DBA专题
DBA授课
DBA公开课
DBA训练营三天
01.Mysql基础入门-数据库简介
02.Mysql基础入门-部署与管理体系
03.MySQL主流版本版本特性与部署安装
04.Mysql-基础入门-用户与权限
05 MySQL-SQL基础2
06 SQL高级开发-函数
07 MySQL-SQL高级处理
08 SQL练习 作业
09 数据库高级开发2
10 Mysql基础入门-索引
11 Mysql之InnoDB引擎架构与体系结构
12 Mysql之InnoDB存储引擎
13 Mysql之日志管理
14 Mysql备份,恢复与迁移
15 主从复制的作用及重要性
16 Mysql Binlog Event详解
17 Mysql 主从复制
18 MySQL主从复制延时优化及监控故障处理
19 MySQL主从复制企业级场景解析
20 MySql主从复制搭建
21 MySQL高可用-技术方案选型
22 MySQL高可用-MHA(原理篇)
23 MySQL MHA实验
24 MySQL MGR
25 部署MySQL InnoDB Cluster
26 MySQL Cluster(MGR)
27 MySQL ProxySQL中间件
相信可能就有无限可能
-
+
首页
20 MySql主从复制搭建
# 一、MySQL主从复制之GTID ## 1.1 GTID的基本概念 GTID是全局事务标识符,是MySQL5.6版本开始在主从复制方面推出的重量级特性。 有了GTID,一个事务在集群中就不再孤单,在每一个节点中,都存在具有相同标识符的兄弟们 和它作伴,同一个事务,在同一个节点中出现多次的情况,也不会再复现了。GTID的出现,直 接的效果是,每一个事务在集群中具有了唯一性的意义,这在运维方面也有着重大的意义, DBA再也不需要为不断地找点而烦恼了。 ### 1.1.1 什么是GTID GTID的全称是Global Transaction Identifier ,是MySQL的一个强大的特性。MySQL会为每一 个DML/DDL操作都增加一个唯一标记,叫做GTID。这个标记在整个复制环境中都是唯一的。 也就是说我们每提交一个事务,当前执行线程就会拿到一个唯一标识符,此标识符不仅对执行该 事务的MySQL实例是唯一的,而且在给定的复制环境中所有的MySQL实例中也是唯一的。所有 事务与其GTID之间都是一一对应的。 ### 1.1.2 GTID的格式 ```sql GTID = source_id:sequence_id ``` GTID是由两部分组成,source_id和sequence_id。 source_id:是源服务器的唯一标识,通常使用服务器的server_uuid来表示source_id。 server_uuid存储在数据目录中的auto.cnf文件中。 sequence_id:是在事务提交时由系统顺序分配的一个序列号,相同source_id值的事务对应的 sequence_id在binlog文件中是递增且连续有序的。可以通过show master status或show slave status查看当前实例执行过的GTID信息,它以集合的方式呈现。 ```sql ## 查看mysql实例的server_uuid, 存储在数据目录中的auto.cnf文件中 mysql> select @@server_uuid; +--------------------------------------+ | @@server_uuid | +--------------------------------------+ | 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 | +--------------------------------------+ 1 row in set (0.00 sec) ## 查看mysql实例的gtid信息 mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000006 Position: 993 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1-4 1 row in set (0.00 sec) /** 其中本实例的server_uuid为18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6; 1-4代表第4个事务,即一共提交了4个事务。 如果提交了100个事务,GTID会是这样: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1-100 **/ ``` 解析binlog文件,可以看到,每个事务之前,都有一个GTID_log_event,用来指定GTID的值。 总体来看,一个MySQL binlog的格式大致如下: 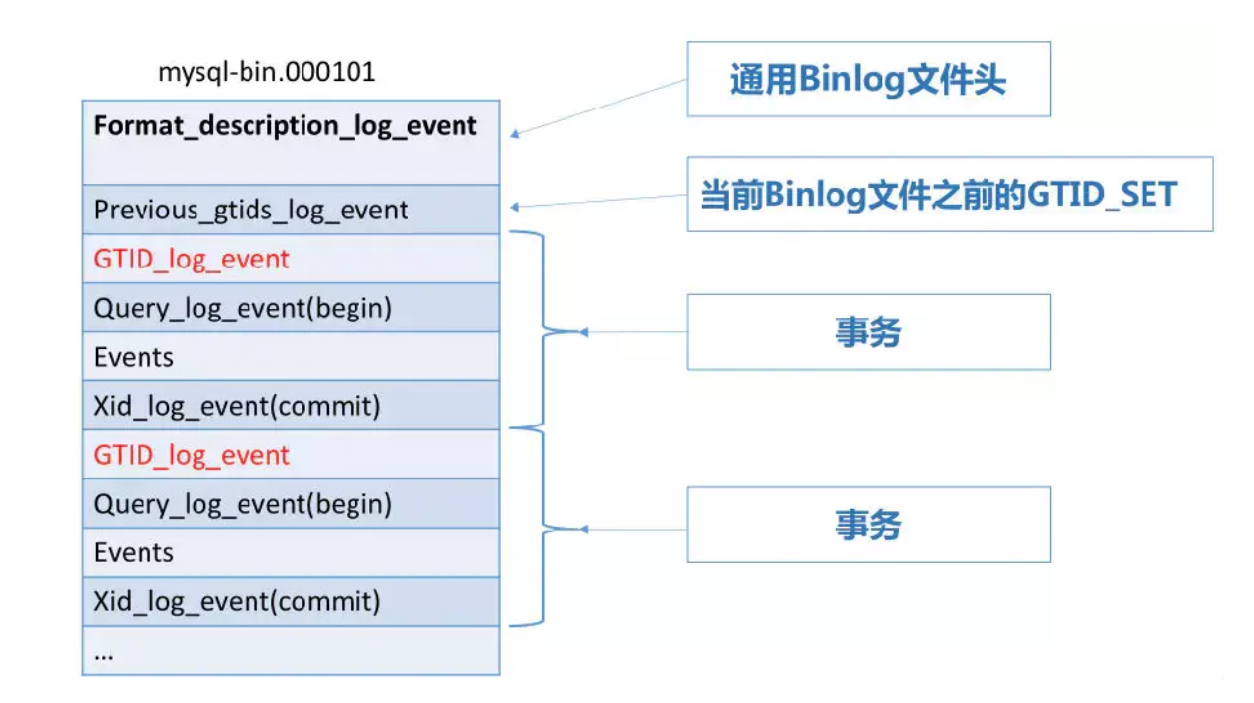 GTID在binlog中记录的形式: 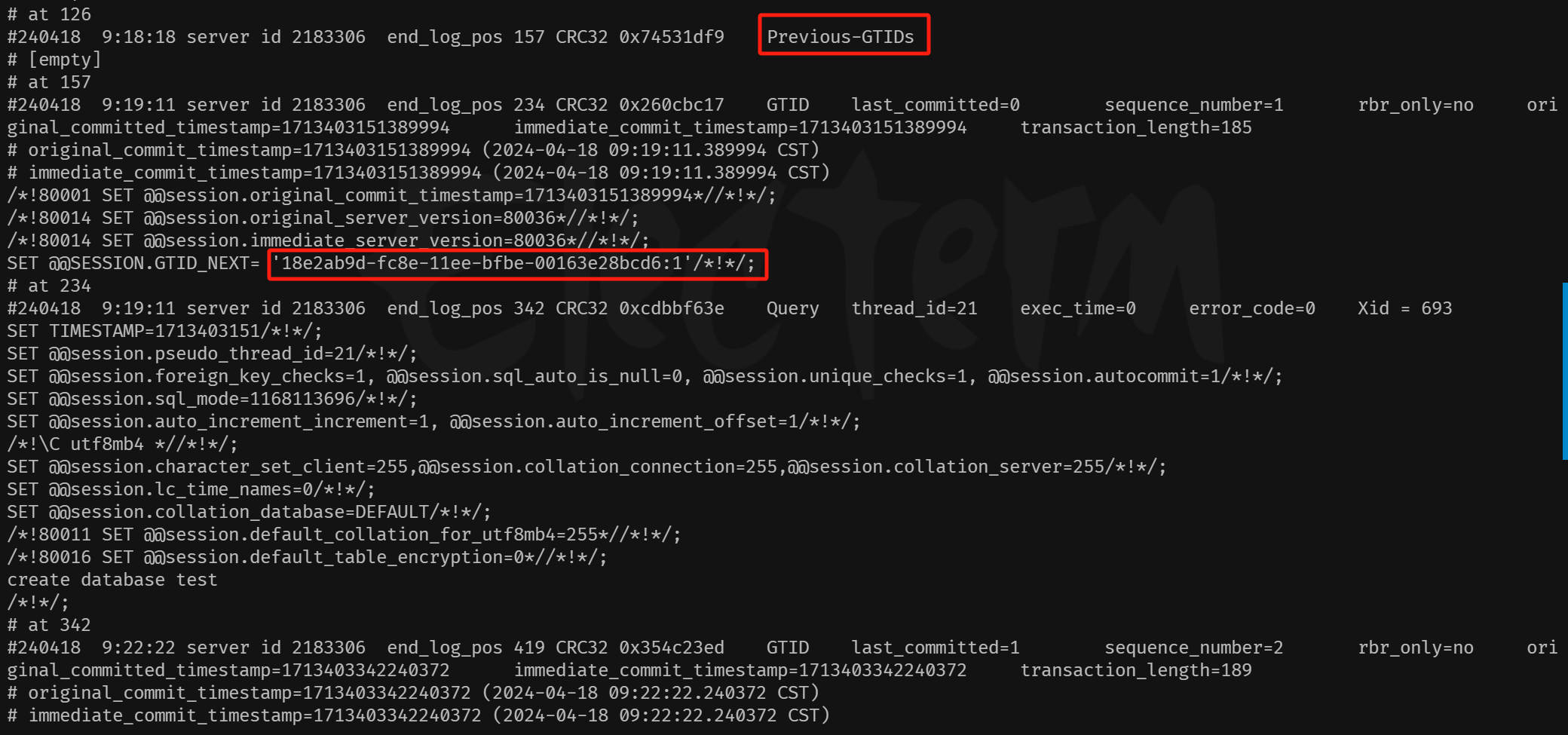 ### 1.1.3 GTID集合 GTID 集合是一组全局事务标识符,可以包含多个server_uuid,比如常见的gtid_executed变 量、gtid_purged变量就是一个gtid set。例如: ```sql 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1-9:15-20 #1-9:15-20表示有2个GTID SET区间,分别是1-9和15-20 ``` ## 1.2 为什么要有GTID? 在主从复制中,尤其是半同步复制中, 由于Master 的dump进程一边要发送binlog给Slave,一 边要等待Slave的ACK消息,这个过程是串行的,即前一个事物的ACK没有收到消息,那么后一 个事物只能排队候着; 这样将会极大地影响性能;有了GTID后,SLAVE就直接可以通过数据流 获得GTID信息,而且可以同步; 另外,主从故障切换中,如果一台MASTER down,需要提取拥有最新日志的SLAVE做 MASTER,这个是很好判断,而有了GTID,就只要以GTID为准即可方便判断;而有了GTID 后,SLAVE就不需要一直保存这bin-log 的文件名和Position了;只要启用 MASTER_AUTO_POSITION即可。 当MASTER crash的时候,GTID有助于保证数据一致性,因为每个事物都对应唯一GTID,如果 在恢复的时候某事物被重复提交,SLAVE会直接忽略; 从架构设计的角度,GTID是一种很好的分布式ID实践方式,通常来说,分布式ID有两个基本要求: 1)全局唯一性 2)趋势递增 这个ID因为是全局唯一,所以在分布式环境中很容易识别,因为趋势递增,所以ID是具有相应的 趋势规律,在必要的时候方便进行顺序提取。 GTID,其实是一种优雅的分布式设计。 ## 1.3 GTID有什么优缺点 ### 1.3.1 优点 ```sql 1. 根据GTID可以快速的知道事务最初是在哪个实例上提交的 2. 基于GTID搭建主从复制更加简单,确保每个事务只会被执行一次 3. 基于GTID复制,可以更方便的实现Replication的Failover。因为不用像传统复制那样去找master_log_file和master_log_pos。 4. GTID的引入,让每个事务在集群事务的海洋中有了秩序,使DBA在运维中做集群变迁时更加方便,能够做到心中有数 5. MySQL Group Replication的节点间复制完全依赖GTID,而且会使用GTID做冲突验证。 ``` ### 1.3.2 缺点 ```sql GTID的限制 1.不支持非事务引擎(从库报错,stop slave;start slave;忽略)。 2.不支持create table xxx select 语句复制(在8.0.21已经解决了)。 3.不允许一个SQL同时更新一个事务引擎和非事务引擎的表。 例如在同一个事务内先update innodb表,然后update myisam表。因为GTID强制每一个GTID对应一个事务,而在同一个事务内既操作innodb表又操作myisam,就会产生两个GTID. 4.在一个复制组中,必须要求统一开启GTID或者是关闭GTID。 5. < MySQL5.7.6版本,开启GTID需要重启。 6.开启GTID后,就不再使用原来的传统的复制方式。 7.对于create temporary table和drop temporary不允许在事务内执行,只有在事务以外并且autocommit=1才能正常执行; 8.不支持sql_slave_skip_counter,如果需要跳过事务,可以用以下方法: set @@session.gtid_next='需要跳过的事务gtid'; begin;commit; set session gtid_next=automatic; ``` ## 1.4 GTID生命周期 ```sql 1.master产生GTID 2.发送binlog信息到从库上 3.slave执行GTID 4.slave不生成GTID ``` 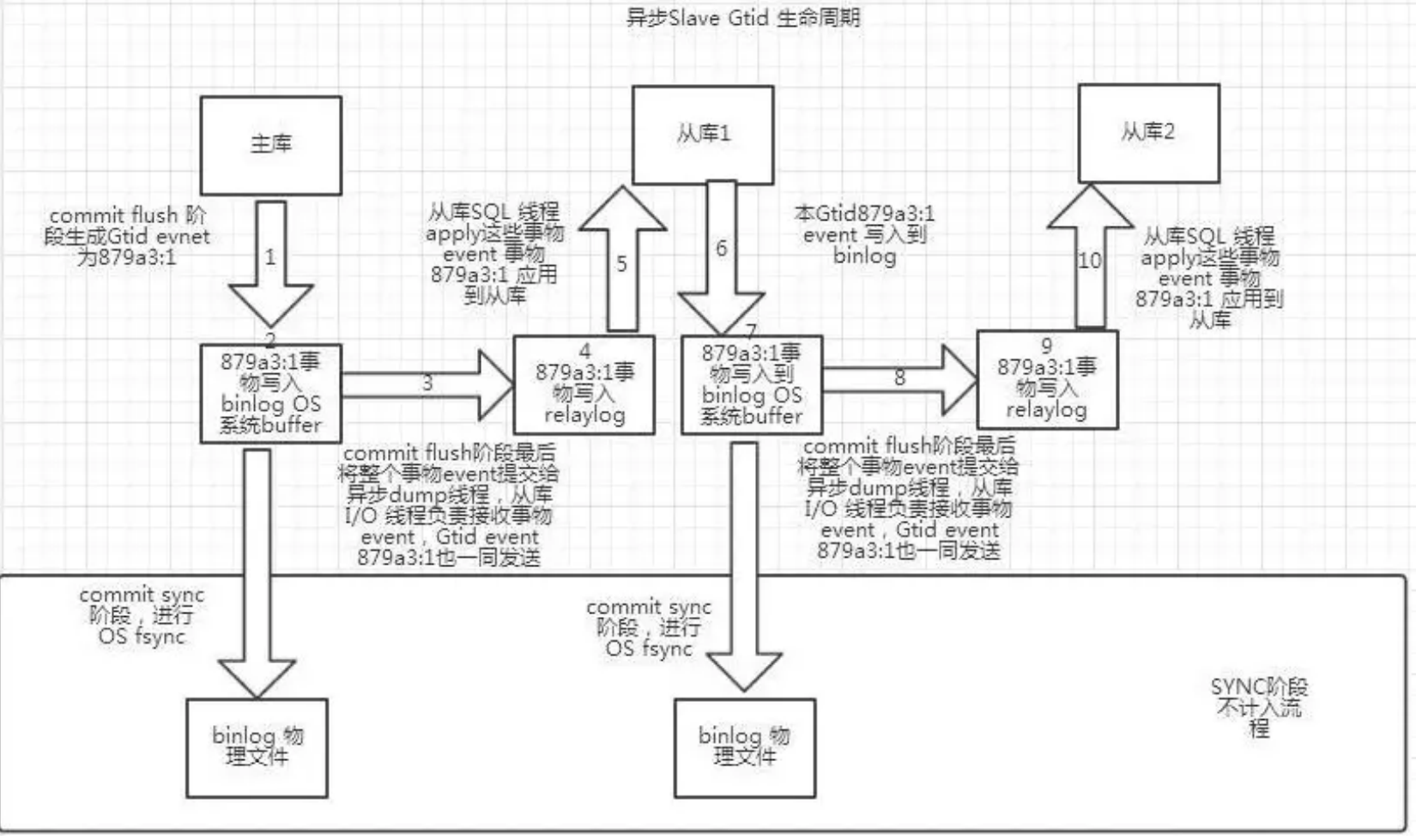 ## 1.5 GTID的维护 ### 1.5.1 gtid_executed表 在MySQL5.7.5版本及以上的版本中,mysql库中新增了表gtid_executed,表结构如下所示。该 表中的每一行表示一个gtid或gtid集合,包括server_uuid、集合开始和结束的事务ID。 ```sql mysql> show create table mysql.gtid_executed\G *************************** 1. row *************************** Table: gtid_executed Create Table: CREATE TABLE `gtid_executed` ( `source_uuid` char(36) NOT NULL COMMENT 'uuid of the source where the transaction was originally executed.', `interval_start` bigint NOT NULL COMMENT 'First number of interval.', `interval_end` bigint NOT NULL COMMENT 'Last number of interval.', PRIMARY KEY (`source_uuid`,`interval_start`) ) /*!50100 TABLESPACE `mysql` */ ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci STATS_PERSISTENT=0 ROW_FORMAT=DYNAMIC 1 row in set (0.00 sec) ``` 只有当gtid_mode为on或on_permissive时,gtid才会保持在mysql.gtid_gtid_executed表中。 GTID存储在该表中,不会考虑是否启用了二进制日志。 - 当未启用binlog时,每个事务都会记录在gtid_executed中; - 当启用binlog时,每个事务不仅会记录在gtid_executed中,而且当binlog Rotate或服务器 关闭时,服务器会将GTID信息写入新的二进制日志。如果服务器异常关闭,GTID不会被存 入mysql.gtid_gtid_executed表中,那么在这种情况下,MySQL在恢复时,会将这些GTID 信息添加到表中,并写入gtid_executed系统变量中。 - reset master操作会清空mysql.gtid_gtid_executed表。 ### 1.5.2 gtid_executed表压缩 随着数据库的不断更新,mysql.gtid_gtid_executed会存入很多GTID信息,并且这些事务ID会构 成一个序列,如下: ```sql mysql> select * from mysql.gtid_executed; +--------------------------------------+----------------+--------------+ | source_uuid | interval_start | interval_end | +--------------------------------------+----------------+--------------+ | 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 | 1 | 1 | | 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 | 2 | 2 | | 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 | 3 | 3 | | 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 | 4 | 4 | +--------------------------------------+----------------+--------------+ 4 rows in set (0.00 sec) ``` 可以通过事务的间隔来代替原来的每个GTID信息,来缩减磁盘空间的消耗。 当MySQL启用GTID的时候,服务器会定期对mysql.gtid_executed表执行此类型的压缩,可以 通过设置gtid_executed_compression_period变量来控制在压缩表之前允许的事务数,从而控制压缩率。该变量的默认值是1000,表示表的压缩在1000个事务之后执行,设置为0表示不执 行压缩。 ```sql #测试:调整为10 SET GLOBAL gtid_executed_compression_period = 10; ``` **注意**:当Binlog开启,且gtid_executed_compression_period=0时,MySQL的Binlog轮换会 引起 mysql.gtid_executed的自动压缩。 MySQL中有一个单独的后台线程来执行gtid_executed表的压缩操作。线程信息如下: ```sql mysql> select * from performance_schema.threads where name like '%compress_gtid%'\G *************************** 1. row *************************** THREAD_ID: 46 NAME: thread/sql/compress_gtid_table TYPE: FOREGROUND PROCESSLIST_ID: 7 PROCESSLIST_USER: NULL PROCESSLIST_HOST: NULL PROCESSLIST_DB: NULL PROCESSLIST_COMMAND: Daemon PROCESSLIST_TIME: 81228 PROCESSLIST_STATE: Suspending PROCESSLIST_INFO: NULL PARENT_THREAD_ID: 1 ROLE: NULL INSTRUMENTED: YES HISTORY: YES CONNECTION_TYPE: NULL THREAD_OS_ID: 91346 RESOURCE_GROUP: SYS_default EXECUTION_ENGINE: PRIMARY CONTROLLED_MEMORY: 8240 MAX_CONTROLLED_MEMORY: 8240 TOTAL_MEMORY: 14424 MAX_TOTAL_MEMORY: 14488 TELEMETRY_ACTIVE: NO 1 row in set (0.00 sec) #该线程睡眠直到执行了gtid_executed_compression_period个事务后,唤醒该线程执行gtid_executed表的压缩,然后继续睡眠,如此循环。当禁用binlog日志并且设置gtid_executed_compression_period=0时,该线程永远不会被唤醒。 mysql> use mysql Database changed mysql> SHOW TABLE STATUS WHERE Name = 'gtid_executed'\G *************************** 1. row *************************** Name: gtid_executed Engine: InnoDB Version: 10 Row_format: Dynamic Rows: 31 Avg_row_length: 528 Data_length: 16384 Max_data_length: 0 Index_length: 0 Data_free: 5242880 Auto_increment: NULL Create_time: 2024-04-17 15:42:54 Update_time: 2024-04-18 15:54:35 Check_time: NULL Collation: utf8mb4_0900_ai_ci Checksum: NULL Create_options: row_format=DYNAMIC stats_persistent=0 Comment: 1 row in set (0.00 sec) # mysql 8.0.36 默认禁用 mysql> show VARIABLES like '%gtid_executed_compression_period%'; +----------------------------------+-------+ | Variable_name | Value | +----------------------------------+-------+ | gtid_executed_compression_period | 0 | +----------------------------------+-------+ 1 row in set (0.01 sec) mysql> SET GLOBAL gtid_executed_compression_period = 1; Query OK, 0 rows affected (0.00 sec) mysql> show VARIABLES like '%gtid_executed_compression_period%'; +----------------------------------+-------+ | Variable_name | Value | +----------------------------------+-------+ | gtid_executed_compression_period | 1 | +----------------------------------+-------+ 1 row in set (0.00 sec) 使设置持久化 如果你希望新值在服务器重启后仍然有效,可以使用SET PERSIST命令(MySQL 8.0及更高版本): SET PERSIST gtid_executed_compression_period = 500; 这会将新值保存在mysqld-auto.cnf文件中,以便在服务器重启后自动加载。 ``` # 二、Mysql主从复制搭建 ## 2.1 传统的主从复制  ```bash 要实现主从复制,需要如下几步: 1. 在主库上启用binlog 2.在主库上创建一个用于复制的账号。 3.在从库上设置唯一的server_id 4.搭建从库. - 备份数据(点位或gtid) - 逻辑备份mysqldump - xtrabackup - 拷贝主库的数据目录 - 空库搭建 5.配置主从复制(DBA命令 change master) 6.开启主从复制(start slave) 7.查看复制状态(show slave status) 8.监控复制流程(监控+报警) ``` ### 2.1.1 机器列表 | ip | 端口 | 角色 | 版本 | | ---------- | ---- | ------ | ------ | | 10.0.0.218 | 3306 | master | 8.0.36 | | 10.0.0.217 | 3306 | slave | 8.0.36 | ### 2.1.2 初始环境准备 - 10.0.0.218-master ```bash # 如果是阿里云的Ubuntu 需要卸载 sudo apt-get remove --purge mysql-server mysql-client mysql-common root@db01:~# apt install wget -y root@db01:~# cd /usr/local/src/ root@db01:/usr/local/src# wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-8.0.36-linux-glibc2.28-x86_64.tar.xz 1.解压 root@db01:/usr/local/src# tar xf mysql-8.0.36-linux-glibc2.28-x86_64.tar.xz --可直接用最新版本 2.软连接 root@db01:/usr/local/src# ln -s /usr/local/src/mysql-8.0.36-linux-glibc2.28-x86_64 /opt/mysql-8.0.36 3. 环境清理(centos7 清理,Ubuntu 忽略如下两步) root@db01:/usr/local/src# yum remove -y mariadb-libs # 忽略 root@db01:/usr/local/src# yum install -y libaio-devel # 忽略 4. 创建用户 root@db01:/usr/local/src# useradd mysql 5. 创建目录 root@db01:/usr/local/src# mkdir -p /data/mysql3306/{log,etc,tmp,data} 6. 授权 root@db01:/usr/local/src# chown -R mysql.mysql /data/mysql3306/ 7. 初始化数据 root@db01:/usr/local/src# echo 'export PATH=/opt/mysql-8.0.36/bin:$PATH' >> /etc/profile root@db01:/usr/local/src# source /etc/profile root@db01:/usr/local/src# mysqld --initialize-insecure --user=mysql --basedir=/opt/mysql-8.0.36/ --datadir=/data/mysql3306/data/ 8. 配置文件 root@db01:/usr/local/src# cat > /data/mysql3306/etc/my.cnf <<EOF [client] port = 3306 socket = /data/mysql3306/tmp/mysql.sock #default_character_set = utf8mb4 [mysqld] user= mysql port = 3306 server_id = 2183306 #character-set-server = utf8mb4 datadir = /data/mysql3306/data socket = /data/mysql3306/tmp/mysql.sock log_error = /data/mysql3306/log/mysql.err pid_file = /data/mysql3306/data/mysql.pid slow-query-log slow_query_log_file = /data/mysql3306/log/slowquery.log tmpdir = /data/mysql3306/tmp/ log_bin = /data/mysql3306/log/mysql-bin #replication binlog_format = row binlog_row_image = full expire_logs_days = 10 relay-log = /data/mysql3306/log/relay-log slave_net_timeout = 30 #skip-slave-start slave-parallel-workers = 0 relay_log_info_repository = TABLE master_info_repository = TABLE sync_binlog = 1 EOF root@db01:/usr/local/src# touch /data/mysql3306/log/mysql.err root@db01:/usr/local/src# chown -R mysql.mysql /data/mysql3306 9. 