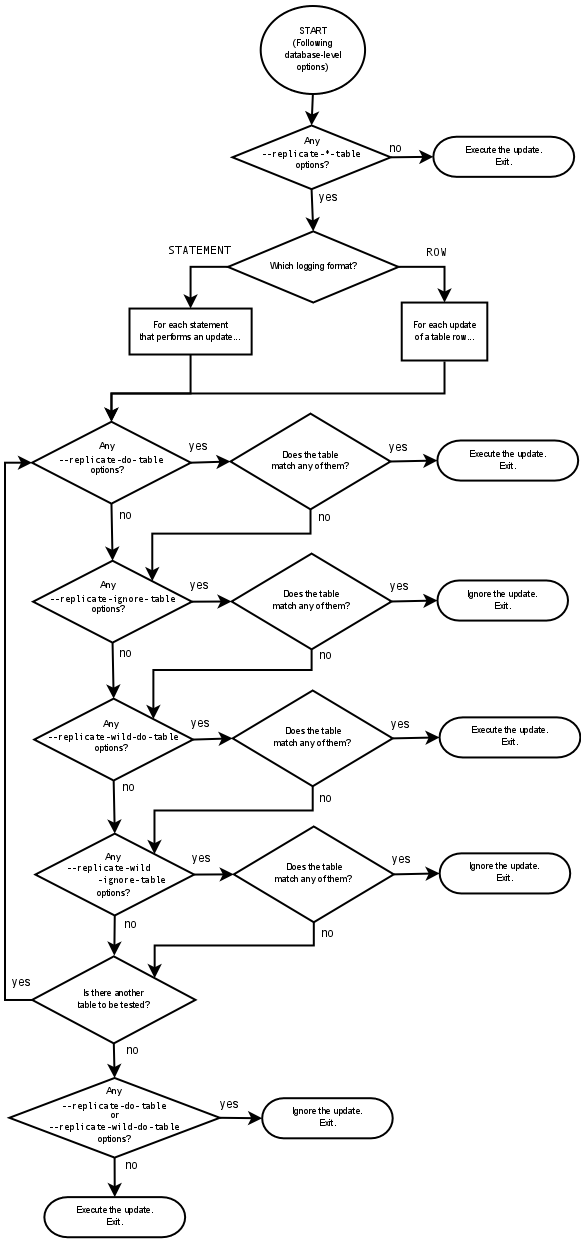 ```sql #规则 binlog_format='ROW',不受库级别规则限制,只受表级别规则限制。 #场景1:多库复制拆分 STOP SLAVE SQL_THREAD; CHANGE REPLICATION FILTER REPLICATE_DO_DB = (filter_test); start SLAVE SQL_THREAD; #场景二:复制某个库下某个表 STOP SLAVE SQL_THREAD; CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE = ('test.app_user_rewrite'),REPLICATE_WILD_IGNORE_TABLE = ('test.app_user_rewrite'); start SLAVE SQL_THREAD; #场景三:rewrite某个表 school.app_user_rewrite-->test.app_user_rewrite(自己试验) STOP SLAVE SQL_THREAD; CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB = ((school,test)), REPLICATE_WILD_DO_TABLE = ('school.app_user_rewrite'); start SLAVE SQL_THREAD; show slave status\G ##测试一下,主节点执行 delete from app_user_rewrite