启动数据库 #启动方式一: root@db01:/usr/local/src# mysqld_safe --defaults-file=/data/mysql3306/etc/my.cnf --user=mysql & #启动方式二: # 这种方法的话需要把my.cnf 配置文件放在/etc/my.cnf root@db01:/opt/mysql-8.0.36/support-files# tree . ├── mysql.server └── mysqld_multi.server root@db01:/opt/mysql-8.0.36/support-files# vim mysql.server # 编辑下面两个路径 basedir=/opt/mysql-8.0.36 datadir=/data/mysql3306/data root@db01:/opt/mysql-8.0.36/support-files# cp mysql.server /etc/init.d/mysqld root@db01:~# systemctl daemon-reload # 看情况执行 root@db01:/opt/mysql-8.0.36/support-files# systemctl start mysqld 10.连接数据库 root@db01:~# mysql -uroot -p -S /tmp/mysql.sock #端口连接 root@db01:~# mysql -uroot -p -hlocalhost -P 3306 #TCP链接 11.关闭数据库 mysqladmin shutdown -S /tmp/mysql.sock root@db01:~# systemctl stop mysqld # 命令补全 root@db01:~# apt-get install bash-completion ---------------------------------可忽略----------------------------------------------- #主库修改密码 set password=password('123456'); GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' identified by '000000' WITH GRANT OPTION; flush privileges; ------------------------------------------------------------------------------------- ``` - 10.0.0.217-slave ```bash root@db02:~# cd /usr/local/src/ root@db02:/usr/local/src# wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-8.0.36-linux-glibc2.28-x86_64.tar.xz root@db02:/usr/local/src# tar xf mysql-8.0.36-linux-glibc2.28-x86_64.tar.xz root@db02:/usr/local/src# ln -s /usr/local/src/mysql-8.0.36-linux-glibc2.28-x86_64 /opt/mysql-8.0.36 root@db02:/usr/local/src# useradd mysql -s /usr/bin/nologin root@db02:/usr/local/src# mkdir -p /data/mysql3306/{log,etc,tmp,data} root@db02:/usr/local/src# chown -R mysql.mysql /data/mysql3306/ root@db02:/usr/local/src# echo 'export PATH=/opt/mysql-8.0.36/bin:$PATH' >> /etc/profile root@db02:/usr/local/src# source /etc/profile root@db02:/usr/local/src# mysqld --initialize-insecure --user=mysql --basedir=/opt/mysql-8.0.36/ --datadir=/data/mysql3306/data/ #从库(db02),10.0.0.217: root@db02:/usr/local/src# cat > /data/mysql3306/etc/my.cnf <<EOF [client] port = 3306 socket = /data/mysql3306/tmp/mysql.sock [mysqld] user= mysql port = 3306 server_id = 2173306 datadir = /data/mysql3306/data socket = /data/mysql3306/tmp/mysql.sock log_error = /data/mysql3306/log/mysql.err pid_file = /data/mysql3306/data/mysql.pid slow-query-log slow_query_log_file = /data/mysql3306/log/slowquery.log tmpdir = /data/mysql3306/tmp/ log_bin = /data/mysql3306/log/mysql-bin #replication binlog_format = row binlog_row_image = full expire_logs_days = 10 relay-log = /data/mysql3306/log/relay-log slave_net_timeout = 30 #skip-slave-start slave-parallel-workers = 0 relay_log_info_repository = TABLE master_info_repository = TABLE sync_binlog = 1 #gtid #gtid_mode = ON #enforce-gtid-consistency = ON #log-slave-updates = ON EOF root@db02:/usr/local/src# touch /data/mysql3306/log/mysql.err root@db02:/usr/local/src# chown -R mysql.mysql /data/mysql3306 root@db02:~# scp /etc/init.d/mysqld root@10.0.0.217:/etc/init.d/ root@10.0.0.217's password: mysqld 100% 10KB 16.5MB/s 00:00 root@db02:/usr/local/src# ll /etc/init.d/mysqld -rwxr-xr-x 1 root root 10613 Apr 17 14:18 /etc/init.d/mysqld* root@db02:/usr/local/src# /etc/init.d/mysqld start Starting mysqld (via systemctl): mysqld.service. ---------------------------------可忽略----------------------------------------------- #主库修改密码 set password=password('123456'); GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' identified by '000000' WITH GRANT OPTION; flush privileges; ------------------------------------------------------------------------------------- ``` ### 2.1.3 主从复制重要参数 ```bash server_id:每个实例不能一直 #gtid_mode: on #enforce_gtid_consistency: on log-bin:主库必须开启 log-slave-updates=1从库建议开启(用来备份) binlog_format= ROW skip-slave-start=1 #说明: 在5.6版本开启GTID时必须开启log-slave-updates,因为GTID相关信息是存放在内存的,重启以后就丢失了,必须要从binlog里找到最新应用到的GTID; 在5.7版本由于引入了mysql.gtid_executed表,GTID信息存放在这个数据表里,那么重启之后就不再需要去读取binlog来获取GTID相关信息了。同时通过gtid_executed_compression_period参数控制执行了多少个事务以后,对mysql.gtid_executed表进行压缩,以免大量的GTID信息占用过多存储空间。 ``` ### 2.1.4 搭建步骤(基于file、pos): ```sql 1. 在主库上,启用binlog并设置server_id。 mysql> select @@server_id; +-------------+ | @@server_id | +-------------+ | 2183306 | +-------------+ 1 row in set (0.00 sec) 2.在主库上,创建一个复制用户,从库使用此账户连接到主库 mysql> create user 'repl'@'10.0.0.%' identified WITH mysql_native_password BY '000000'; Query OK, 0 rows affected (0.00 sec) mysql> grant replication slave on *.* to 'repl'@'10.0.0.%'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) 3.在从库上,设置唯一的server_id选项(必须与主库不同) mysql> select @@server_id; +-------------+ | @@server_id | +-------------+ | 2173306 | +-------------+ 1 row in set (0.00 sec) 4.在主库上创建用户 mysql> create user sunrise@'%' identified by '123456'; Query OK, 0 rows affected (0.01 sec) mysql> grant all privileges on *.* to 'sunrise'@'%' WITH GRANT OPTION; Query OK, 0 rows affected (0.01 sec) 5.在从库上,通过远程连接从主库进行备份 root@db02:/data/download# mysqldump -usunrise -h10.0.0.218 -P 3306 -p123456 --set-gtid-purged=off --single-transaction --default-character-set=utf8mb4 --all-databases --master-data=2 > sunrise-test.sql root@db02:/data/download# ls sunrise-test.sql #从另一个从库备份时,必须设置slave-dump root@db02:/data/download# grep "\--\ CHANGE MASTER" sunrise-test.sql -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=1878; 6.在从库上,恢复备份文件sunrise-test.sql root@db02:/data/download# mysql -uroot -p < sunrise-test.sql 7.在从库上,配置主从复制 mysql> reset master; Query OK, 0 rows affected (0.00 sec) mysql> stop slave; Query OK, 0 rows affected, 2 warnings (0.00 sec) mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.218',master_port=3306, MASTER_USER='repl', MASTER_PASSWORD='000000', MASTER_Log_file='mysql-bin.000003',master_log_pos=1878; Query OK, 0 rows affected, 9 warnings (0.01 sec) 8.开启主从复制(start slave) mysql> start slave; Query OK, 0 rows affected, 1 warning (0.00 sec) 9.查看复制状态(show slave status) mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for source to send event Master_Host: 10.0.0.218 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000003 Read_Master_Log_Pos: 1878 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 326 Relay_Master_Log_File: mysql-bin.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 1878 Relay_Log_Space: 530 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 2183306 Master_UUID: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 Master_Info_File: mysql.slave_master_info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: Master_public_key_path: Get_master_public_key: 0 Network_Namespace: 1 row in set, 1 warning (0.00 sec) ``` ### 2.1.5 复制环境管理命令 show slave status命令的输出信息,对于我们了解slave当前状态非常重要,本命令几乎是 mysql复制环境管理中最为常用的命令,输出信息中参数较多,具体的含义我们来详细了解下: ```sql 1. Slave_IO_State: Waiting for master to send event显示slave的当前状态, 状态信息和使用show processlist显示的内容一样。 slave I/O线程的状态,有以下几种: (1) waiting for master update 这是connecting to master状态之前的状态 (2) connecting to master I/O线程正尝试连接到master (3) checking master version 在与master建立连接后,会出现该状态。该状态出现的时间非常短暂。 (4) registering slave on master 在与master建立连接后,会出现该状态。该状态出现的时间非常短暂。 (5) requesting binlog dump在与master建立连接后,会出现该状态。该状态出现的时间非常短暂。在这个状态下,I/O线程向master发送请求,请求binlog,位置从指定的binglog 名字和binglog的position位置开始。 (6) waiting to reconnect after a failed binlog dump request (7) reconnecting after a failed binglog dump request I/O进程正在尝试连接master (8) waiting for master to send event 说明,已经成功连接到master,正等待二进制日志时间的到达。如果master 空闲,这个状态会持续很长时间。如果等待的时间超过了slave_net_timeout(单位是秒)的值,会出现连接超时。在这种状态下,I/O线程会人为连接失败,并开始尝试重连 (9) queueing master event to the relay log 此时,I/O线程已经读取了一个event,并复制到了relay log 中。这样SQL 线程可以执行此event (10) waiting to reconnect after a failed master event read 读取时出现的错误(因为连接断开)。在尝试重连之前,I/O线程进入sleep状态,sleep的时间是master_connect_try的值(默认是60秒) (11) reconnecting after a failed master event read I/O线程正尝试重连master。如果连接建立,状态会变成"waiting for master to send event" (12) waiting for the slave sql thread to free enough relay log space 这是因为设置了relay_log_space_limit,并且relay log的大小已经整张到了最大值。I/O线程正在等待SQL线程通过删除一些relay log,来释放relay log的空间。 (13) waiting for slave mutex on exit I/O线程停止时会出现的状态,出现的时间非常短。 2. Master_Host: 10.0.0.218 Master_User: repl Master_Port: 3306 这3条信息,显示了slave连接master时,使用的master的主机---master_host、连接master用的用户---master_user、连接master的端口---master_port。 3. Connect_Retry: 10 连接中断后,重新尝试连接的时间间隔。默认值是60秒。 4. Master_Log_File: mysql-bin.000003 Read_Master_Log_Pos: 1817 这两条信息,显示了与master相关的日志的信息。 master_log_file:当前I/O线程正在读取的master 二进制日志的文件名; read_master_log_pos:当前I/O线程正在读取的二进制日志的位置 5. Relay_Log_File: relay-log.000002 Relay_Log_Pos: 326 Relay_Master_Log_File: mysql-bin.000003 这3条信息,显示了与relay log相关的信息。 relay_log_file:当前SQL线程正在读取并执行的relay log的文件名; relay_log_pos:当前SQL线程正在读取并执行的relay log文件的位置; relay_master_log_file:master 二进制日志的文件名。该文件包含当前SQL执行的事物 6. Slave_IO_Running: 显示I/O线程是否在运行,正常情况下应该在运行,除非dba手动将其停止,或者出现错误 7. Slave_SQL_Running: 显示SQL线程是否在运行,正常情况下应该在运行,除非dba手动将其停止,或者出现错误 8. Last_IO_Error/Last_SQL_Error: 正常情况下应该是空值,如果遇到了错误,那么在这里就会输出错误信息,而后DBA可以根据错误提示分析和处理。能够抓到明确的错误信息,就比较好处理了。 9. Replicate_Do_DB: #指定复制的库 Replicate_Ignore_DB: #指定忽略的库 Replicate_Do_Table: #指定复制的表 schame_a.table_a Replicate_Ignore_Table: #忽略指定表 Replicate_Wild_Do_Table: #复制指定的A.b%(支持通配符) Replicate_Wild_Ignore_Table: #忽略指定的表(支持通配符) 注意: 设置replicate_do_db或replicate_ignore_db后,MySQL执行sql前检查的是当前默认数据库,所以跨库更新语句在Slave上会被忽略。 可以在Slave上使用 replicate_wild_do_table 和 replicate_wild_ignore_table 来解决跨库更新的问题,如: replicate_wild_do_table=test.% replicate_wild_ignore_table=mysql.% 10.Until_Condition: None Until_Log_File: Until_Log_Pos: 0 在START SLAVE语句的UNTIL子句中指定的值。 Until_Condition具有以下值: (1) 如果没有指定UNTIL子句,则没有值 (2) 如果从属服务器正在读取,直到达到主服务器的二进制日志的给定位置为止,则值为Master (3) 如果从属服务器正在读取,直到达到其中继日志的给定位置为止,则值为Relay Until_Log_File和Until_Log_Pos用于指示日志文件名和位置值。日志文件名和位置值定义了SQL线程在哪个点中止执行。 11. Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Master_SSL_Verify_Server_Cert: No Master_SSL_Crl: Master_SSL_Crlpath: 这些字段显示了被从属服务器使用加密相关的参数。这些参数用于连接主服务器。 Master_SSL_Allowed具有以下值: (1) 如果允许对主服务器进行SSL连接,则值为Yes (2) 如果不允许对主服务器进行SSL连接,则值为No (3) 如果允许SSL连接,但是从属服务器没有让SSL支持被启用,则值为Ignored。 与SSL有关的字段的值对应于–master-ca,–master-capath,–master-cert,–master-cipher和–master-key选项的值。 12. Seconds_Behind_Master 这个值是时间戳的差值。是slave当前的时间戳和master记录该事件时的时间戳的差值。 13. Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates SQL线程运行状态: (1) Reading event from the relay log 线程已经从中继日志读取一个事件,可以对事件进行处理了。 (2) Slave has read all relay log; waiting for more updates 线程已经处理了中继日志文件中的所有事件,现在正等待I/O线程将新事件写入中继日志。 (3) Waiting for slave mutex on exit 线程停止时发生的一个很简单的状态。 #GTID模式相关 14. Retrieved_Gtid_Set:获取到的GTID<IO线程> 15. Executed_Gtid_Set:执行过的GTID<SQL线程> ``` ### 2.1.6 跳过事务的方式 ```bash #跳过事务,N代表N个event, n=1 跳过下一个事务 n>1,从当前位置跳过N个event,如果跳到一个事务中,则跳过该事务进行复制. set global sql_slave_skip_counter=N ``` ## 2.2 由传统复制变为GTID复制 ```sql 前提: 1.