limit 1; #语法 Syntax: CHANGE REPLICATION FILTER filter[, filter][, ...] filter: REPLICATE_DO_DB = (db_list) | REPLICATE_IGNORE_DB = (db_list) | REPLICATE_DO_TABLE = (tbl_list) | REPLICATE_IGNORE_TABLE = (tbl_list) | REPLICATE_WILD_DO_TABLE = (wild_tbl_list) | REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) | REPLICATE_REWRITE_DB = (db_pair_list) db_list: db_name[, db_name][, ...] tbl_list: db_name.table_name[, db_table_name][, ...] wild_tbl_list: 'db_pattern.table_pattern'[, 'db_pattern.table_pattern'][, ...] db_pair_list: (db_pair)[, (db_pair)][, ...] db_pair: from_db, to_db ``` ### 1.2.3.企业级过滤复制应用架构场景 - 演变架构图 1.业务拆分前 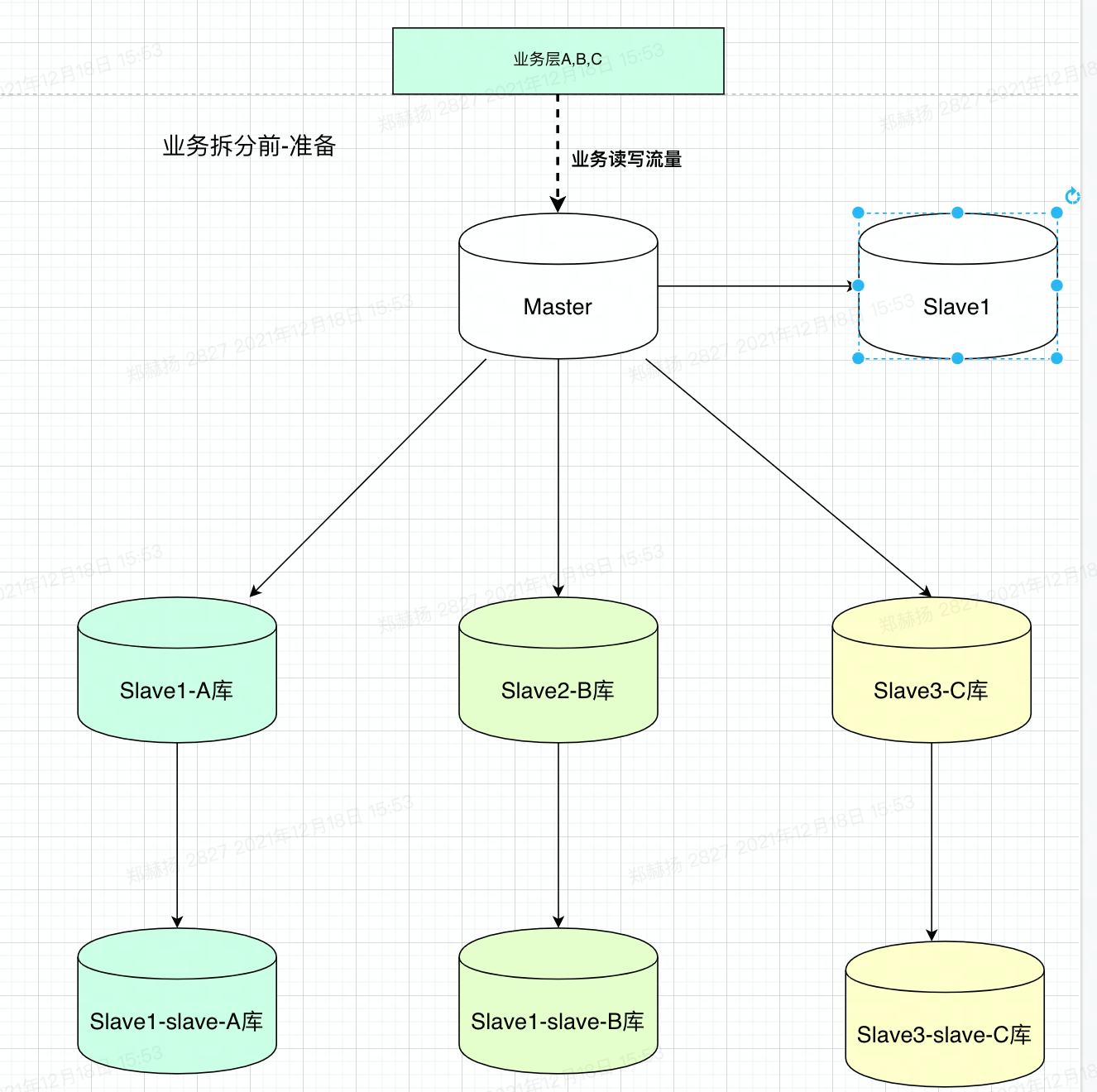 2.业务读写流量拆分 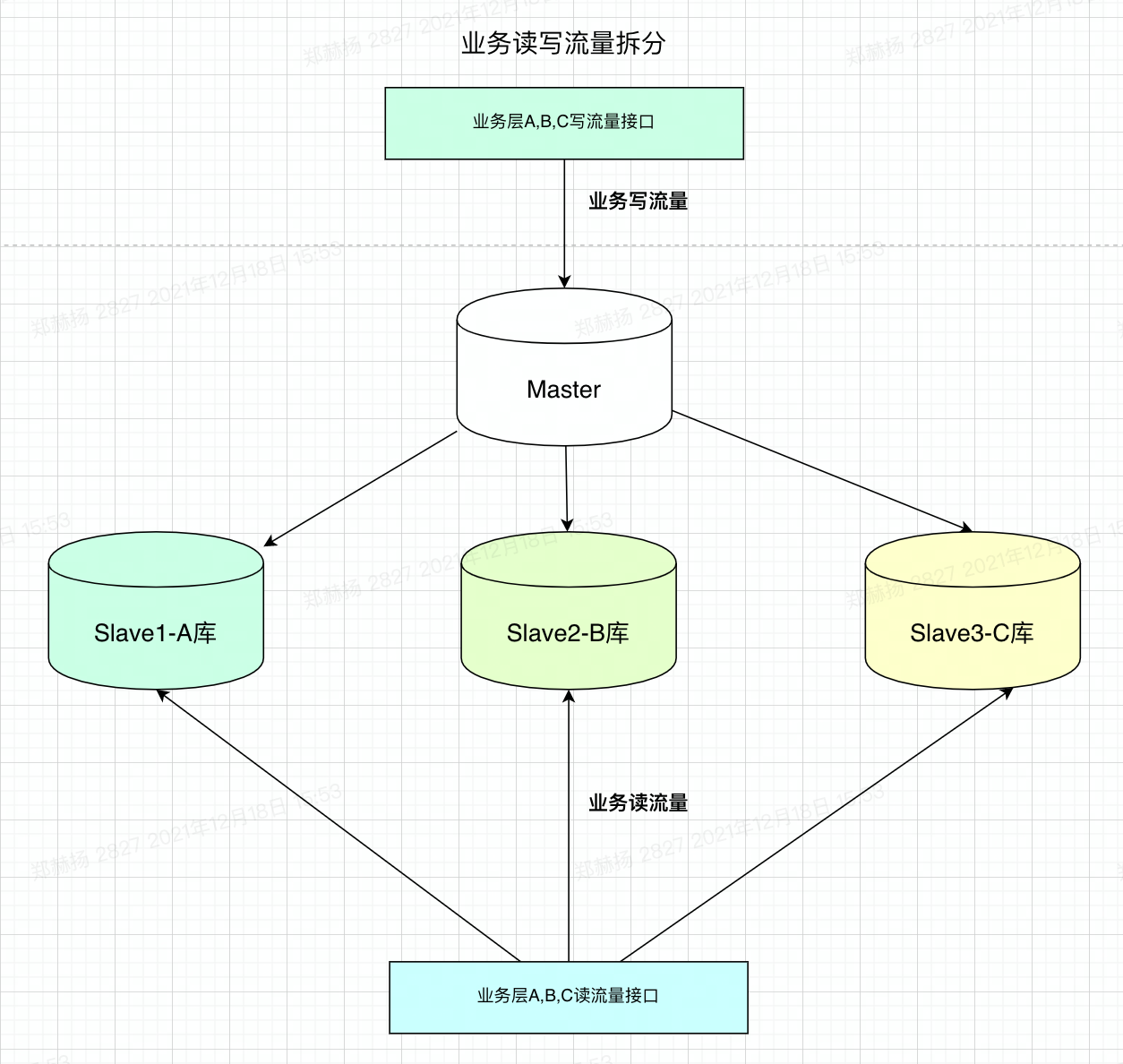 3.