要求所有的mysql版本5.7.6或更高的版本。 2.目前拓扑结构中所有的mysql的gtid_mode的值为off状态。 3.如下的操作步骤都是有序的,不要跳跃着进行。 全局系统变量GTID_MODE变量值说明: OFF:M上新事务是非GTID,Slave只接受不带GTID的事务,传送来GTID的事务会报错 OFF_PERMISSIVE:M上新事务是非GTID, S即接受不带GTID的事务也接受带GTID的事务 ON_PERMISSIVE:M上新事务是GTID, S即接受不带GTID的事务也接受带GTID的事务 ON :M上新事务是GTID, Slave只接受带GTID的事务,在开启此步骤前,保证基于file和pos点的复制完成,没有落后 需要注意的是,这几个值的改变是有顺序的,即 off<--->OFF_PERMISSIVE<--->ON_PERMISSIVE<--->ON 不能跳跃执行,会报错。 ``` ### 2.2.1 操作步骤 ```sql #步骤 1 在M、S实例上,将ENFORCE_GTID_CONSISTENCY设置为warning,哪台先执行不影响结果 M:mysql> set @@global.enforce_gtid_consistency=warn; S:mysql> set @@global.enforce_gtid_consistency=warn; 注意:执行完这条语句后,如果出现GTID不兼容的语句用法,在错误日志会记录相关信息,那么需要调整应该程序避免不兼容的写法,直到完全没有产生不兼容的语句,可以通过应该程序去排查所有的sql,也可以设置后观察错误日志一段时间,这一步非常重要。 #步骤 2 在M、S上,设置ENFORCE_GTID_CONSISTENCY为ON,哪台先执行不影响结果 M:mysql> set @@global.enforce_gtid_consistency=on; S:mysql> set @@global.enforce_gtid_consistency=on; #步骤 3 在M、S实例上,设置GTID_MODE为off_permissiv;哪台先执行不影响结果 M:mysql> SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE; S:mysql> SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE; #步骤 4 在M、S实例上,设置GTID_MODE为on_permissiv;哪台先执行不影响结果 M: Mysql> SET @@GLOBAL.GTID_MODE = on_permissive; S: Mysql> SET @@GLOBAL.GTID_MODE = on_permissive; #步骤 5 在M、S上检查变量ONGOING_ANONYMOUS_TRANSACTION_COUNT,需要等到此变量为0 Mysql> SHOW STATUS LIKE 'ONGOING_ANONYMOUS_TRANSACTION_COUNT'; Mysql> SHOW STATUS LIKE 'ONGOING_ANONYMOUS_TRANSACTION_COUNT'; #步骤 6 确保所有的匿名事务(非GTID事务)已经被完全复制到所有的server上。 M:show master status; S:show slave status\G #步骤 7 在每个mysql实例上,设置GTID_MODE为on M: mysql> SET @@GLOBAL.GTID_MODE = ON; S: mysql> SET @@GLOBAL.GTID_MODE = ON; #步骤 8 修改master_auto_position=1 stop slave;change master to master_auto_position=1;start slave; #步骤9 主节点创建一个库,查看slave节点的同步状态 mysql> create database test; Query OK, 1 row affected (0.00 sec) mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000006 Position: 342 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1 1 row in set (0.00 sec) 从节点的同步状态 mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for source to send event Master_Host: 10.0.0.218 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000006 Read_Master_Log_Pos: 342 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 558 Relay_Master_Log_File: mysql-bin.000006 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 342 Relay_Log_Space: 762 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 2183306 Master_UUID: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 Master_Info_File: mysql.slave_master_info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1 Executed_Gtid_Set: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1 Auto_Position: 1 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: Master_public_key_path: Get_master_public_key: 0 Network_Namespace: 1 row in set, 1 warning (0.00 sec) #步骤 10 修改每个mysql实例的配置文件my.cnf上, 增加 gtid-mode=ON enforce_gtid_consistency=on ``` ## 2.3 基于GTID的主从复制 ### 2.3.1 机器列表 | ip | 端口 | 角色 | 版本 | | ---------- | ---- | ------ | ------ | | 10.0.0.218 | 3306 | master | 8.0.36 | | 10.0.0.217 | 3306 | slave | 8.0.36 | ### 2.1.2 初始环境准备 ```sql #从库(db02)基于实验1的环境,将db02的环境销毁 stop slave; reset slave all; reset master; ``` ### 2.1.3 GTID重要参数注释 ```sql ##开启GTID必须参数## 1. gtid_mode: on 2. enforce_gtid_consistency: on ##其他参数## [master]>show global variables like '%gtid%'; 1、gtid_mode:是否开启GTID功能。 2、enforce_gtid_consistency:开启gtid的一些安全限制(介意开启)。 3、gtid_executed:全局和seeeion级别都可以用。用来保存已经执行过的GTIDs。 # 贴士:show master status\G;输出结果中的Executed_Gtid_Set和gitd_executed一致。reset master时,此值会被清空。 4、gtid_owned:全局和session级别都可用,全局表示所有服务器拥有GTIDs,session级别表示当前client拥有所有GTIDs。(此功能用的少) 5、gtid_purged:全局参数,设置在binlog中,已经purged的GTIDs,并且purged掉的GTIDs会包含到gtid_executed中。 6、gtid_next:这个时session级别的参数: [master]>show session variables like '%gtid_next%'; ``` ### 2.1.4 搭建步骤(基于GTID) ```sql 1. 在主库上,启用binlog并设置server_id。 mysql> select @@server_id; +-------------+ | @@server_id | +-------------+ | 2183306 | +-------------+ 1 row in set (0.00 sec) 2.在主库上,创建一个复制用户,从库使用此账户连接到主库 mysql> create user 'repl'@'10.0.0.%' identified WITH mysql_native_password BY '000000'; Query OK, 0 rows affected (0.00 sec) mysql> grant replication slave on *.* to 'repl'@'10.0.0.%'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) 3.在从库上,设置唯一的server_id选项(必须与主库不同) mysql> select @@server_id; +-------------+ | @@server_id | +-------------+ | 2173306 | +-------------+ 1 row in set (0.00 sec) 4.在从库上,通过远程连接从主库进行备份 root@db02:/data/download# mysqldump -usunrise -h10.0.0.218 -P3306 -p123456 --set-gtid-purged=on --single-transaction --default-character-set=utf8mb4 --all-databases --routines --events --triggers --master-data=2 > sunrise-test-gtid.sql 从另一个从库备份时,必须设置slave-dump 5.在从库上,恢复备份文件sunrise-test-gtid.sql mysql> reset master; mysql> stop slave; root@db02:/data/download# mysql -usunrise -h 10.0.0.217 -P3306 -p123456 < sunrise-test-gtid.sql 6.在从库上,配置主从复制 #导出的sql文件中带有gtid信息,导入的时候会直接执行,无需手动set #mysql> SET @@GLOBAL.GTID_PURGED='f9d7bc56-10da-11ed-803a-000c29b8dd2c:1-3'; mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.218',master_port=3306, MASTER_USER='repl', MASTER_PASSWORD='000000', master_auto_position=1; 7.开启主从复制(start slave mysql> start slave; Query OK, 0 rows affected, 1 warning (0.00 sec) 8.