业务读写流量拆分 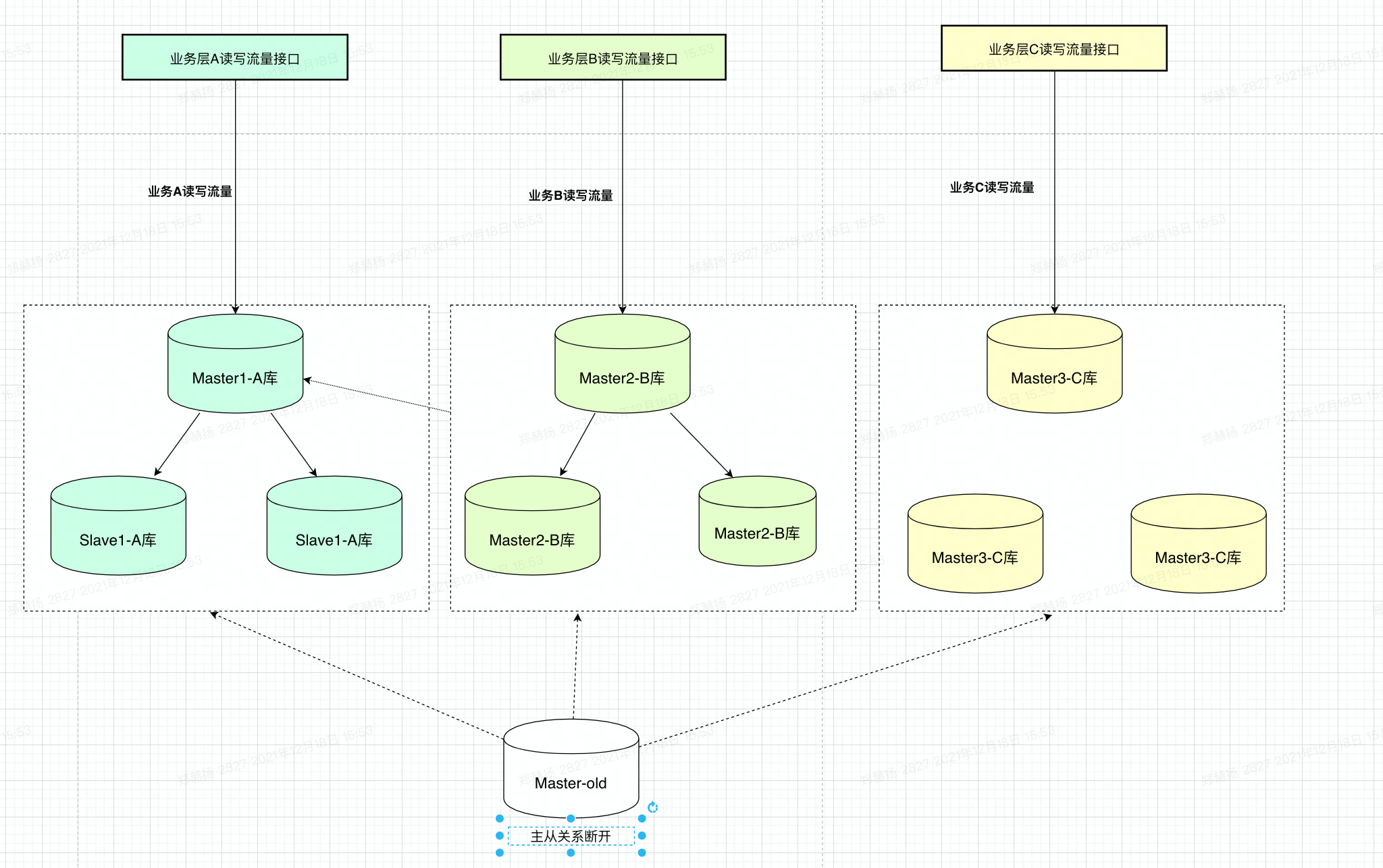 - 整体步骤 ```sql #假设有A B C 三个业务库需要拆分,原实例有4个业务主库 1.利用备份建立三个新过滤复制从库+从库slave 2.业务读流量切换到三个过滤复制从库slaveA,slaveB,slaveC,观察读流量业务是否正常 - DBA做 - 有读写分离层:修改读写分离层配置(如:Proxysql) - 读写用域名分离:修改域名后的解析实例 - 业务做 - JDBC连接新域名-发布修改 3.业务切换写流量(一般JAVA业务开发现在MQ层消息缓存是标配) - 建立MQ消息机制缓存层(核心业务迁移,一条数据也不能丢失) - 切换前业务测试连接和消息写入是否正常 - 业务流量切换 - DBA做:切换上层写流量域名或者更改读写分离层配置 - 业务做:切换读流量域名 - 切换后,最直观的验证方法,在主节点观察连接数 show processlist; 制定用户流量是否进入 4. 业务流量验证,配合QA和业务开发观察业务测试和流量测试 ``` ## 1.3.双主复制 ### 1.3.1.企业级架构及应用场景 - 架构图-单流量接口写入 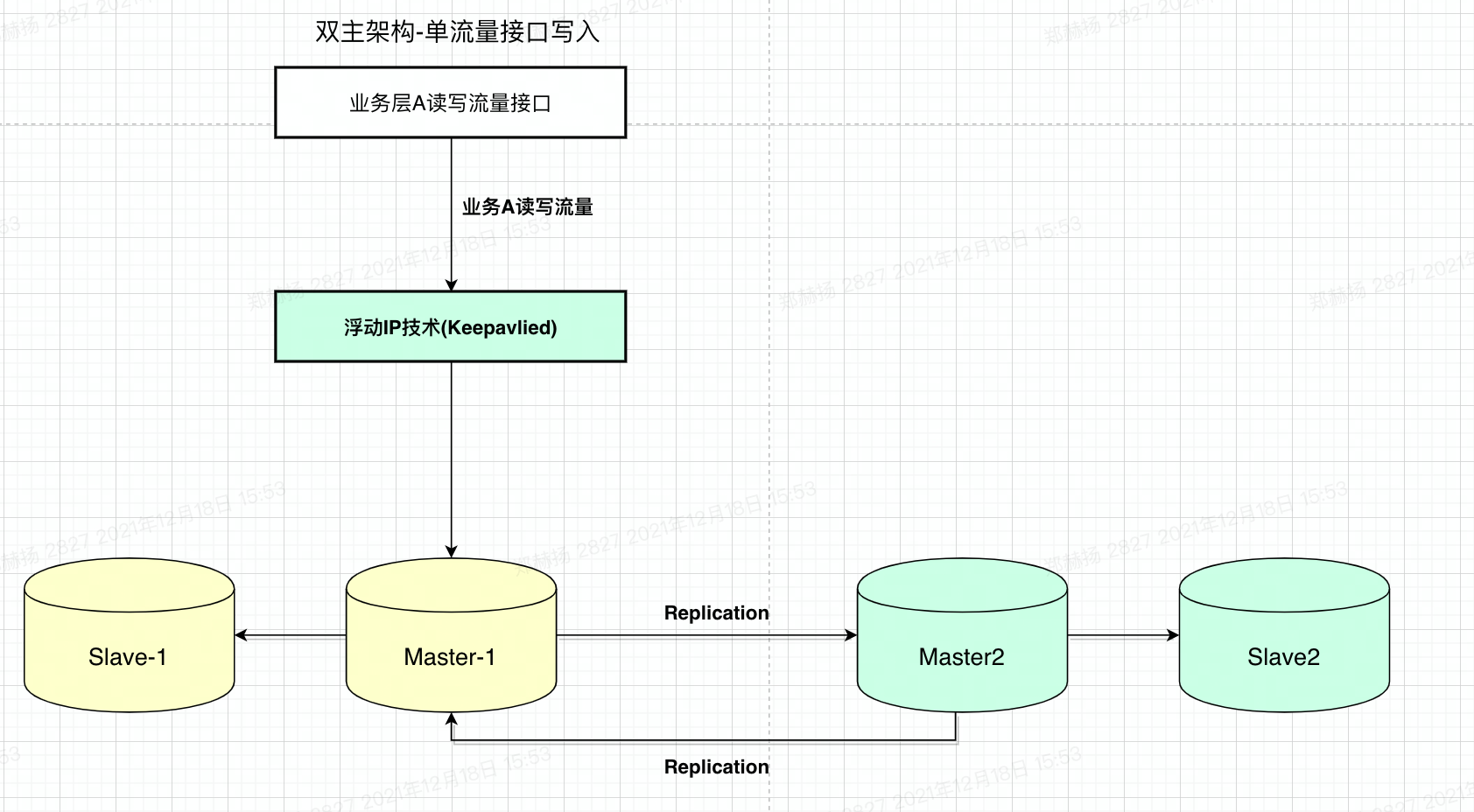 ```sql #1.介绍 双主复制: - 两个Master互为主备,任何一端写都会在另一端进行复制应用,适合中小层企业架构 - 这里仅提供单主流量写入架构,多主写入生产不推荐 #2.解决问题 1.主要目的是保证写的高可用(不用MHA等主从切换技术下) #3.注意事项-如果使用双主写入,核心防止更新冲突和插入冲突 1.尽量使用分布式全局ID,避免双主双写引发主键冲突(如果用双主双写就不要用自增ID) 2.都要开启slave-update参数 #4.搭建 从库使用 change master to master_host='172.21.188.36', MASTER_PORT=3306, master_user='repl', master_password='123' , MASTER_AUTO_POSITION=1; start slave; show slave status\G #keepalive搭建过程略 ``` ## 1.4.多源复制 - 架构图 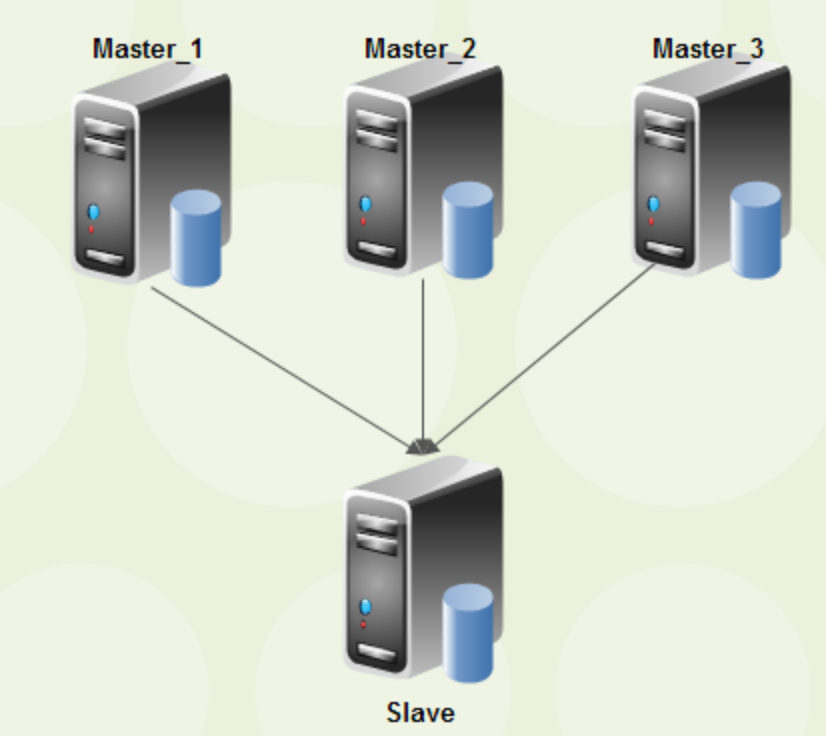 - 介绍 ```sql #1.介绍 1.5.7之后实现,多源复制,指上游多个Mysql可以指定同步到下游一个slave中 #2.应用场景 1.在slave服务器进行数据汇总方便做BI(后续TiDB课程项目有使用TiDB做多源复制) 2.集中备份:如果维护MySQL集群数量不是很多(几套)-可以用多源复制讲slave当成备份节点 ``` - 步骤 ```sql #从库执行-根据CHANNEL 进行主类别识别 CHANGE MASTER TO MASTER_HOST='10.0.0.51',MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_AUTO_POSITION=1 FOR CHANNEL 'Master_36'; CHANGE MASTER TO