查看复制状态(show slave status) mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for source to send event Master_Host: 10.0.0.218 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000006 Read_Master_Log_Pos: 531 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 420 Relay_Master_Log_File: mysql-bin.000006 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 531 Relay_Log_Space: 624 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 2183306 Master_UUID: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6 Master_Info_File: mysql.slave_master_info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: 18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1-2 Auto_Position: 1 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: Master_public_key_path: Get_master_public_key: 0 Network_Namespace: 1 row in set, 1 warning (0.00 sec) ``` ### 2.1.5 GTID如何跳过事务冲突 (1)这个功能主要跳过事务,代替原来的set global sql_slave_skip_counter = 1。 (2)由于在这个GTID必须是连续的,正常情况同一个服务器产生的GTID是不会存在空缺的。 所以不能简单的skip掉一个事务,只能通过注入空事物的方法替换掉一个实际操作事务。 (3)注入空事物的方法: ```sql ##GTID跳过主键冲突等错误(少数错误) 1.stop slave 2.设置事务号从Executed_Gtid_Set事务号获取 SET @@SESSION.GTID_NEXT= '18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:N'; 3.执行空事物 BEGIN; COMMIT; 4.恢复自动事务 SET SESSION GTID_NEXT = AUTOMATIC; 5.START SLAVE; ##重置master方法跳过错误 STOP SLAVE; RESET MASTER; SET @@GLOBAL.GTID_PURGED ='18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1-3'; START SLAVE; ``` (4)这里的xxxxx:N 也就是你的slave sql thread报错的GTID,或者说是你想要跳过的GTID。 ## 2.4 复制环境配置宝典 配置复制环境这个事情,真的不是一套方案就能打天下的,就应用场景来说,从大的类别上可以 分为: ```sql 1.全新环境配置Replication:表示主从数据库服务均为全新,这种场景下的配置方案最为简单和灵活 2.现有环境配置Replication:表示主数据库服务已有数据,这种场景下配置就需要考虑多种因素。 为现有环境配置Replication,又可以细分为: (1)创建一台slave:当前已有master节点,需要配置slave节点,以创建Replication复制环境 (2)增加一台slave:当前已有M-S复制环境,需要再增加slave节点,以增强系统的整体负载能力。 在具体配置slave节点时,又可以细分为: (1)脱机方式创建:操作过程中,mysql服务可以停机 (2)联机方式创建:操作过程中,mysql服务不能中断运行 ``` ### 2.4.1 使用GTID的方式,把salve(空库)直接挂载master端: 1、启动以后最好不要立即执行事务,而是先change master上。 2、然后在执行事务,当然这不是必须的。 3、使用下面的sql切换slave到新的master。 ```sql stop slave; CHANGE MASTER TO MASTER_HOST='10.0.0.218', MASTER_PORT=3306, MASTER_USER='repl', MASTER_PASSWORD='000000', master_auto_position = 1; ``` ### 2.4.2 如果给已经运行的GTID的master端添加一个新的slave 有两种方法: - 方法一、适用于master也是新建不久的情况。 ```sql 1、如果你的master所有的binlog还在。可以选择类似于上面的方法,安装slave,直接change master to到master端。 2、原理是直接获取master所有的GTID并执行。 3、优点:简单方便。 4、缺点:如果binlog太多,数据完全同步需要时间较长,并且master一开始就启用了GTID。 ``` - 方法二、适用于拥有较大数据的情况。(推荐) ```sql 1、通过master或者其他slave的备份搭建新的slave。(看2.4.3) 2、原理:获取master的数据和这些数据对应的GTID范围,然后通过slave设置@@global.gtid_purged跳过备份包含的gtid。 3、优点:是可以避免第一种方法的不足。 4、缺点:相对来说有点复杂。 ``` ### 2.4.3 通过备份搭建新的slave:(2.4.2的扩展) 两种方法: - 方法一、mysqldump的方式: ```sql 1、在备份的时候指定--master-data=2(来保存binlog的文件号和位置的命令)。 2、使用mysqldump的命令在dump文件里可以看到下面两个信息: SET @@SESSION.SQL_LOG_BIN=0; SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '18e2ab9d-fc8e-11ee-bfbe-00163e28bcd6:1-2'; 3、将备份还原到slave后,使用change master to命令挂载master端。 ``` 注意:在mysql5.6.9以后的命令才支持这个功能。 - 方法二、percona Xtrabackup ```sql 1、Xtrabackup_binlog_info文件中,包含global.gtid_purged='XXXXXX:XXXX'的信息。 2、然后到slave去手工的 SET @@GLOBAL.GTID_PURGED='XXXXXX:XXXX'。 3、恢复备份,开启change master to 命令。 CHANGE MASTER TO MASTER_HOST='10.0.0.218', MASTER_PORT=3306, MASTER_USER='repl', MASTER_PASSWORD='000000', master_auto_position = 1; ``` 注意:如果系统运行了很久,无法找到GTID的编号了,可以通过上面的方式进行查找。 ## 2.5 批量跳过多个GTID的脚本 ```python import os script_file = "./skip_file.sql" def write_script(script_content): file_handle = open(script_file, 'a+') file_handle.writelines(script_content + "\n") file_handle.close() def delete_script_file(): if os.path.exists(script_file): os.remove(script_file) def get_skip_script_list(master_uuid, start_tran_id, end_tran_id): script_list = [] current_tran_id = start_tran_id while current_tran_id <= end_tran_id: current_script = """ SET @@SESSION.GTID_NEXT= '{master_uuid}:{tran_id}'; BEGIN; COMMIT;""".format( master_uuid=master_uuid, tran_id=current_tran_id ) current_tran_id = current_tran_id + 1 script_list.append(current_script) script_list.append("SET SESSION GTID_NEXT = AUTOMATIC;") return script_list def main(): master_uuid = "e0a86c29-f20d-11e8-93c2-04b0e7954a65" start_tran_id = 104935 end_tran_id = 105007 script_list = get_skip_script_list(master_uuid, start_tran_id, end_tran_id) write_script("\n".join(script_list)) if __name__ == '__main__': main() ``` # 三、复制过滤规则 MySQL提供的过滤规则有多种粒度,下面我们来近距离看看—replication-*参数的威力。 ## 3.1 库级别过滤规则 ```sql 主库: --binlog-do-db --binlog-ignore-db 从库: --replication-do-db --replication-ignore-db 并不是过滤指定数据库的操作,而是过滤当前默认数据库所做的操作。 例如:在基于语句格式记录日志的情况下,当前master在a库下执行了操作use a,然后分别修改了a库下的表以及b库下表,而后该操作日志被复制到slave节点,slave端设置忽略a库下的操作(replication-ignore-db=a),那么,a库下对象的操作肯定被忽略了,不会在slave执行。只有当master端,修改a时则use a,修改b时则use b,没有跨库操作,才不会出现误过滤的情形。 ``` 数据库级过滤规则,流程如下: 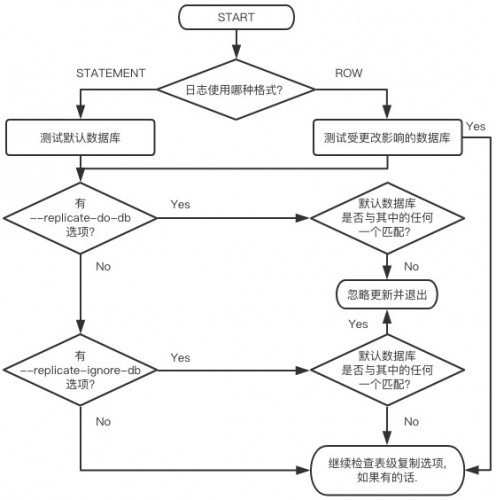 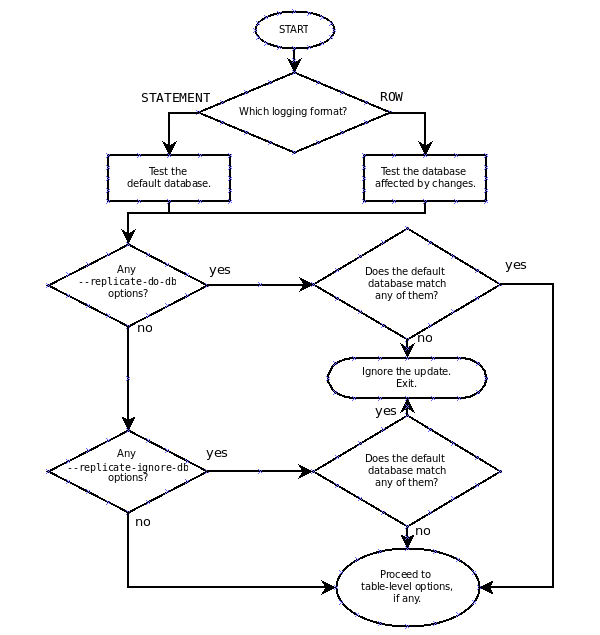 ## 3.2 表级别过滤规则 ```sql 从库: --replication-do-table #复制的表 --replication-ignore-table #复制忽略的表 --replication-wild-do-table #复制指定的A.b%(支持通配符) --replication-wild-ignore-table #忽略指定的A.b%(支持通配符) ``` 整体流程: 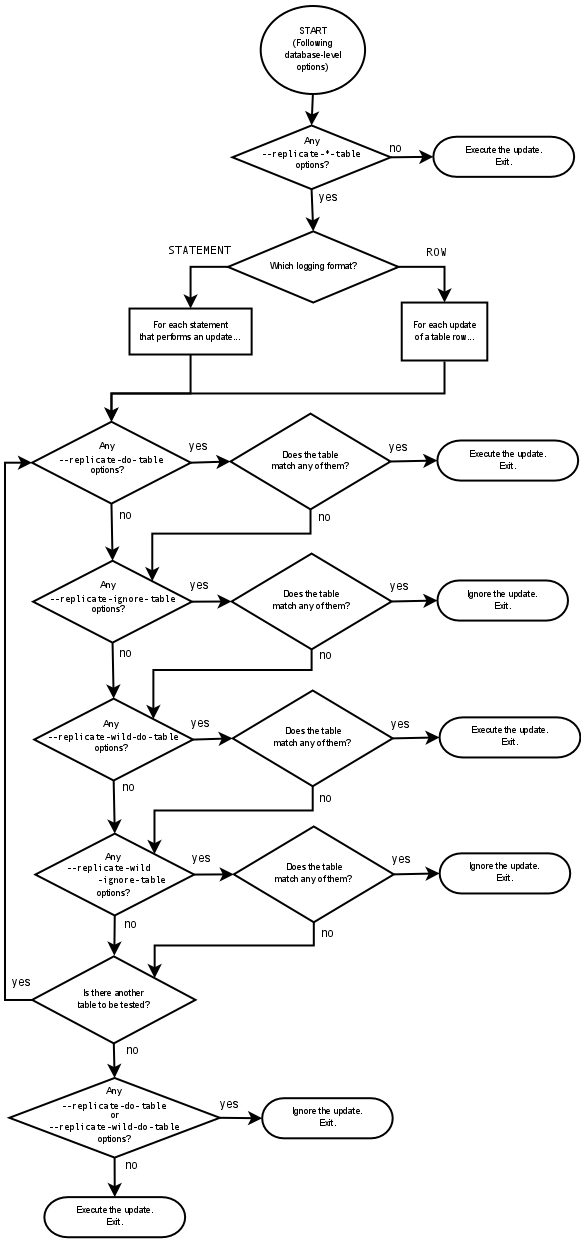 不同场景下复制过滤规则的应用 | 条件 | 结果 | | ---------------------------- | ------------------------------------------------------------ | | 没有任务--replication-*参数 | slave端执行所有接收到的事件 | | 指定了--replication-*-db参数 | 只执行(或忽略)指定数据库事件 | | 指定了--replication-*-db参数 | 只执行(或忽略)指定表的事件 | | 既有库级参数,也有表级参数 | slave节点首先执行(或忽略)指定数据库 的事件,而后再处理表级过滤选项,需要注 意日志记录格式对复制的影响 | 注意:对于- -replication-*这类参数,每个参数只能指定一个参数值,如果用户有多个过滤规则怎么 办呢?比如:slave节点希望能够过滤a,b,c三个库,针对这种情况,就需要指定3次— replication-ignore-db参数,并分别为其赋值。 ## 3.3 过滤规则的应用示例 ```sql 环境说明: 主库:10.0.0.218 从库:10.0.0.217 版本:8.0.36(5.6不支持动态配置,需要修改配置文件直接重启) 配置slave节点,添加过滤规则,过滤掉mysql库和test.t1表 操作步骤: 1.从节点,查看主从同步状态 show slave status\G 2.关闭同步 stop slave; 3.添加过滤策略 CHANGE REPLICATION FILTER replicate_wild_ignore_table = ('mysql.%','test.t1'); 4.主节点,新建表ldboy_test.repl_ignore_test,插入数据 use test create table t1 (id int); insert into t1 values (1); 5.从节点,开启复制 start slave; 6.从节点,查看主从复制状态 mysql> show slave status\G *************************** 1. row *************************** Replicate_Wild_Ignore_Table: mysql.%,test.t1 7.从节点,查看是否有表test.t1 use test; show tables; 8.从节点,修改配置文件,新增2行 replicate-wild-ignore-table=mysql.% replicate-wild-ignore-table=test.t1 ``` # 四、MySQL并行复制 历程: ```sql 1. MySQL 5.5版本:是单进程串行复制,通过sql_thread线程来恢复主库推送过来的binlog,这样会产生一个问题,主库有大量的写操作,从库就有可能出现延迟。 2. MySQL 5.6版本:slave的多线程复制是基于库(schema)的。设置slave_parallel_workers参数,开启基于库的多线程复制。默认是0不开启,最大并发为1024个线程。 3. MySQL 5.7的slave从库多线程复制是基于表的,实现是基于binlog组提交。官方称为enhanced multi-threaded slave(简称MTS)。 MTS本身就是:master基于组提交(group commit)来实现的并发事务分组,再由slave通过SQL thread将一个组提交内的事务分发到各worker线程,实现并行应用。 ``` binlog里增加last_committed标记 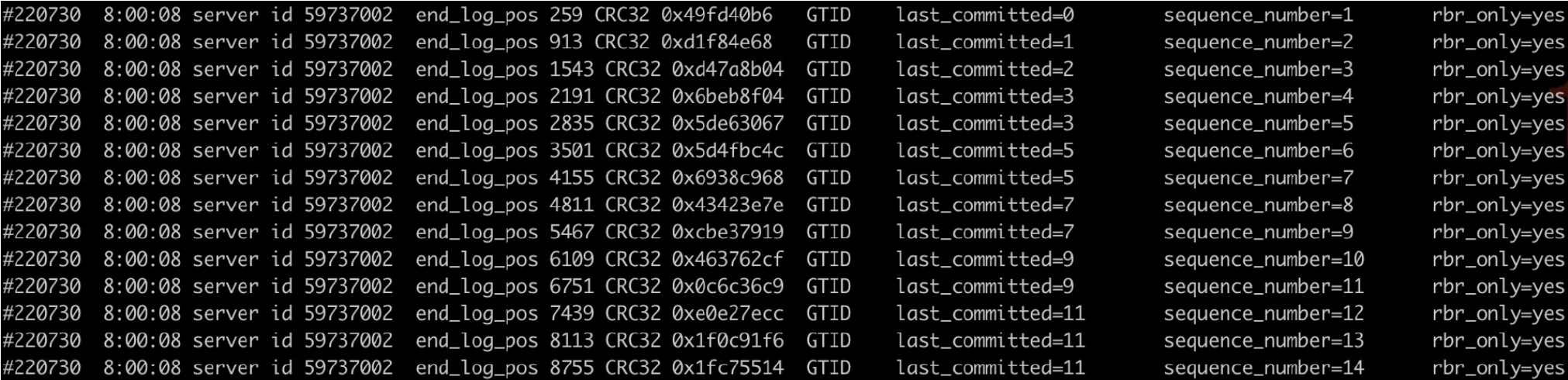 上图中last_committed=11的事务有3个,表示组提交时提交了3个事务,加入设置 slave_parallel_workers=5(并行复制线程数,根据cpu核数设置),那么这3个事务在slave上 通过5个线程进行恢复 ```sql 通过设置slave_parallel_type = logical clock,默认是DATABASE ``` 下面来具体看看MySQL 8.0.36中的并行复制究竟是如何实现的?(MySQL 5.7是一样的) > order commit (group commit) -> logical clock ->> MTS ## 4.1 Master ### 4.1.1 组提交(group commit) ```sql 定义: 通过对事务进行分组,优化减少了生成二进制日志所需的操作数。当事务同时提交时,它们将在单个操作中写入到二进制日志中。如果事务能同时提交成功,那么它们就不会共享任何锁,这意味着它们没有冲突,因此可以在Slave上并行执行。所以通过在主机上的二进制日志中添加组提交信息,这些Slave可以并行地安全地运行事务。 问题: 在生成的Binlog内容中该如何告诉Slave哪些事务是可以并行复制的? 参数: 为了兼容MySQL 5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有: DATABASE(默认值,基于库的并行复制方式) LOGICAL_CLOCK(基于组提交的并行复制方式) ``` ### 4.1.2 支持并行复制的GTID ```sql 1. 未开启gtid: Anonymous_Gtid的二进制日志event类型:存着组提交的信息 2. 开启gtid: 组提交信息就记录在非匿名GTID事件中 - PREVIOUS_GTIDS_LOG_EVENT 用于表示上一个binlog最后一个gitd的位置,每个binlog只有一个,当没有开启GTID时此事件为空。 - GTID_LOG_EVENT - 当开启GTID时,每一个操作语句(DML/DDL)执行前就会添加一个GTID事件,记录当前全局事务ID。 - 同时在MySQL 5.7版本中,组提交信息也存放在GTID事件中,有两个关键字段last_committed,sequence_number就是用来标识组提交信息的。 - 全局计数器(global counter) 在InnoDB中有一个全局计数器(global counter),在每一次存储引擎提交之前,计数器值就 会增加。在事务进入prepare阶段之前,全局计数器的当前值会被储存在事务中,这个值称为此事务的commit-parent(也就是last_committed) ``` ## 4.2 Slave ### 4.2.1 LOGICAL_CLOCK LOGICAL_CLOCK(由order commit实现),实现的group commit目的。 ```sql 上述的last_committed和sequence_number代表的就是所谓的LOGICAL_CLOCK。 - last_committed表示事务提交时上次事务提交的编号.事务在进入prepare阶段时会将上次事务的sequence_number记录为自己的last_committed,如果事务具有相同的last_committed,表示这些事务都在一组内,可以进行并行的回放。例如上述last_committed为0的事务有6个,表示组提交时提交了6个事务,而这6个事务在slave是可以进行并行回放的。 - 而sequence_number是顺序增长的,每个事务对应一个序列号,当事务完成committed时便会得到这个sequence_number。 - 这两个值的有效作用域都在文件内,只要换一个binlog文件(flush binary logs),这两个值就都会从0开始计数 ``` ## 4.3 MySQL如何将这些事务分组? ### 4.3.1 事务两阶段提交 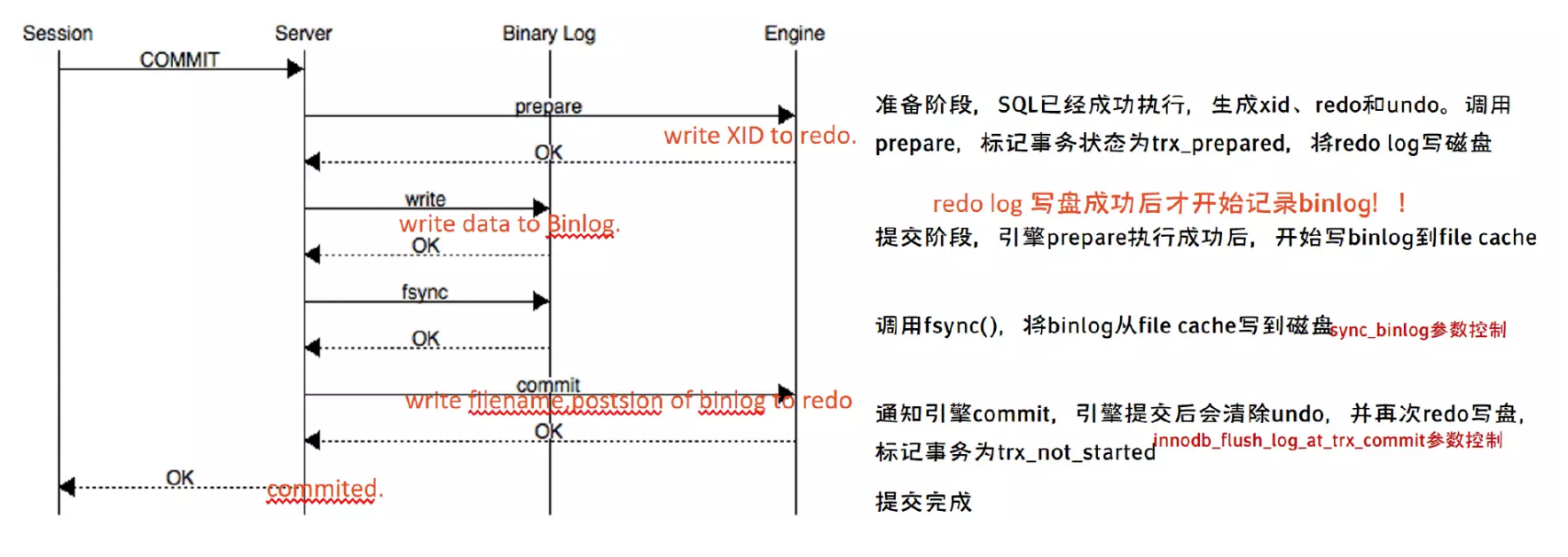 ### 4.3.2 order commit 逻辑图: 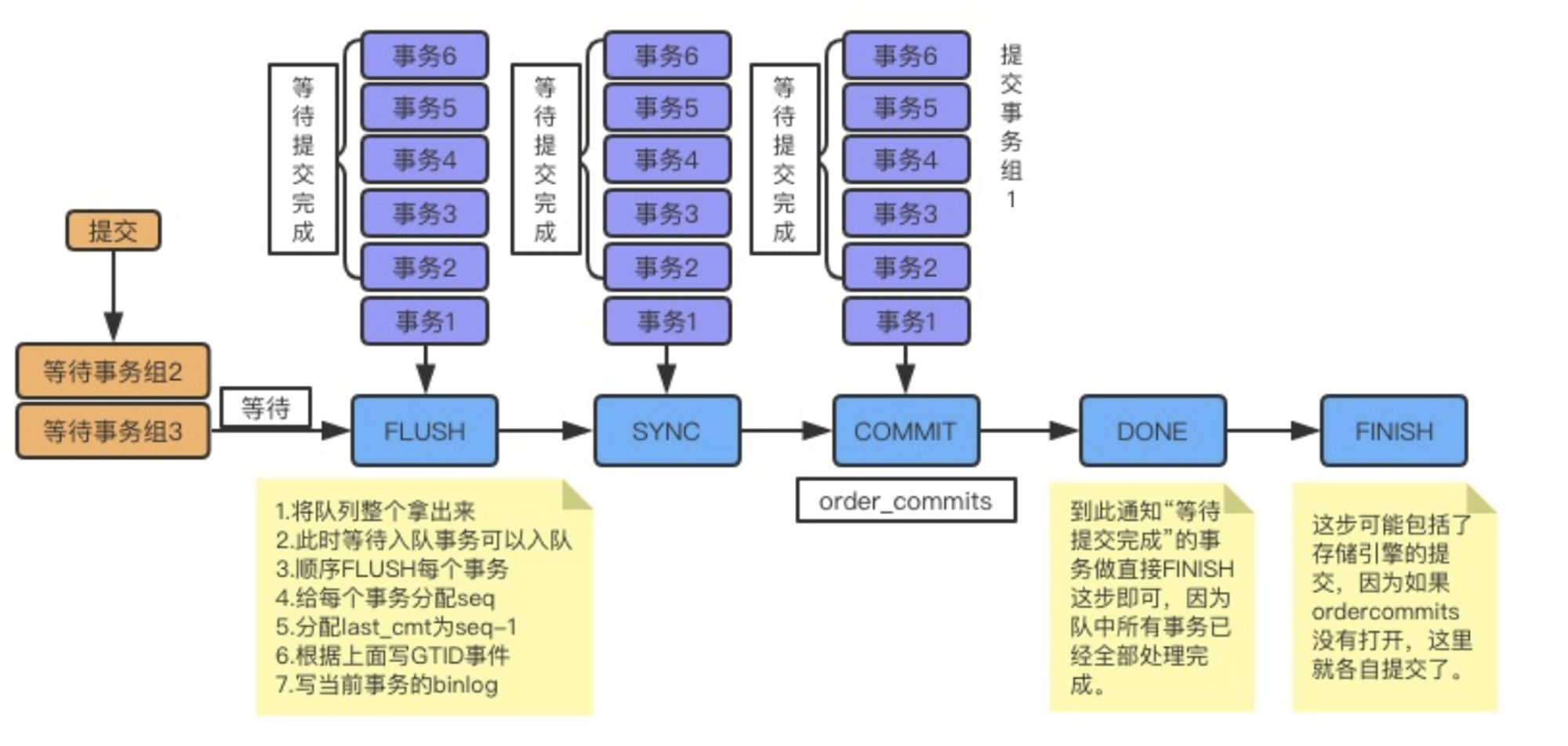 ```sql 提交有三个步骤,包括FLUSH、SYNC及COMMIT,相应地也有三个队列。 1. 首先要加入的是FLUSH队列: - 在同一时刻,只能有一个组在做FLUSH。 - 做FLUSH的过程中,有一些重要的事务需要去做,如下: - 要保证顺序必须是提交加入到队列的顺序。 - 如果有新的事务提交,此时队列为空,则可以加入到FLUSH队列中。不过,因为此时FLUSH临界区正在被占用,所以新事务组必须要等待。 - 给每个事务分配sequence_number,如果是第一个事务,则将这个组的last_committed设置为sequence_number-1. - 将带着last_committed与sequence_number的GTID事件FLUSH到Binlog文件中。 - 将当前事务所产生的Binlog内容FLUSH到Binlog文件中。 2. SYNC队列 如果SYNC的临界区是空的,则直接做SYNC操作,而如果已经有事务组在做,则必须要等待。 3. COMMIT队列 到COMMIT时,实际做的是存储引擎提交,参数binlog_order_commits会影响提交行为。 - 如果设置为ON,那么此时提交就变为串行操作了,就以队列的顺序为提交顺序。 - 如果设置为OFF,提交就不会在这里进行,而会在每个事务(包括队长和队员)做finish_commit(FINISH)时各自做存储引擎的提交操作。 - 组内每个事务做finish_commit是在队长完成COMMIT工序之后进行,到步骤DONE时,便会唤醒每个等待提交完成的事务,告诉他们可以继续了,那么每个事务就会去做finish_commit。 - 而后,队长自己再去做finish_commit。这样,一个组的事务就都按部就班地提交完成了。 ``` ## 4.4 从库多线程复制分发原理 ### 4.4.1 基于last_committed分发 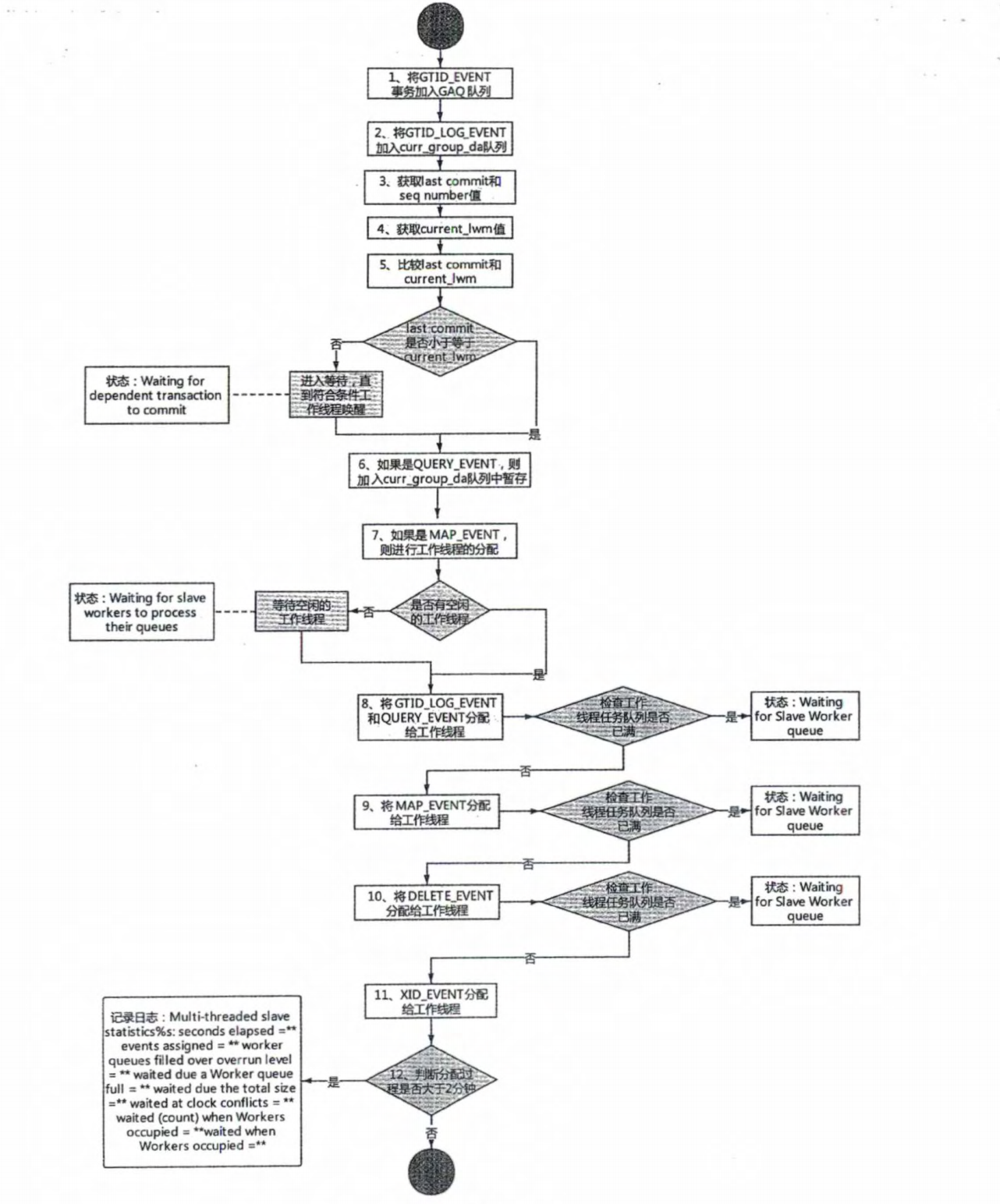 ```sql 1. sql thread拿到一个新事务,取出该事务的last_committed及sequence_number值。 2. 将已经执行的事务的sequence_number的最小值(low water mark,lwm),与取出事务的last_committed值进行比较。(本组的sequence_number最小值肯定大于last_committed) 3. 如果取出事务的last_committed小于已经执行的sequence(lwm),说明取出事务与当前执行组为同组,无需等待,直接由sql thread 分配事务到空闲worker线程。 4. SQL线程通过统计,找到一个空闲的worker线程,如果没有空闲,则SQL线程转入等待状态,直到找到一个空闲worker线程为止。将当前事务打包,交给选定的worker,之后worker线程会去APPLY这个事务,此时的SQL线程就会处理下一个事务。 5. 如果取出事务的last_committed大于等于已经执行的lwm,说明取出事务与当前不为一组,取出事务为新组,需等待。 6. 等待lwm增长,当已经执行的sequence(lwm)等于取出事务的last_committed时,说明前一组已经执行完成。sql thread 开始将取出事务的last_committed组事务分发给worker线程进行并行apply。 ``` ## 4.5 并行复制配置与调优 ```sql 1. master_info_repository 开启MTS功能后,务必将参数master_info_repostitory设置为TABLE,这样性能可以有50%~80%的提升。这是因为并行复制开启后对于master.info这个文件的更新将会大幅提升,资源的竞争也会变大。 2. slave_parallel_workers 若将slave_parallel_workers设置为0,则MySQL 5.7退化为原单线程复制,但将slave_parallel_workers设置为1,则SQL线程功能转化为coordinator线程,但是只有1个worker线程进行回放,也是单线程复制。然而,这两种性能却又有一些的区别,因为多了一次coordinator 线程的转发,因此slave_parallel_workers=1的性能反而比0还要差,测试下还有20%左右的性能下降, 3. slave_preserve_commit_order 当开启slave_preserve_commit_order参数后,slave_parallel_type只能是LOGICAL_CLOCK,如果你有使用级联复制,那LOGICAL_CLOCK可能会使离master越远的slave并行性越差。 ###要开启enhanced multi-threaded slave其实很简单,只需根据如下设置: # slave; slave-parallel-type=LOGICAL_CLOCK slave-parallel-workers=16 slave_pending_jobs_size_max = 2147483648 slave_preserve_commit_order=1 master_info_repository=TABLE relay_log_info_repository=TABLE relay_log_recovery=ON ########################################################## mysql> SHOW VARIABLES LIKE 'slave_parallel_workers'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | slave_parallel_workers | 16 | +------------------------+-------+ 1 row in set (0.01 sec) mysql> SHOW VARIABLES LIKE 'master_info_repository'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | master_info_repository | TABLE | +------------------------+-------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'slave_preserve_commit_order'; +-----------------------------+-------+ | Variable_name | Value | +-----------------------------+-------+ | slave_preserve_commit_order | ON | +-----------------------------+-------+ 1 row in set (0.01 sec) ``` # 五、MySQL-异步,半同步,增强半同步复制 > 核心目的是为了在宕机发生主从切换后,业务数据保持一致性 ```sql MySQL通过复制(Replication)实现存储系统的高可用。 目前,MySQL支持的复制方式有: 1. 异步复制(Asynchronous Replication):性能最好。但是主备之间数据不一致的概率很大。 2. 全同步复制(组复制(Group Replication)):在主节点上写入的数据,在从服务器上都同步完了以后才会给客户端返回成功消息,是基于Paxos算法实现分布式数据复制的强一致性。相比半同步复制,Group Replication的数据一致性和系统可用性更高。相比主从返回信息的时间比较慢。 3. 半同步复制(Semi-synchronous Replication):介于全同步复制和异步复制的一种,相比异步复制,半同步复制牺牲了一定的性能,提升了主备之间数据的一致性(有一些情况还是会出现主备数据不一致)。 ``` ## 5.1.异步复制 ```sql Mysql5.5之前: 如果主库和从库的数据有一定的延迟 - 主库写入一个事务并提交成功,不知道slave是否已经收到或者处理binlog,主库宕机 - 高可用从库-->主库,由于从库没有这个binlog,损失这个事务,从而造成主从不一致。 - 速度最快,性能最高,宕机如果主从有延时,有丢失数据风险 问题: 一旦Master 崩溃,发送主从切换将会发送数据不一致性的风险。 ``` - 异步复制时间轴 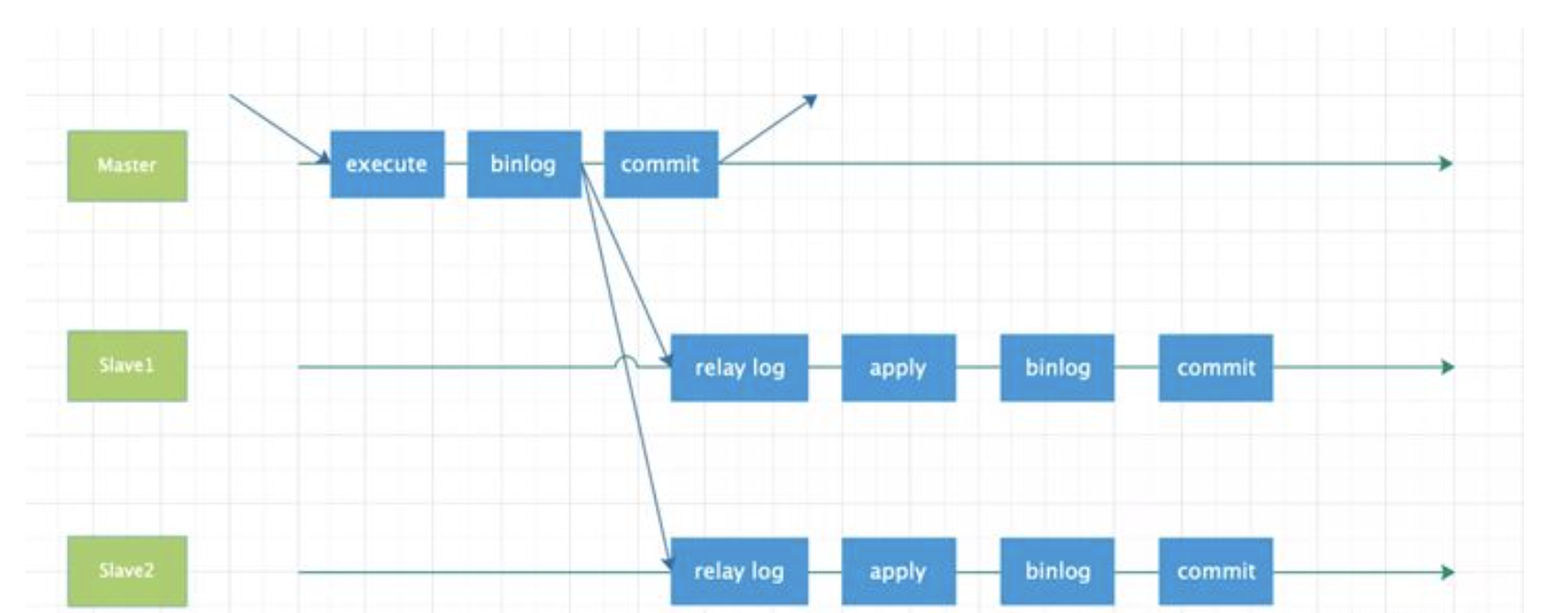 ## 5.2 半同步复制 ### 5.2.1.传统半同步复制 - 简介 ```sql #改进: 1.主库写入binlog 2.提交事务并commit 3.等待至少一个从节点确认收到所有Event并写入relay log刷盘 4.返回ACK给主库 5.M继续处理用户的事务 #条件 1.Master处理事务过程中,提交完事务后,必须等至少一个Slave将收到的binlog写入relay log返回ack 才能继续执行处理用户的事务。(默认10s) 2.ACK超时则变为异步复制(rpl_semi_sync_master_timeout),追上恢复半同步 #配置: rpl_semi_sync_master_wait_point = AFTER_COMMIT (什么时间点开始等ack) 【这里MySQL 5.5并没有这个配置,MySQL5.7 为了解决半同步的问题而设置的,下文有讲解】 rpl_semi_sync_master_wait_for_slave_count = 1 (最低必须收到多少个slave的ack) rpl_semi_sync_master_timeout = 100(等待ack的超时时间) #问题: - 一旦Ack超时,将退化为异步复制模式,那么异步复制的问题也将发送 - 性能下降,增多至少一个RTT时间 数据不一致性问题,因为等待ACK的点是Commit之后,此时Master已经完成数据变更,用户已经可以看到最新数据,当Binlog还未同步到Slave时,发生主从切换,那么此时从库是没有这个最新数据的,用户又看到老数据。 ``` 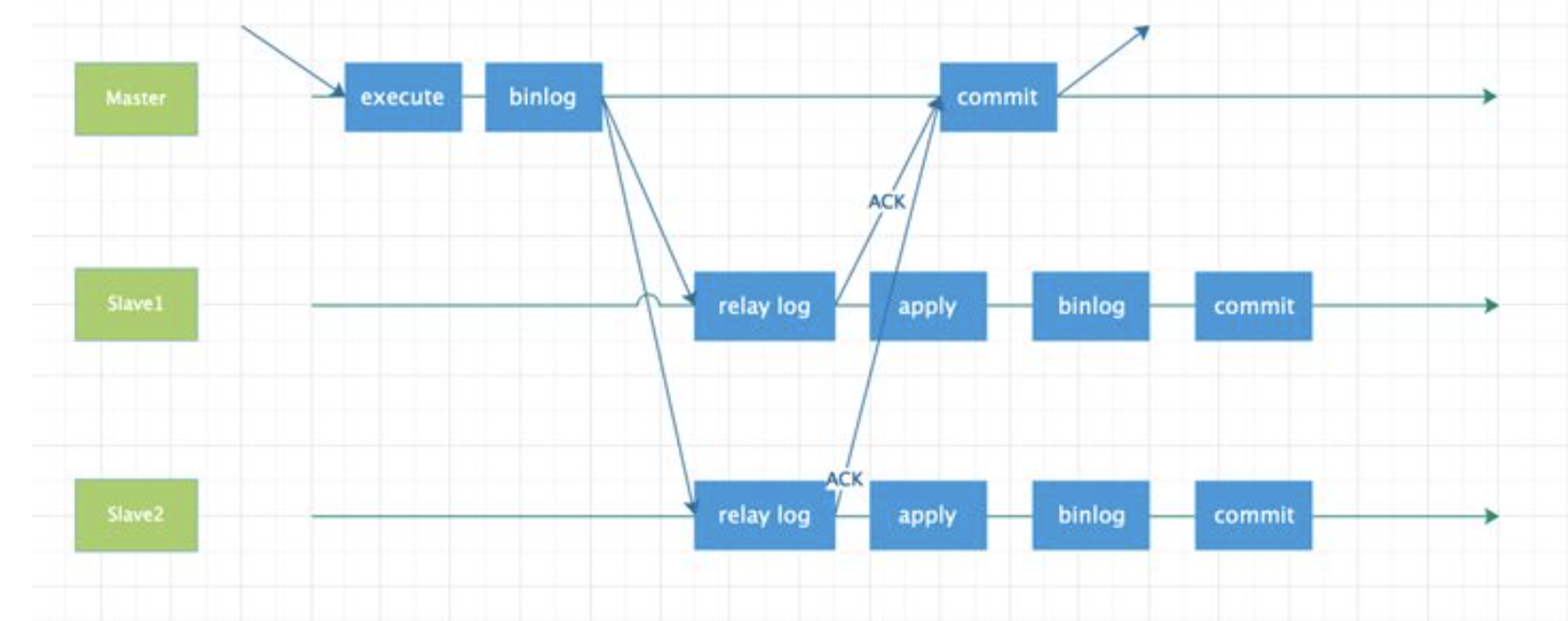 ### 5.2.2.增强半同步复制(Loss-Less无损复制) ```sql 改进:在ACK等待时间做了调整 1.主库写入binlog 2.传递slave刷盘到relay log 3.M等待至少一个从库的ACK返回 4.主库提交事务并返回commit OK 5.客户端收到变化 配置: rpl_semi_sync_master_wait_point= AFTER_SYNC; # 问题: - 一旦Ack超时,将退化为异步复制模式,那么异步复制的问题也将发送 - 性能下降,增多至少一个RTT时间 - 如果超时时间设置很大,然后因为网络原来长时间收不到ACK,用户提交是被挂起的,可用性收到打击(半同步一样存在) 总结: 1.两个半同步:保证了事务提交成功后,至少两份日志,master binlog和slave的relay log 2.半同步复制很大程度上取决于主从库之间的网络情况,往返时延RTT越小决定了从库的实时性 越好。通俗地说,主从库之间的网络越快,从库约实时。 3.版本改进 5.6版本 - dump thread:传送binlog给slave.等待slave ack,成为性能瓶颈,高并发业务,影响数据库TPS 5.7.版本 - 半同步复制 独立出一个ack collector thread ,专门用于接收slave 的反馈信息。 #知识点 往返时延RTT(Round-Trip Time)在计算机网络中是一个重要的性能指标,它表示从发送端发送数据开始到发送端接收到接收端的确认,总共经历的时长(TCP三次握手的前两次握手)。 ``` ### 5.2.3 配置半同步复制 ```sql #使用条件 1.查看已安装的插件 mysql> show plugins; #查看已安装的插件 mysql> show variables like 'plugin_dir'; #查看插件的目录 +---------------+-------------------------------+ | Variable_name | Value | +---------------+-------------------------------+ | plugin_dir | /opt/mysql-8.0.36/lib/plugin/ | +---------------+-------------------------------+ 1 row in set (0.00 sec) root@db01:~# ls /opt/mysql-8.0.36/lib/plugin/ | grep 'semi' semisync_master.so <--5.7有这两个 semisync_replica.so semisync_slave.so <--5.7有这两个 semisync_source.so 2.安装插件,主库和从库都要启用半同步复制才会进行半同步复制功能 -- 因用户需执行INSTALL PLUGIN, SET GLOBAL, STOP SLAVE和START SLAVE操作,所以用户需有SUPER权限。 主: mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; 从: mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; 3.查看是否加载成功 mysql> show plugins; mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE '%semi%'; 主库: mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE '%semi%'; +----------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +----------------------+---------------+ | rpl_semi_sync_master | ACTIVE | +----------------------+---------------+ 从库: mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE '%semi%'; +---------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +---------------------+---------------+ | rpl_semi_sync_slave | ACTIVE | +---------------------+---------------+ 1 row in set (0.00 sec) 4.启动半同步复制 # 参数说明: -- rpl_semi_sync_master_enabled:用于控制是否在master节点启用半同步复制,默认为1即启用状态; -- rpl_semi_sync_master_timeout:用于指定master节点等待slave的超时时间,单位毫秒,默认是10000即10s -- rpl_semi_sync_slave_enabled:用于控制是否在slave节点启用半同步复制,默认为1即启用状态; -- rpl_semi_sync_master_wait_for_slave_count:设置主需要等待多少个slave应答,才能返回给客户端,默认为1。 主: mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1; 从: mysql> SET GLOBAL rpl_semi_sync_slave_enabled = 1; 5.重启IO线程 mysql> STOP SLAVE IO_THREAD; mysql> START SLAVE IO_THREAD; #重启slave的io线程后,slave会在master上注册为半同步复制的slave角色。 6. 查看半同步是否在运行 主: mysql> show status like 'Rpl_semi_sync_master_status'; +-----------------------------+-------+ | Variable_name | Value | +-----------------------------+-------+ | Rpl_semi_sync_master_status | ON | +-----------------------------+-------+ 1 row in set (0.00 sec) 从: mysql> show status like 'Rpl_semi_sync_slave_status'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | Rpl_semi_sync_slave_status | ON | +----------------------------+-------+ 1 row in set (0.00 sec) ## SHOW STATUS LIKE 'Rpl_semi_sync_%'; ``` ### 5.2.4 监控半同步复制环境 ```sql #slave: Rpl_semi_sync_slave_status #标识slave是否启用了半同步复制 #master (1) Rpl_semi_sync_master_clients #当前半同步slave的个数 (2) Rpl_semi_sync_master_status #master是否启用半同步 (3) Rpl_semi_sync_master_no_tx #当前未成功发送到slave的事务数量 (4) Rpl_semi_sync_master_yes_tx #当前已成功发送到slave的事务数量 ```
李延召
2024年4月23日 11:12
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码