MASTER_HOST='10.0.0.52',MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_AUTO_POSITION=1 FOR CHANNEL 'Master_88'; start slave for CHANNEL 'Master_1'; start slave for CHANNEL 'Master_2'; ``` ## 1.5.企业级Mysql主从读写分离标准场景架构-不含中间件 - 架构图 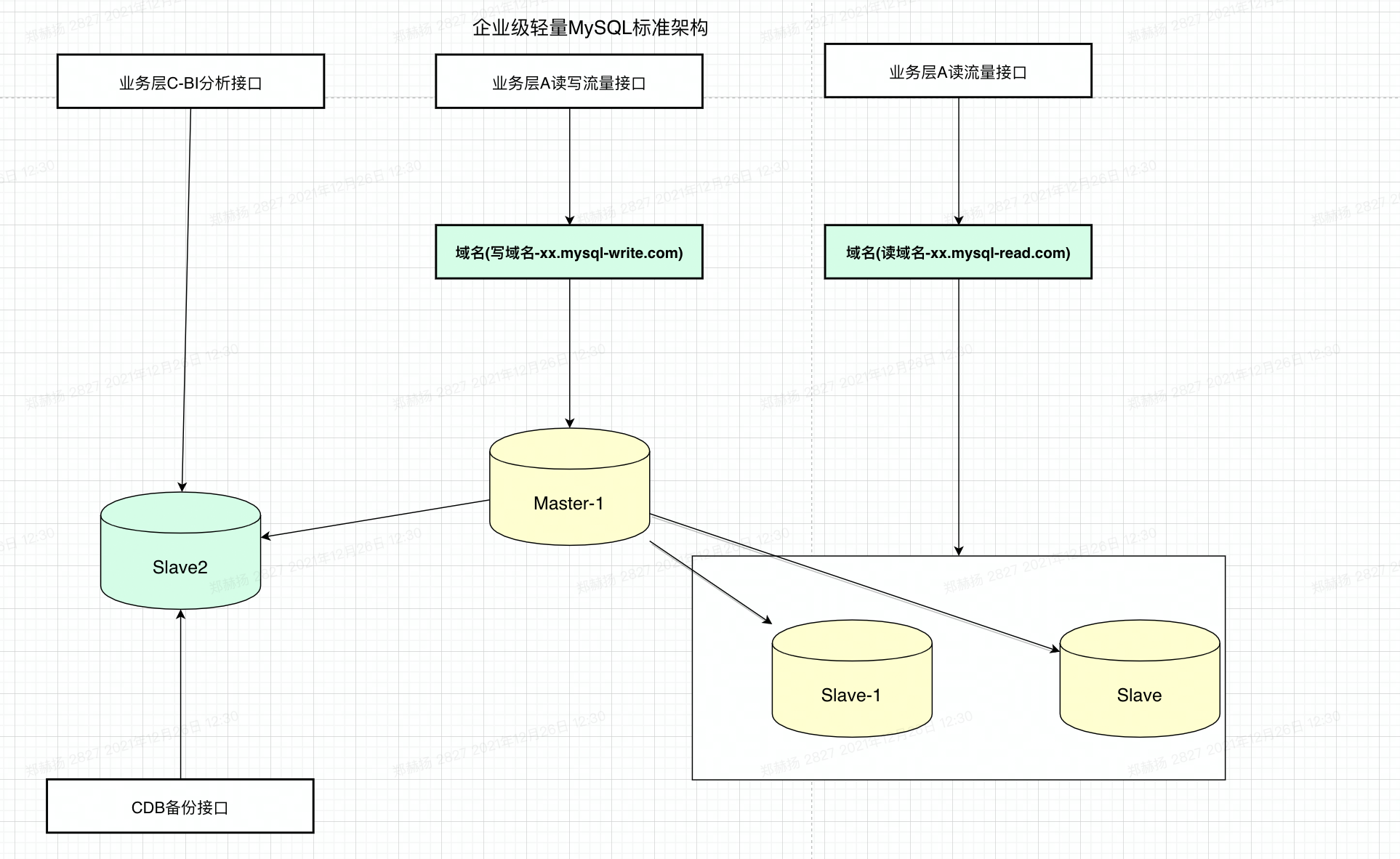 - 介绍 ```sql 1.主要功能 - 读写分离场景 - 主库承担写压力和部分业务延时要去为0的接口任务 - 对实时性要求在秒级读流量分发从库,降低主库压力 - 留出一个从库节点用作备份节点及BI分析 1.备份节点 - 不开二进制日志 - 开双一 - 不加入MHA高可用选主 2.主节点 - 开双一 3.从节点 - 如果对业务延时特别高建议增强半同步 ``` ## 1.6.跨地域热活MySQL实例架构 - 架构图 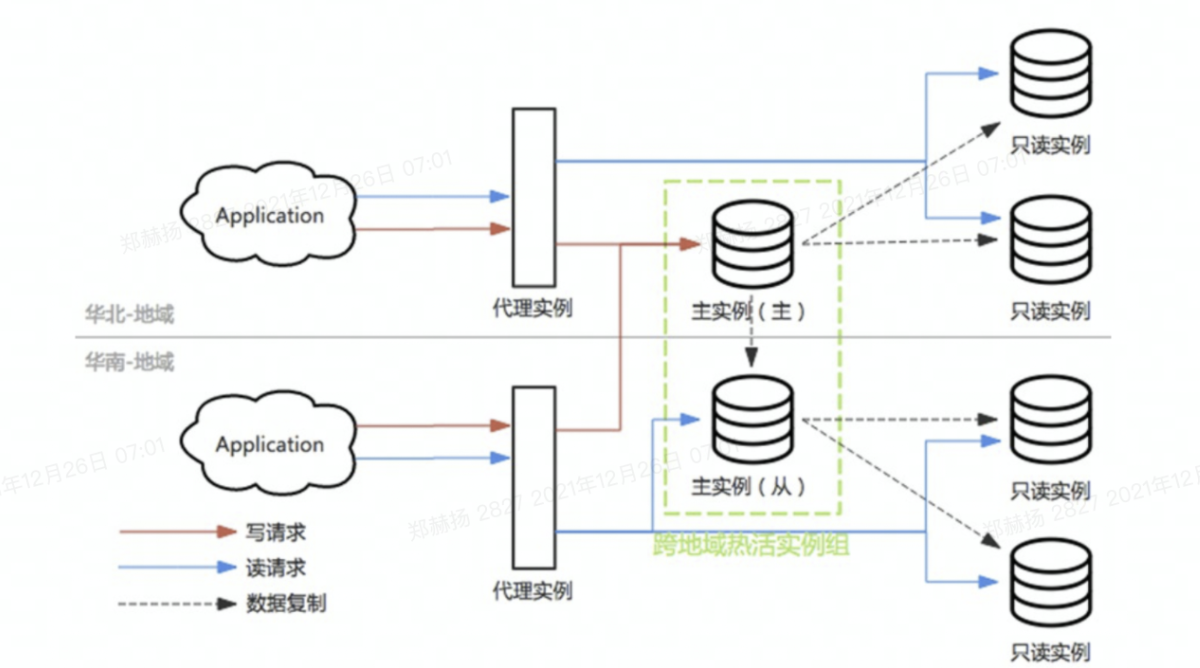 - 说明 ```sql - 异地双活架构 0.多个Mysql实例组成的高可用集群,允许实例分布在不同的地域和可用区,实现跨地域容灾 - 多地域代理实例最终写入一个主实例 1.技术体系:Mysql原生主从+级联主从+中间件 2.数据场景:数据强一致,延时不敏感(秒级),无法容忍数据丢失 - 数据Shard化,单元内的OLTP业务在单元内闭环 - 数据最终一致,延时敏感(秒级以下),可以容忍数据暂时丢 2.要求:异地之间延时影响为最大瓶颈障碍,如果是都是华北地区一般为10ms延时,华北华南-50-100ms不等 - 同地域延时1ms - 跨地域延时一般 距离/10KMs=网络往返延时(ms)计算: - 相邻两个城市大概200km距离,RTT~20ms,比如北京和保定服务相互交互延时在15ms - 边缘地区去到北上广数据中心的距离大概1000km以上,RTT~100ms ``` # 2.项目:MySQL线上版本热升级 55&56—>5.7.22(作业) ## 2.1.整体流程(架构版) 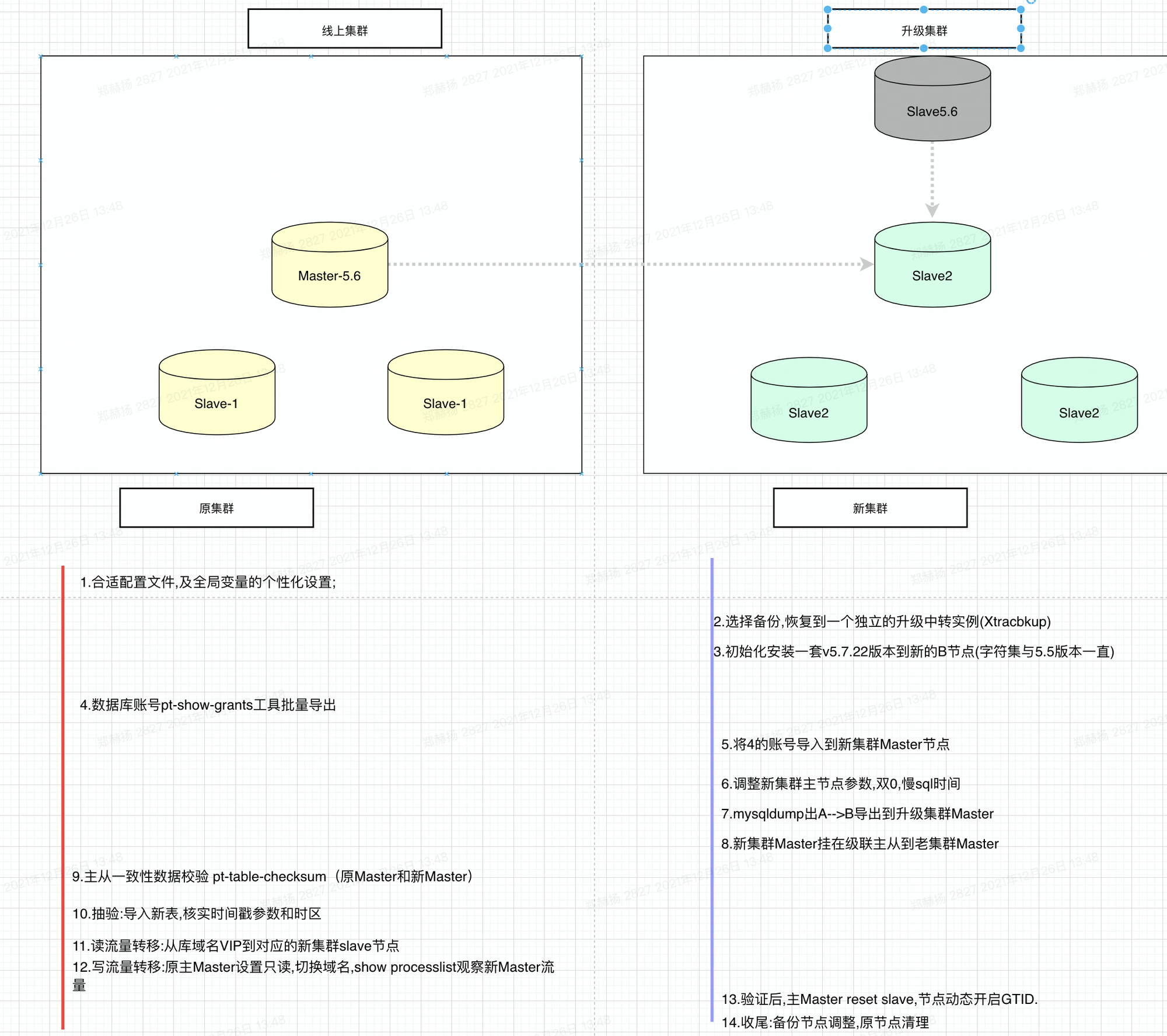 ## 2.2.整体流程(作业) ```sql 1.准备工作 - 与业务沟通jdbc驱动版本是否支持5722版本:连接配置加上"useSSL='true'",如:characterEncoding=utf8&useSSL=true - 自增ID从0开始的表,默认当前5.7版本是不支持的,需要提前沟通处理业务逻辑 - 与业务沟通确认,时间格式兼容问题:将日期、时间格式改成 '1000-01-01' 到 '9999-12-31'之间 - 注意核对原主库是否含有触发器、函数、存储过程、Event、外键等 - 触发器:use information_schema; select * from TRIGGERS; - 存储过程:select * from mysql.proc; - 查看event:use information_schema; select * from EVENTS; - 查看视图:use information_schema; select * from VIEWS; - 查看外键:SELECT * FROM information_schema.KEY_COLUMN_USAGE WHERE CONSTRAINT_NAME='FK_PRODUCT_ID'; - 保证源主库的binlog过期时间足够长,否则特大库还原后,找不到主库日志文件(比如之前为了节省空间改为3天) - show variables like '%expire%' - 核实配置文件,及全局环境变量是否有进行个性化设置,比如:大小写敏感参数,自增步长,半同步,查询缓存等等 - show variables like '%lower_case_table_names%'; - show variables like 'auto_inc%'; - show variables like '%rpl_semi_sync_master_enabled%'; - show variables like '%query_cache_type%'; 2.搭建数据中转节点(中转机,用来dump数据和恢复实例)-Xtrabackup 3.搭建新集群(一主2从或者2从) - install脚本初始化 57实例,字符集 引擎 和源库一致(作业) - 启动新集群构建主从 4.账号导出(pt-show-grants工具批量导出账号,注意密码字段authenticating_string) - 核实原主库账号授权:select user,host,password,authentication_string from mysql.user order by user; - pt工具导入账号 - 抽查核对业务账号 5.参数调整 - 新集群主节点开启二进制日志 - 核实配置文件 - 修改慢sql阈值 - 修改刷新和日志参数 6.同步数据 - 中转机导出主库数据到新集群 - 单库导入 mysqldump -uroot -p5c06a1b4101f083b -h127.0.0.1 -P3140 --single-transaction --default-character-set=utf8 -E --routines --triggers --max_allowed_packet=128M --set-gtid-purged=off --database schamea | mysql -uxx -h10.126.124.204 -P3140 -f - 多库并发导入 7.新集群复制原主机群(级联复制) - 找到全量数据点位(pos点位) - 新集群主节点挂在到原主上 - 数据一致性校验(pt-table-checksum) 8.正式切换 - 读域名或者流量验证(有proxy更改proxy配置) - 写流量迁移 - 老集群主节点打开read only - 新主flush logs - 新集群主节点赋予写域名,查看流量是否切入 - 切断新老主集群关系 - 打开新节点gtid #作业技术点 1.Xtrabackup备份还原 2.mysql集群主从搭建+级联主从(pos-->gtid模式) 3.pt工具pt-show-grants和pt-table-checksum学习与使用 ```
李延召
2024年4月16日 16:32
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码